 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservability, Identifiability and Sensitivity of Vision-Aided Navigation
Apr 26, 2015We analyze the observability of motion estimates from the fusion of visual and inertial sensors. Because the model contains unknown parameters, such as sensor biases, the problem is usually cast as a mixed identification/filtering, and the resulting observability analysis provides a necessary condition for any algorithm to converge to a unique point estimate. Unfortunately, most models treat sensor bias rates as noise, independent of other states including biases themselves, an assumption that is patently violated in practice. When this assumption is lifted, the resulting model is not observable, and therefore past analyses cannot be used to conclude that the set of states that are indistinguishable from the measurements is a singleton. In other words, the resulting model is not observable. We therefore re-cast the analysis as one of sensitivity: Rather than attempting to prove that the indistinguishable set is a singleton, which is not the case, we derive bounds on its volume, as a function of characteristics of the input and its sufficient excitation. This provides an explicit characterization of the indistinguishable set that can be used for analysis and validation purposes.
On the Design and Analysis of Multiple View Descriptors
Nov 23, 2013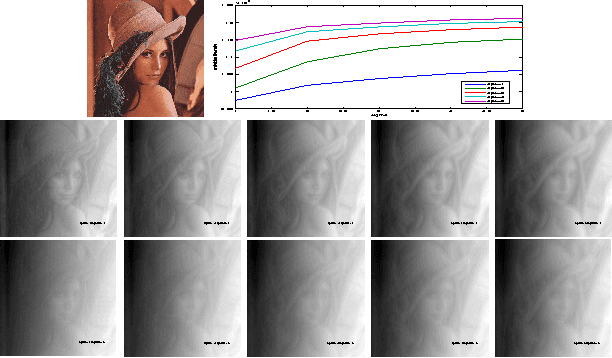

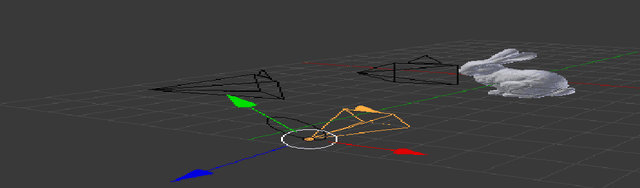
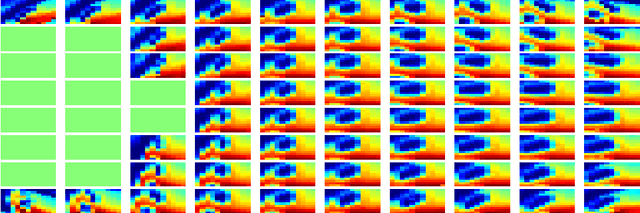
We propose an extension of popular descriptors based on gradient orientation histograms (HOG, computed in a single image) to multiple views. It hinges on interpreting HOG as a conditional density in the space of sampled images, where the effects of nuisance factors such as viewpoint and illumination are marginalized. However, such marginalization is performed with respect to a very coarse approximation of the underlying distribution. Our extension leverages on the fact that multiple views of the same scene allow separating intrinsic from nuisance variability, and thus afford better marginalization of the latter. The result is a descriptor that has the same complexity of single-view HOG, and can be compared in the same manner, but exploits multiple views to better trade off insensitivity to nuisance variability with specificity to intrinsic variability. We also introduce a novel multi-view wide-baseline matching dataset, consisting of a mixture of real and synthetic objects with ground truthed camera motion and dense three-dimensional geometry.