 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveUltraFeedback: Efficient Preference Data Generation using Active Learning
Mar 10, 2026Reinforcement Learning from Human Feedback (RLHF) has become the standard for aligning Large Language Models (LLMs), yet its efficacy is bottlenecked by the high cost of acquiring preference data, especially in low-resource and expert domains. To address this, we introduce ACTIVEULTRAFEEDBACK, a modular active learning pipeline that leverages uncertainty estimates to dynamically identify the most informative responses for annotation. Our pipeline facilitates the systematic evaluation of standard response selection methods alongside DOUBLE REVERSE THOMPSON SAMPLING (DRTS) and DELTAUCB, two novel methods prioritizing response pairs with large predicted quality gaps, leveraging recent results showing that such pairs provide good signals for fine-tuning. Our experiments demonstrate that ACTIVEULTRAFEEDBACK yields high-quality datasets that lead to significant improvements in downstream performance, notably achieving comparable or superior results with as little as one-sixth of the annotated data relative to static baselines. Our pipeline is available at https://github.com/lasgroup/ActiveUltraFeedback and our preference datasets at https://huggingface.co/ActiveUltraFeedback.
MODOC: A Modular Interface for Flexible Interlinking of Text Retrieval and Text Generation Functions
Aug 26, 2024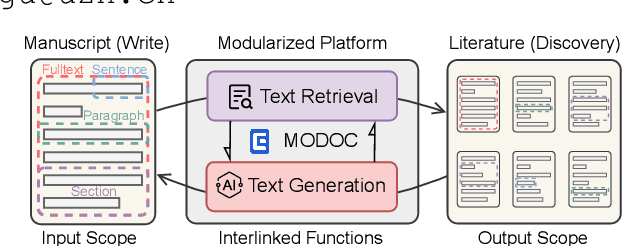
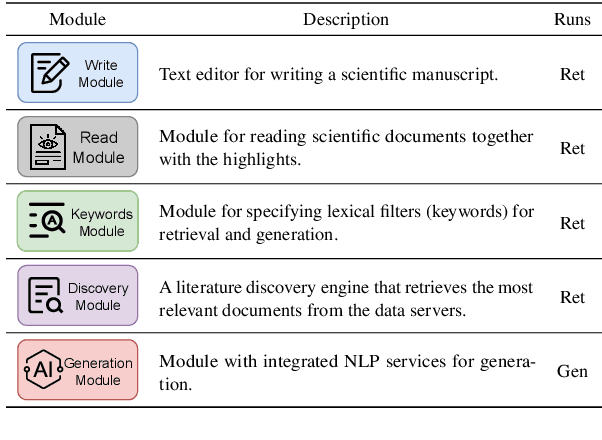
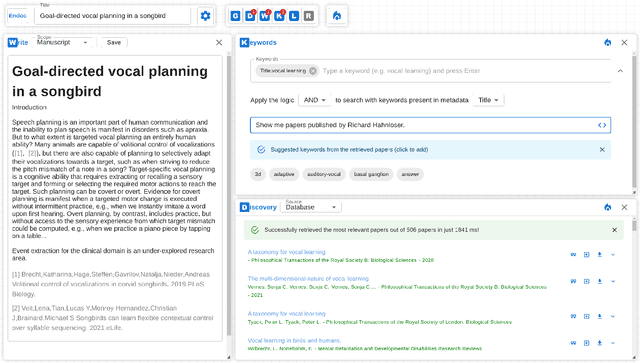
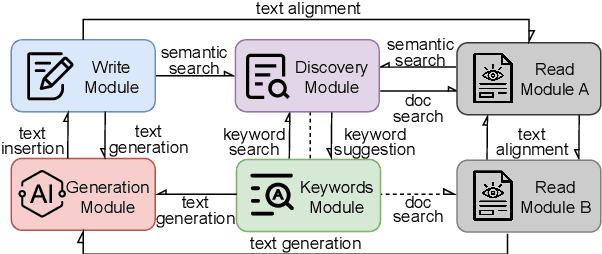
Large Language Models (LLMs) produce eloquent texts but often the content they generate needs to be verified. Traditional information retrieval systems can assist with this task, but most systems have not been designed with LLM-generated queries in mind. As such, there is a compelling need for integrated systems that provide both retrieval and generation functionality within a single user interface. We present MODOC, a modular user interface that leverages the capabilities of LLMs and provides assistance with detecting their confabulations, promoting integrity in scientific writing. MODOC represents a significant step forward in scientific writing assistance. Its modular architecture supports flexible functions for retrieving information and for writing and generating text in a single, user-friendly interface.
Unsupervised Scientific Abstract Segmentation with Normalized Mutual Information
May 19, 2023



The abstracts of scientific papers consist of premises and conclusions. Structured abstracts explicitly highlight the conclusion sentences, whereas non-structured abstracts may have conclusion sentences at uncertain positions. This implicit nature of conclusion positions makes the automatic segmentation of scientific abstracts into premises and conclusions a challenging task. In this work, we empirically explore using Normalized Mutual Information (NMI) for abstract segmentation. We consider each abstract as a recurrent cycle of sentences and place segmentation boundaries by greedily optimizing the NMI score between premises and conclusions. On non-structured abstracts, our proposed unsupervised approach GreedyCAS achieves the best performance across all evaluation metrics; on structured abstracts, GreedyCAS outperforms all baseline methods measured by $P_k$. The strong correlation of NMI to our evaluation metrics reveals the effectiveness of NMI for abstract segmentation.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023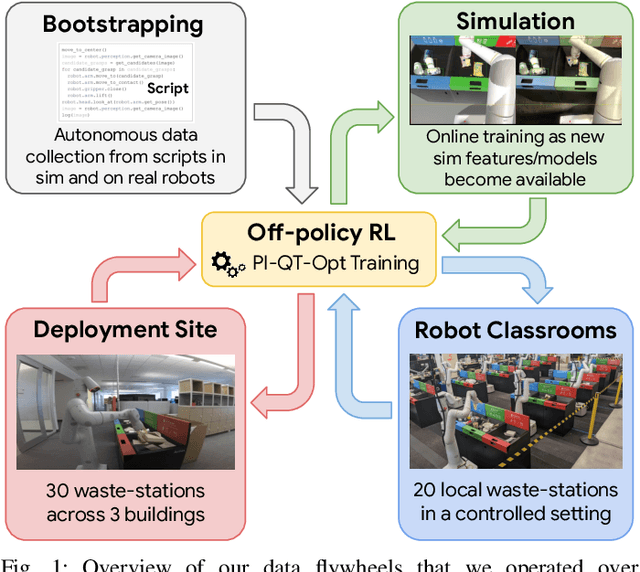

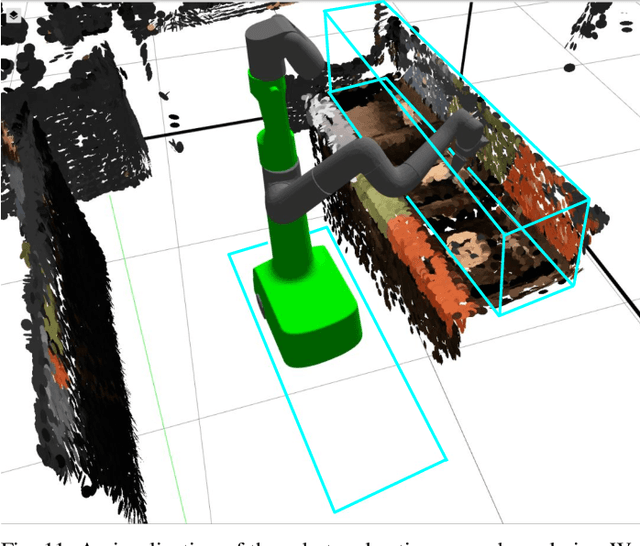

We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
EEGNN: Edge Enhanced Graph Neural Networks
Aug 12, 2022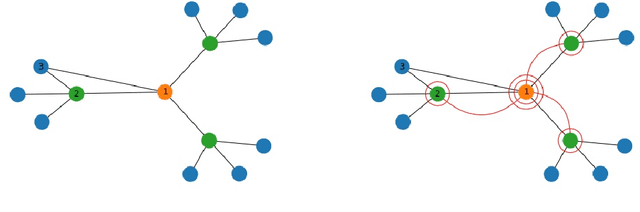
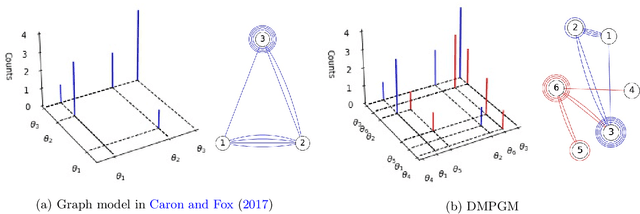
Training deep graph neural networks (GNNs) poses a challenging task, as the performance of GNNs may suffer from the number of hidden message-passing layers. The literature has focused on the proposals of over-smoothing and under-reaching to explain the performance deterioration of deep GNNs. In this paper, we propose a new explanation for such deteriorated performance phenomenon, mis-simplification, that is, mistakenly simplifying graphs by preventing self-loops and forcing edges to be unweighted. We show that such simplifying can reduce the potential of message-passing layers to capture the structural information of graphs. In view of this, we propose a new framework, edge enhanced graph neural network(EEGNN). EEGNN uses the structural information extracted from the proposed Dirichlet mixture Poisson graph model, a Bayesian nonparametric model for graphs, to improve the performance of various deep message-passing GNNs. Experiments over different datasets show that our method achieves considerable performance increase compared to baselines.