 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Aggregation of Trajectory Predictors
Paper and Code
Feb 11, 2025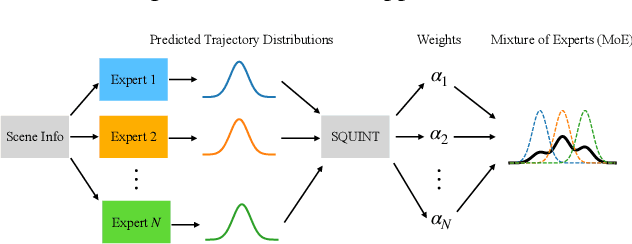
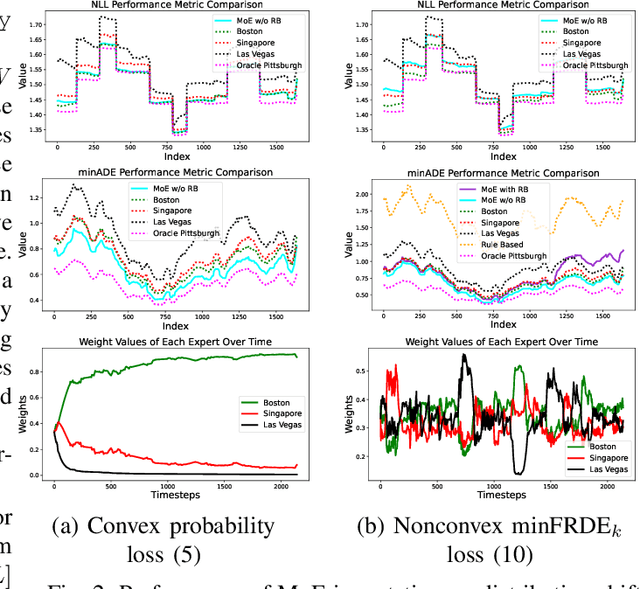
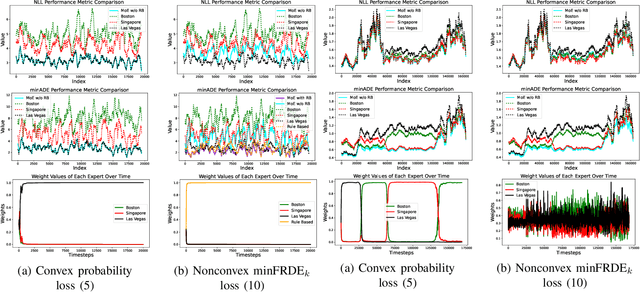
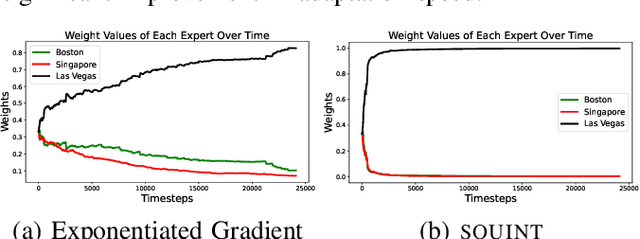
Trajectory prediction, the task of forecasting future agent behavior from past data, is central to safe and efficient autonomous driving. A diverse set of methods (e.g., rule-based or learned with different architectures and datasets) have been proposed, yet it is often the case that the performance of these methods is sensitive to the deployment environment (e.g., how well the design rules model the environment, or how accurately the test data match the training data). Building upon the principled theory of online convex optimization but also going beyond convexity and stationarity, we present a lightweight and model-agnostic method to aggregate different trajectory predictors online. We propose treating each individual trajectory predictor as an "expert" and maintaining a probability vector to mix the outputs of different experts. Then, the key technical approach lies in leveraging online data -the true agent behavior to be revealed at the next timestep- to form a convex-or-nonconvex, stationary-or-dynamic loss function whose gradient steers the probability vector towards choosing the best mixture of experts. We instantiate this method to aggregate trajectory predictors trained on different cities in the NUSCENES dataset and show that it performs just as well, if not better than, any singular model, even when deployed on the out-of-distribution LYFT dataset.