 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompose by Focus: Scene Graph-based Atomic Skills
Sep 19, 2025
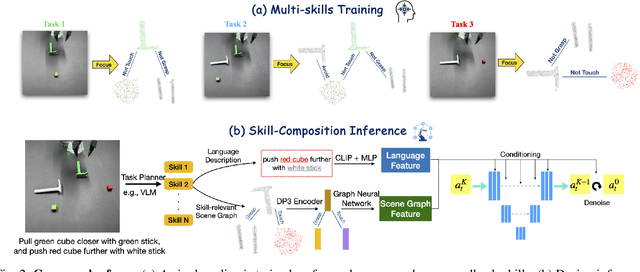
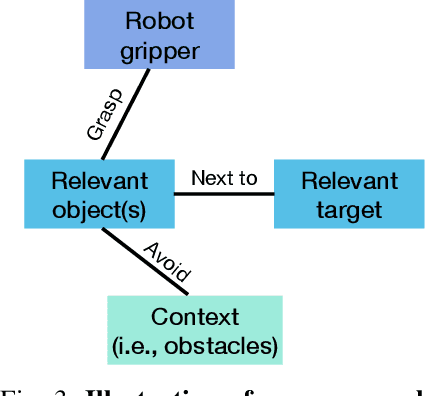
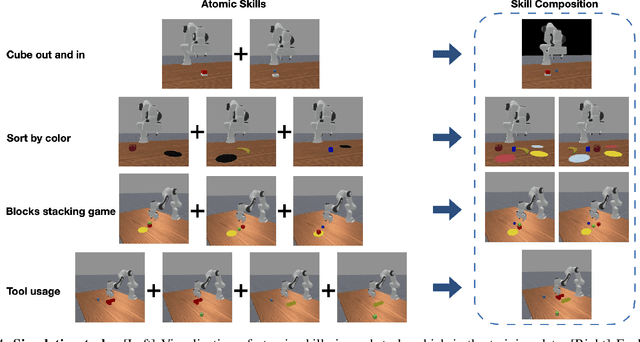
A key requirement for generalist robots is compositional generalization - the ability to combine atomic skills to solve complex, long-horizon tasks. While prior work has primarily focused on synthesizing a planner that sequences pre-learned skills, robust execution of the individual skills themselves remains challenging, as visuomotor policies often fail under distribution shifts induced by scene composition. To address this, we introduce a scene graph-based representation that focuses on task-relevant objects and relations, thereby mitigating sensitivity to irrelevant variation. Building on this idea, we develop a scene-graph skill learning framework that integrates graph neural networks with diffusion-based imitation learning, and further combine "focused" scene-graph skills with a vision-language model (VLM) based task planner. Experiments in both simulation and real-world manipulation tasks demonstrate substantially higher success rates than state-of-the-art baselines, highlighting improved robustness and compositional generalization in long-horizon tasks.
ViSA-Flow: Accelerating Robot Skill Learning via Large-Scale Video Semantic Action Flow
May 02, 2025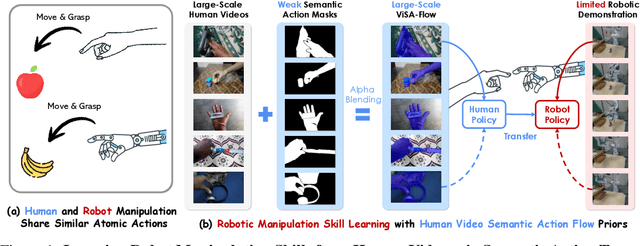
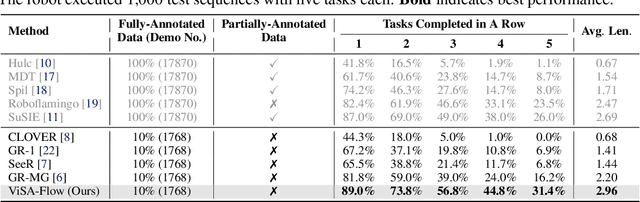
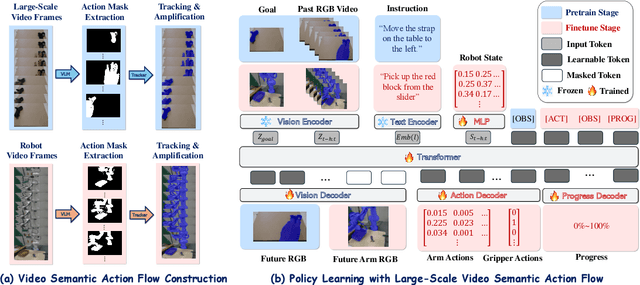
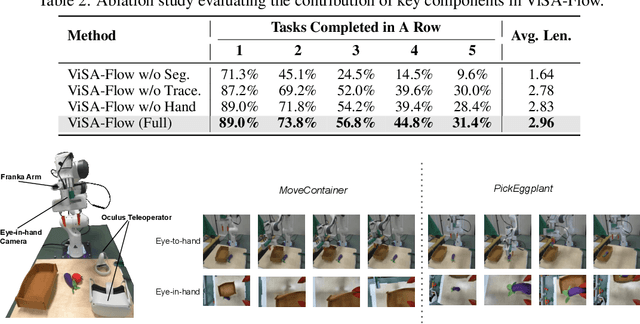
One of the central challenges preventing robots from acquiring complex manipulation skills is the prohibitive cost of collecting large-scale robot demonstrations. In contrast, humans are able to learn efficiently by watching others interact with their environment. To bridge this gap, we introduce semantic action flow as a core intermediate representation capturing the essential spatio-temporal manipulator-object interactions, invariant to superficial visual differences. We present ViSA-Flow, a framework that learns this representation self-supervised from unlabeled large-scale video data. First, a generative model is pre-trained on semantic action flows automatically extracted from large-scale human-object interaction video data, learning a robust prior over manipulation structure. Second, this prior is efficiently adapted to a target robot by fine-tuning on a small set of robot demonstrations processed through the same semantic abstraction pipeline. We demonstrate through extensive experiments on the CALVIN benchmark and real-world tasks that ViSA-Flow achieves state-of-the-art performance, particularly in low-data regimes, outperforming prior methods by effectively transferring knowledge from human video observation to robotic execution. Videos are available at https://visaflow-web.github.io/ViSAFLOW.
Large Language Models as Natural Selector for Embodied Soft Robot Design
Mar 04, 2025



Designing soft robots is a complex and iterative process that demands cross-disciplinary expertise in materials science, mechanics, and control, often relying on intuition and extensive experimentation. While Large Language Models (LLMs) have demonstrated impressive reasoning abilities, their capacity to learn and apply embodied design principles--crucial for creating functional robotic systems--remains largely unexplored. This paper introduces RoboCrafter-QA, a novel benchmark to evaluate whether LLMs can learn representations of soft robot designs that effectively bridge the gap between high-level task descriptions and low-level morphological and material choices. RoboCrafter-QA leverages the EvoGym simulator to generate a diverse set of soft robot design challenges, spanning robotic locomotion, manipulation, and balancing tasks. Our experiments with state-of-the-art multi-modal LLMs reveal that while these models exhibit promising capabilities in learning design representations, they struggle with fine-grained distinctions between designs with subtle performance differences. We further demonstrate the practical utility of LLMs for robot design initialization. Our code and benchmark will be available to encourage the community to foster this exciting research direction.
CRITERIA: a New Benchmarking Paradigm for Evaluating Trajectory Prediction Models for Autonomous Driving
Oct 11, 2023



Benchmarking is a common method for evaluating trajectory prediction models for autonomous driving. Existing benchmarks rely on datasets, which are biased towards more common scenarios, such as cruising, and distance-based metrics that are computed by averaging over all scenarios. Following such a regiment provides a little insight into the properties of the models both in terms of how well they can handle different scenarios and how admissible and diverse their outputs are. There exist a number of complementary metrics designed to measure the admissibility and diversity of trajectories, however, they suffer from biases, such as length of trajectories. In this paper, we propose a new benChmarking paRadIgm for evaluaTing trajEctoRy predIction Approaches (CRITERIA). Particularly, we propose 1) a method for extracting driving scenarios at varying levels of specificity according to the structure of the roads, models' performance, and data properties for fine-grained ranking of prediction models; 2) A set of new bias-free metrics for measuring diversity, by incorporating the characteristics of a given scenario, and admissibility, by considering the structure of roads and kinematic compliancy, motivated by real-world driving constraints. 3) Using the proposed benchmark, we conduct extensive experimentation on a representative set of the prediction models using the large scale Argoverse dataset. We show that the proposed benchmark can produce a more accurate ranking of the models and serve as a means of characterizing their behavior. We further present ablation studies to highlight contributions of different elements that are used to compute the proposed metrics.