 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Powered Conversational Agent Delivering Problem-Solving Therapy (PST) for Family Caregivers: Enhancing Empathy and Therapeutic Alliance Using In-Context Learning
Jun 13, 2025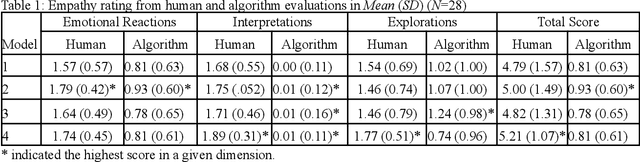
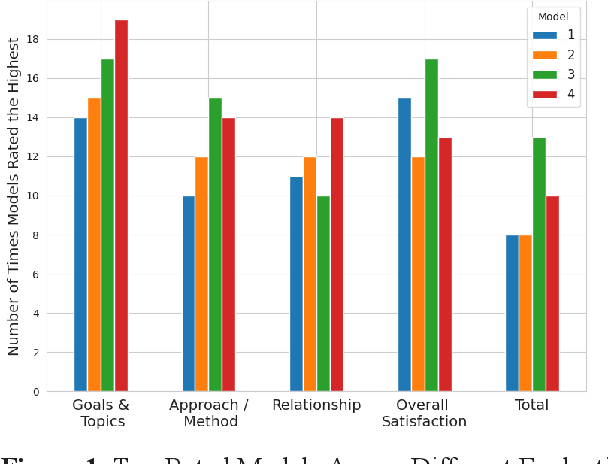
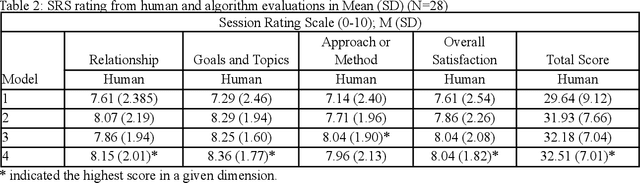
Family caregivers often face substantial mental health challenges due to their multifaceted roles and limited resources. This study explored the potential of a large language model (LLM)-powered conversational agent to deliver evidence-based mental health support for caregivers, specifically Problem-Solving Therapy (PST) integrated with Motivational Interviewing (MI) and Behavioral Chain Analysis (BCA). A within-subject experiment was conducted with 28 caregivers interacting with four LLM configurations to evaluate empathy and therapeutic alliance. The best-performing models incorporated Few-Shot and Retrieval-Augmented Generation (RAG) prompting techniques, alongside clinician-curated examples. The models showed improved contextual understanding and personalized support, as reflected by qualitative responses and quantitative ratings on perceived empathy and therapeutic alliances. Participants valued the model's ability to validate emotions, explore unexpressed feelings, and provide actionable strategies. However, balancing thorough assessment with efficient advice delivery remains a challenge. This work highlights the potential of LLMs in delivering empathetic and tailored support for family caregivers.
Multi-perspective Feedback-attention Coupling Model for Continuous-time Dynamic Graphs
Dec 13, 2023Recently, representation learning over graph networks has gained popularity, with various models showing promising results. Despite this, several challenges persist: 1) most methods are designed for static or discrete-time dynamic graphs; 2) existing continuous-time dynamic graph algorithms focus on a single evolving perspective; and 3) many continuous-time dynamic graph approaches necessitate numerous temporal neighbors to capture long-term dependencies. In response, this paper introduces the Multi-Perspective Feedback-Attention Coupling (MPFA) model. MPFA incorporates information from both evolving and raw perspectives, efficiently learning the interleaved dynamics of observed processes. The evolving perspective employs temporal self-attention to distinguish continuously evolving temporal neighbors for information aggregation. Through dynamic updates, this perspective can capture long-term dependencies using a small number of temporal neighbors. Meanwhile, the raw perspective utilizes a feedback attention module with growth characteristic coefficients to aggregate raw neighborhood information. Experimental results on a self-organizing dataset and seven public datasets validate the efficacy and competitiveness of our proposed model.
DF2M: An Explainable Deep Bayesian Nonparametric Model for High-Dimensional Functional Time Series
May 23, 2023



In this paper, we present Deep Functional Factor Model (DF2M), a Bayesian nonparametric model for analyzing high-dimensional functional time series. The DF2M makes use of the Indian Buffet Process and the multi-task Gaussian Process with a deep kernel function to capture non-Markovian and nonlinear temporal dynamics. Unlike many black-box deep learning models, the DF2M provides an explainable way to use neural networks by constructing a factor model and incorporating deep neural networks within the kernel function. Additionally, we develop a computationally efficient variational inference algorithm for inferring the DF2M. Empirical results from four real-world datasets demonstrate that the DF2M offers better explainability and superior predictive accuracy compared to conventional deep learning models for high-dimensional functional time series.
EEGNN: Edge Enhanced Graph Neural Networks
Aug 12, 2022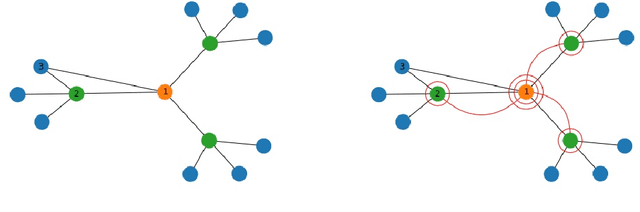
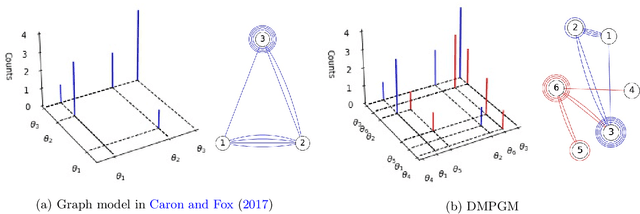
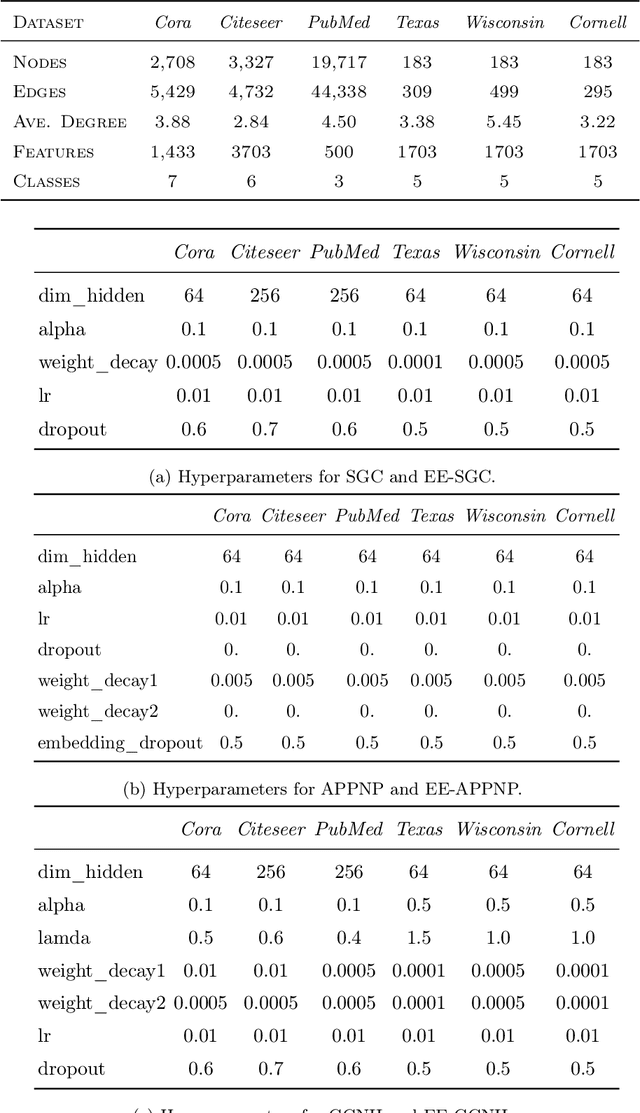
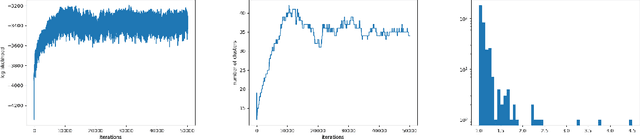
Training deep graph neural networks (GNNs) poses a challenging task, as the performance of GNNs may suffer from the number of hidden message-passing layers. The literature has focused on the proposals of over-smoothing and under-reaching to explain the performance deterioration of deep GNNs. In this paper, we propose a new explanation for such deteriorated performance phenomenon, mis-simplification, that is, mistakenly simplifying graphs by preventing self-loops and forcing edges to be unweighted. We show that such simplifying can reduce the potential of message-passing layers to capture the structural information of graphs. In view of this, we propose a new framework, edge enhanced graph neural network(EEGNN). EEGNN uses the structural information extracted from the proposed Dirichlet mixture Poisson graph model, a Bayesian nonparametric model for graphs, to improve the performance of various deep message-passing GNNs. Experiments over different datasets show that our method achieves considerable performance increase compared to baselines.