 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Parameter Tuning for Image Processing
Dec 27, 2017
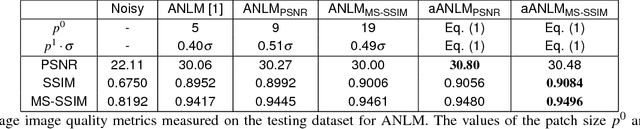
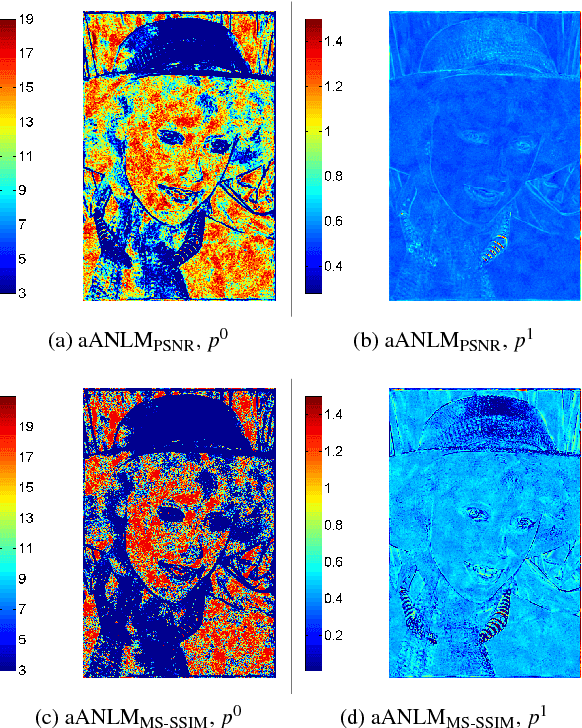

The non-stationary nature of image characteristics calls for adaptive processing, based on the local image content. We propose a simple and flexible method to learn local tuning of parameters in adaptive image processing: we extract simple local features from an image and learn the relation between these features and the optimal filtering parameters. Learning is performed by optimizing a user defined cost function (any image quality metric) on a training set. We apply our method to three classical problems (denoising, demosaicing and deblurring) and we show the effectiveness of the learned parameter modulation strategies. We also show that these strategies are consistent with theoretical results from the literature.
Visual-Inertial-Semantic Scene Representation for 3-D Object Detection
Apr 17, 2017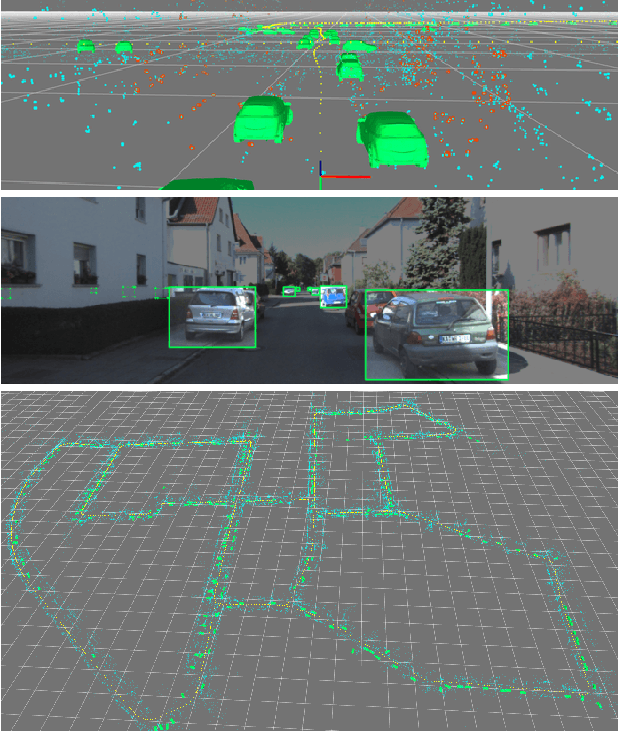


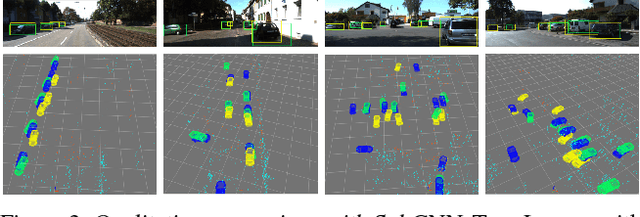
We describe a system to detect objects in three-dimensional space using video and inertial sensors (accelerometer and gyrometer), ubiquitous in modern mobile platforms from phones to drones. Inertials afford the ability to impose class-specific scale priors for objects, and provide a global orientation reference. A minimal sufficient representation, the posterior of semantic (identity) and syntactic (pose) attributes of objects in space, can be decomposed into a geometric term, which can be maintained by a localization-and-mapping filter, and a likelihood function, which can be approximated by a discriminatively-trained convolutional neural network. The resulting system can process the video stream causally in real time, and provides a representation of objects in the scene that is persistent: Confidence in the presence of objects grows with evidence, and objects previously seen are kept in memory even when temporarily occluded, with their return into view automatically predicted to prime re-detection.
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability
Apr 28, 2016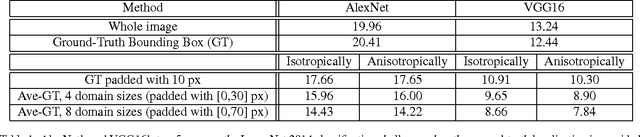
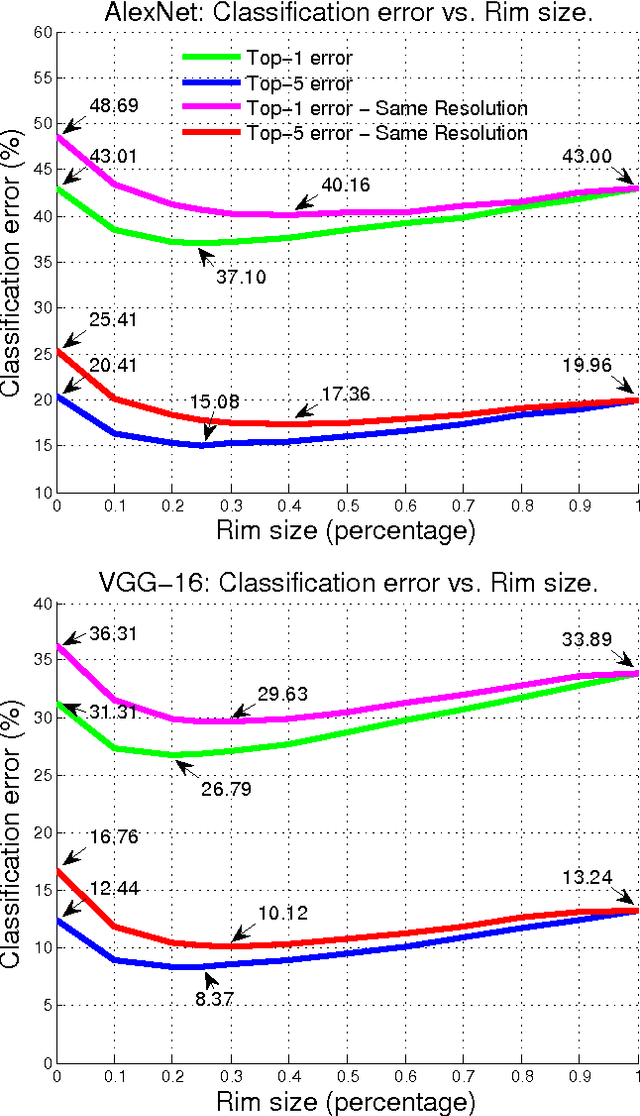
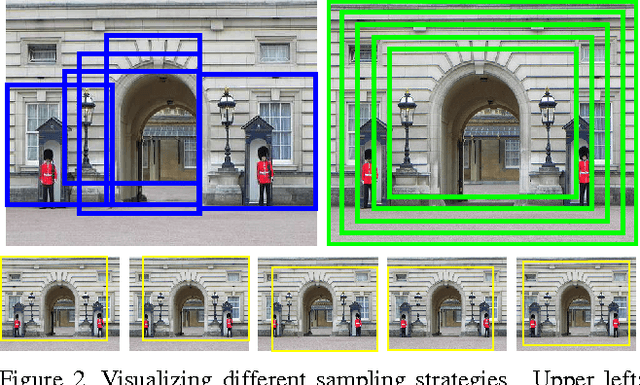
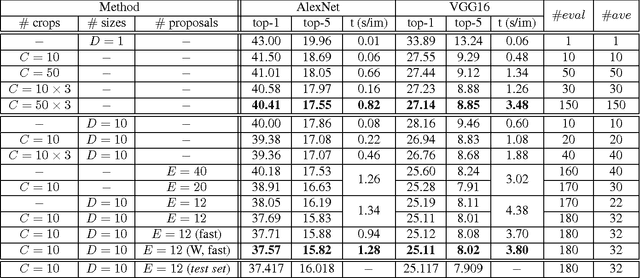
We conduct an empirical study to test the ability of Convolutional Neural Networks (CNNs) to reduce the effects of nuisance transformations of the input data, such as location, scale and aspect ratio. We isolate factors by adopting a common convolutional architecture either deployed globally on the image to compute class posterior distributions, or restricted locally to compute class conditional distributions given location, scale and aspect ratios of bounding boxes determined by proposal heuristics. In theory, averaging the latter should yield inferior performance compared to proper marginalization. Yet empirical evidence suggests the converse, leading us to conclude that - at the current level of complexity of convolutional architectures and scale of the data sets used to train them - CNNs are not very effective at marginalizing nuisance variability. We also quantify the effects of context on the overall classification task and its impact on the performance of CNNs, and propose improved sampling techniques for heuristic proposal schemes that improve end-to-end performance to state-of-the-art levels. We test our hypothesis on a classification task using the ImageNet Challenge benchmark and on a wide-baseline matching task using the Oxford and Fischer's datasets.
Domain-Size Pooling in Local Descriptors: DSP-SIFT
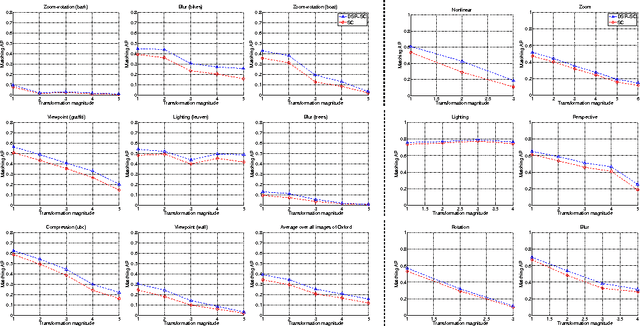
May 05, 2015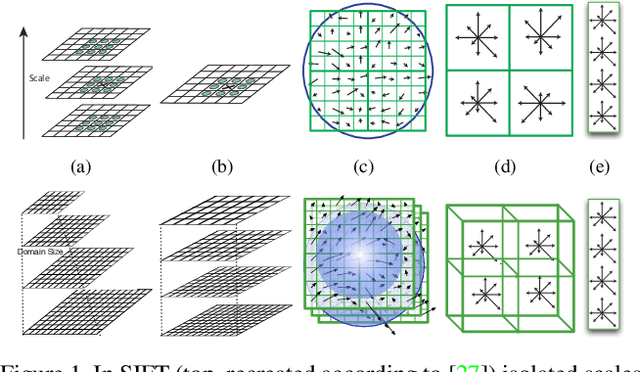
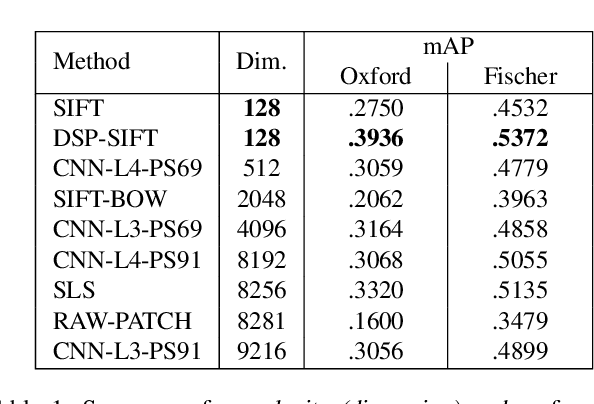
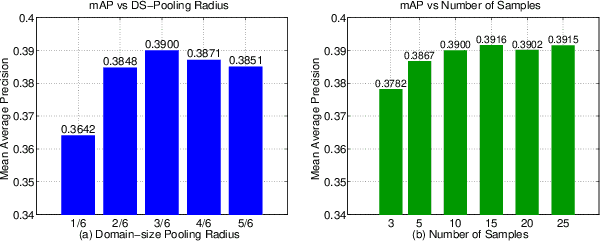

We introduce a simple modification of local image descriptors, such as SIFT, based on pooling gradient orientations across different domain sizes, in addition to spatial locations. The resulting descriptor, which we call DSP-SIFT, outperforms other methods in wide-baseline matching benchmarks, including those based on convolutional neural networks, despite having the same dimension of SIFT and requiring no training.
Visual Scene Representations: Contrast, Scaling and Occlusion
Apr 17, 2015


We study the structure of representations, defined as approximations of minimal sufficient statistics that are maximal invariants to nuisance factors, for visual data subject to scaling and occlusion of line-of-sight. We derive analytical expressions for such representations and show that, under certain restrictive assumptions, they are related to features commonly in use in the computer vision community. This link highlights the condition tacitly assumed by these descriptors, and also suggests ways to improve and generalize them. This new interpretation draws connections to the classical theories of sampling, hypothesis testing and group invariance.
On the Design and Analysis of Multiple View Descriptors
Nov 23, 2013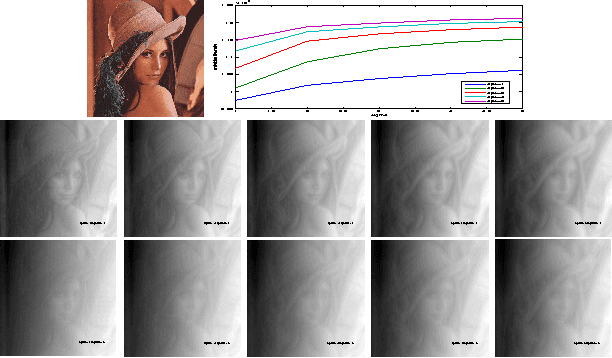

We propose an extension of popular descriptors based on gradient orientation histograms (HOG, computed in a single image) to multiple views. It hinges on interpreting HOG as a conditional density in the space of sampled images, where the effects of nuisance factors such as viewpoint and illumination are marginalized. However, such marginalization is performed with respect to a very coarse approximation of the underlying distribution. Our extension leverages on the fact that multiple views of the same scene allow separating intrinsic from nuisance variability, and thus afford better marginalization of the latter. The result is a descriptor that has the same complexity of single-view HOG, and can be compared in the same manner, but exploits multiple views to better trade off insensitivity to nuisance variability with specificity to intrinsic variability. We also introduce a novel multi-view wide-baseline matching dataset, consisting of a mixture of real and synthetic objects with ground truthed camera motion and dense three-dimensional geometry.