 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapabilities of Large Language Models in Control Engineering: A Benchmark Study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra
Paper and Code
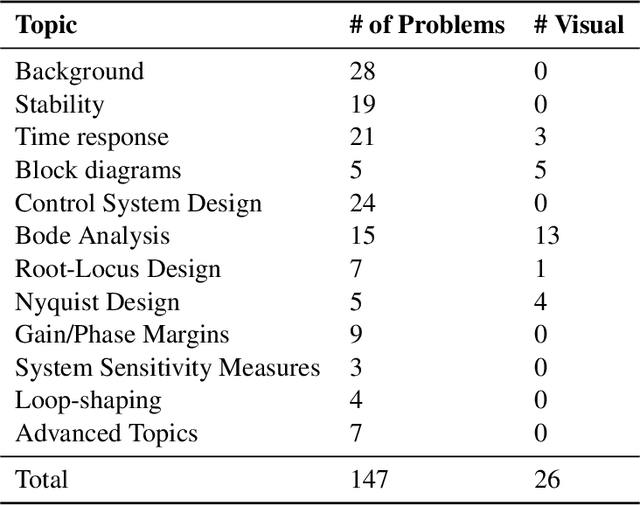
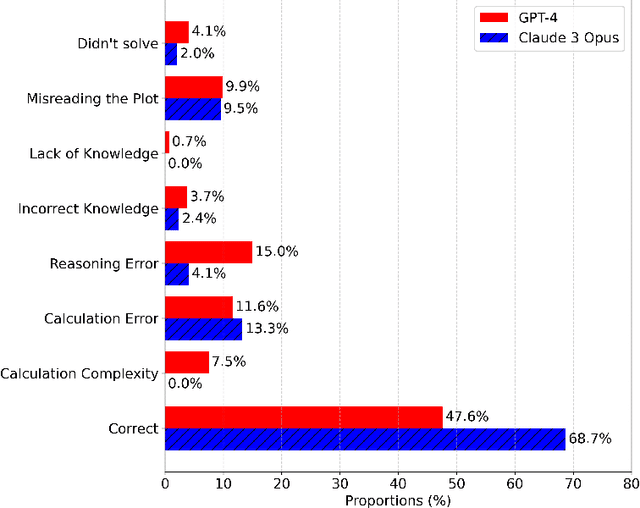
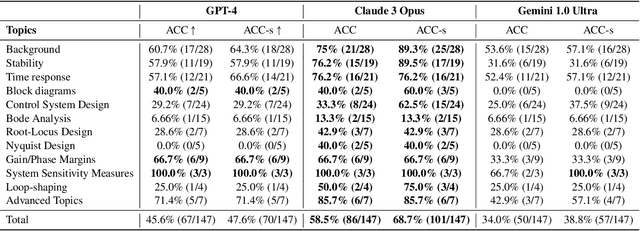
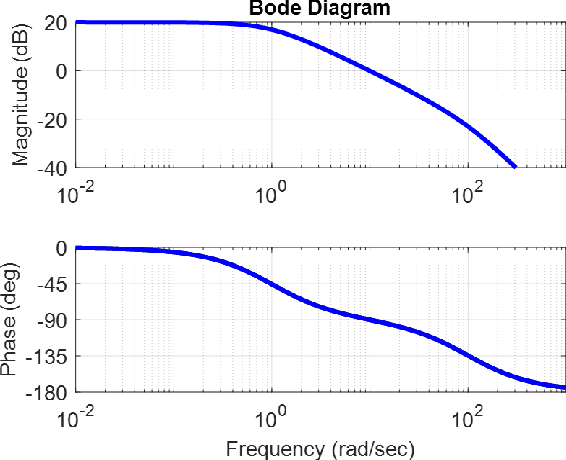
In this paper, we explore the capabilities of state-of-the-art large language models (LLMs) such as GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra in solving undergraduate-level control problems. Controls provides an interesting case study for LLM reasoning due to its combination of mathematical theory and engineering design. We introduce ControlBench, a benchmark dataset tailored to reflect the breadth, depth, and complexity of classical control design. We use this dataset to study and evaluate the problem-solving abilities of these LLMs in the context of control engineering. We present evaluations conducted by a panel of human experts, providing insights into the accuracy, reasoning, and explanatory prowess of LLMs in control engineering. Our analysis reveals the strengths and limitations of each LLM in the context of classical control, and our results imply that Claude 3 Opus has become the state-of-the-art LLM for solving undergraduate control problems. Our study serves as an initial step towards the broader goal of employing artificial general intelligence in control engineering.