 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATR-UMMIM: A Benchmark Dataset for UAV-Based Multimodal Image Registration under Complex Imaging Conditions
Jul 28, 2025Multimodal fusion has become a key enabler for UAV-based object detection, as each modality provides complementary cues for robust feature extraction. However, due to significant differences in resolution, field of view, and sensing characteristics across modalities, accurate registration is a prerequisite before fusion. Despite its importance, there is currently no publicly available benchmark specifically designed for multimodal registration in UAV-based aerial scenarios, which severely limits the development and evaluation of advanced registration methods under real-world conditions. To bridge this gap, we present ATR-UMMIM, the first benchmark dataset specifically tailored for multimodal image registration in UAV-based applications. This dataset includes 7,969 triplets of raw visible, infrared, and precisely registered visible images captured covers diverse scenarios including flight altitudes from 80m to 300m, camera angles from 0{\deg} to 75{\deg}, and all-day, all-year temporal variations under rich weather and illumination conditions. To ensure high registration quality, we design a semi-automated annotation pipeline to introduce reliable pixel-level ground truth to each triplet. In addition, each triplet is annotated with six imaging condition attributes, enabling benchmarking of registration robustness under real-world deployment settings. To further support downstream tasks, we provide object-level annotations on all registered images, covering 11 object categories with 77,753 visible and 78,409 infrared bounding boxes. We believe ATR-UMMIM will serve as a foundational benchmark for advancing multimodal registration, fusion, and perception in real-world UAV scenarios. The datatset can be download from https://github.com/supercpy/ATR-UMMIM
Nearshore Underwater Target Detection Meets UAV-borne Hyperspectral Remote Sensing: A Novel Hybrid-level Contrastive Learning Framework and Benchmark Dataset
Feb 20, 2025UAV-borne hyperspectral remote sensing has emerged as a promising approach for underwater target detection (UTD). However, its effectiveness is hindered by spectral distortions in nearshore environments, which compromise the accuracy of traditional hyperspectral UTD (HUTD) methods that rely on bathymetric model. These distortions lead to significant uncertainty in target and background spectra, challenging the detection process. To address this, we propose the Hyperspectral Underwater Contrastive Learning Network (HUCLNet), a novel framework that integrates contrastive learning with a self-paced learning paradigm for robust HUTD in nearshore regions. HUCLNet extracts discriminative features from distorted hyperspectral data through contrastive learning, while the self-paced learning strategy selectively prioritizes the most informative samples. Additionally, a reliability-guided clustering strategy enhances the robustness of learned representations.To evaluate the method effectiveness, we conduct a novel nearshore HUTD benchmark dataset, ATR2-HUTD, covering three diverse scenarios with varying water types and turbidity, and target types. Extensive experiments demonstrate that HUCLNet significantly outperforms state-of-the-art methods. The dataset and code will be publicly available at: https://github.com/qjh1996/HUTD
Beyond Sharing Weights in Decoupling Feature Learning Network for UAV RGB-Infrared Vehicle Re-Identification
Oct 12, 2023Owing to the capacity of performing full-time target search, cross-modality vehicle re-identification (Re-ID) based on unmanned aerial vehicle (UAV) is gaining more attention in both video surveillance and public security. However, this promising and innovative research has not been studied sufficiently due to the data inadequacy issue. Meanwhile, the cross-modality discrepancy and orientation discrepancy challenges further aggravate the difficulty of this task. To this end, we pioneer a cross-modality vehicle Re-ID benchmark named UAV Cross-Modality Vehicle Re-ID (UCM-VeID), containing 753 identities with 16015 RGB and 13913 infrared images. Moreover, to meet cross-modality discrepancy and orientation discrepancy challenges, we present a hybrid weights decoupling network (HWDNet) to learn the shared discriminative orientation-invariant features. For the first challenge, we proposed a hybrid weights siamese network with a well-designed weight restrainer and its corresponding objective function to learn both modality-specific and modality shared information. In terms of the second challenge, three effective decoupling structures with two pretext tasks are investigated to learn orientation-invariant feature. Comprehensive experiments are carried out to validate the effectiveness of the proposed method. The dataset and codes will be released at https://github.com/moonstarL/UAV-CM-VeID.
Masked Spatial-Spectral Autoencoders Are Excellent Hyperspectral Defenders
Jul 16, 2022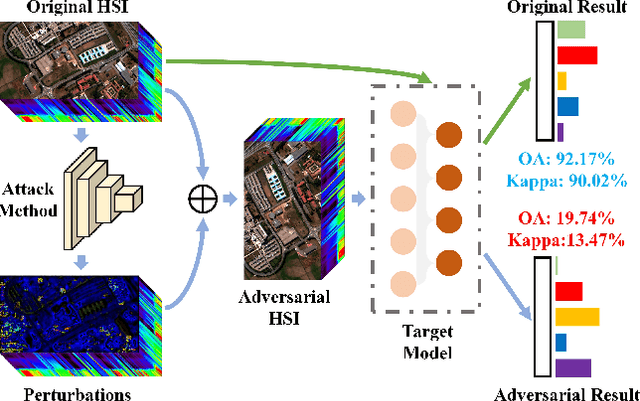
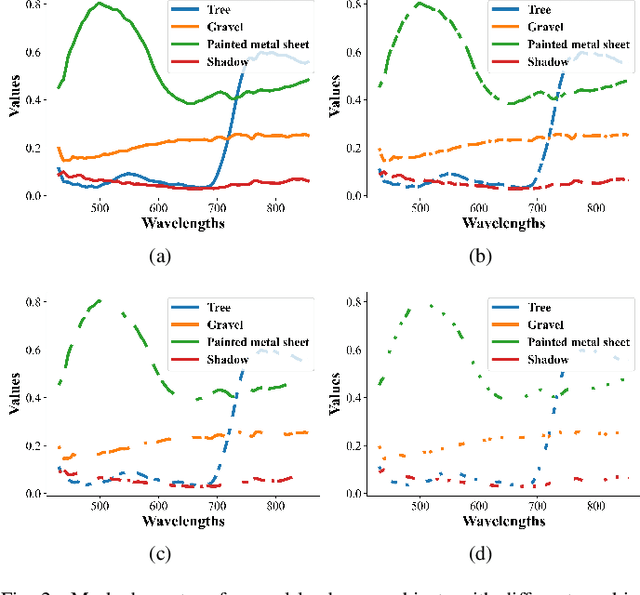
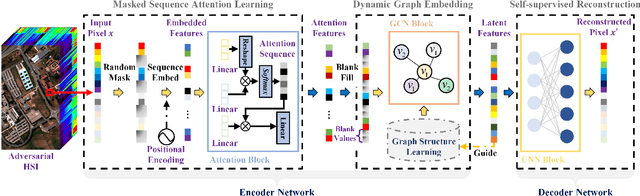
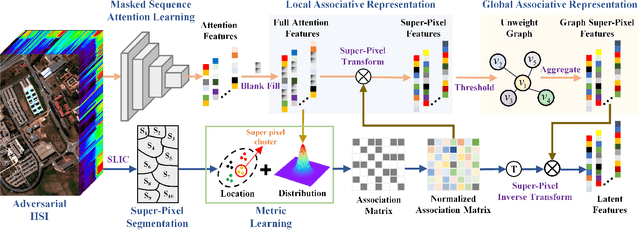
Deep learning methodology contributes a lot to the development of hyperspectral image (HSI) analysis community. However, it also makes HSI analysis systems vulnerable to adversarial attacks. To this end, we propose a masked spatial-spectral autoencoder (MSSA) in this paper under self-supervised learning theory, for enhancing the robustness of HSI analysis systems. First, a masked sequence attention learning module is conducted to promote the inherent robustness of HSI analysis systems along spectral channel. Then, we develop a graph convolutional network with learnable graph structure to establish global pixel-wise combinations.In this way, the attack effect would be dispersed by all the related pixels among each combination, and a better defense performance is achievable in spatial aspect.Finally, to improve the defense transferability and address the problem of limited labelled samples, MSSA employs spectra reconstruction as a pretext task and fits the datasets in a self-supervised manner.Comprehensive experiments over three benchmarks verify the effectiveness of MSSA in comparison with the state-of-the-art hyperspectral classification methods and representative adversarial defense strategies.
Transferable Physical Attack against Object Detection with Separable Attention
May 19, 2022
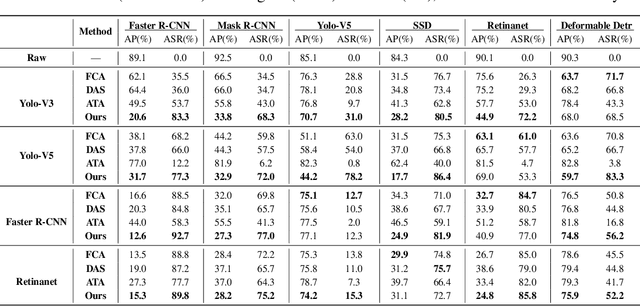
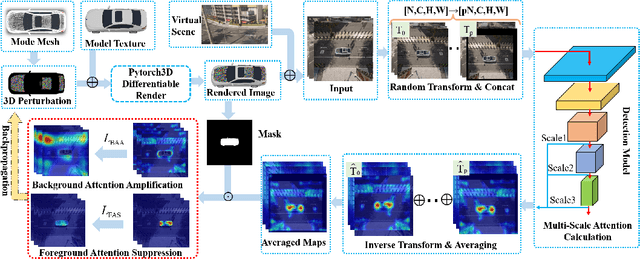
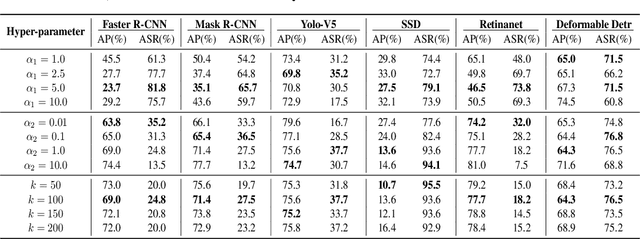
Transferable adversarial attack is always in the spotlight since deep learning models have been demonstrated to be vulnerable to adversarial samples. However, existing physical attack methods do not pay enough attention on transferability to unseen models, thus leading to the poor performance of black-box attack.In this paper, we put forward a novel method of generating physically realizable adversarial camouflage to achieve transferable attack against detection models. More specifically, we first introduce multi-scale attention maps based on detection models to capture features of objects with various resolutions. Meanwhile, we adopt a sequence of composite transformations to obtain the averaged attention maps, which could curb model-specific noise in the attention and thus further boost transferability. Unlike the general visualization interpretation methods where model attention should be put on the foreground object as much as possible, we carry out attack on separable attention from the opposite perspective, i.e. suppressing attention of the foreground and enhancing that of the background. Consequently, transferable adversarial camouflage could be yielded efficiently with our novel attention-based loss function. Extensive comparison experiments verify the superiority of our method to state-of-the-art methods.