 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCBiRRT: Rapid Motion Planning for Tightly Coupled Dual-arm Space Manipulator Using Task-space Random Expansion
May 26, 2026Planning the motion path for a tightly coupled dual-arm space manipulator under closed-chain constraints is a fundamental yet challenging problem in on-orbit assembly of large-scale space structures. The closed-chain constraints significantly reduce the feasible configuration space, making it difficult for existing planners to efficiently generate collision-free motions, especially in cluttered environments. To address this issue, this paper proposes a task-space constrained bidirectional rapidly-exploring random tree algorithm, termed TCBiRRT. Unlike conventional methods that operate in the high-dimensional configuration space, the proposed approach performs random sampling and node expansion directly in the task space defined by the manipulated object pose. A task-space node expansion strategy is developed to generate candidate object motions, which are then mapped to continuous joint paths using a path inverse kinematics algorithm. The method is further integrated with a bidirectional RRT framework and a regrasp mechanism to efficiently connect two random trees. Extensive simulations are conducted in representative on-orbit assembly scenarios with varying levels of environmental complexity. The results demonstrate that TCBiRRT achieves significantly higher success rates and orders-of-magnitude improvements in planning time compared to state-of-the-art planners. The proposed method provides an efficient and robust solution for motion planning of tightly coupled dual-arm space manipulators.
Weak-Fluctuation-Induced Clutter Covariance and Subspace Structure in Single-Snapshot FDA-MIMO GPR
Apr 28, 2026Weak constitutive fluctuations in dispersive subsurface media can induce distributed clutter that reshapes the observation structure of ground-penetrating radar (GPR). This paper analyzes this effect for single-snapshot frequency-diverse array multiple-input multiple-output GPR. Focusing on medium-induced clutter, rather than on general target--clutter joint modeling, it establishes a statistical propagation chain from Cole--Cole parameter perturbations to electromagnetic contrast, first-order Born channel snapshots, clutter covariance, and subspace descriptors. A medium-aware snapshot model and a covariance propagation framework are then derived to characterize how constitutive uncertainty alters observation-domain spectral structure under a local weak-fluctuation regime. Numerical experiments verify the consistency of the proposed propagation relation under the adopted first-order Born and constitutive-linearization approximations. Within the tested setting, medium-induced clutter reshapes the eigenspectrum and changes target--clutter overlap metrics. Spatial correlation length and background-scene variation act as consistently strong structural drivers, while the FDA frequency increment also produces measurable changes in the normalized covariance geometry.
Medium-Induced Cross-Frequency Clutter Structure in Single-Snapshot FDA-MIMO-GPR With a Weak-Dispersion Criterion
Apr 27, 2026This paper investigates the cross-frequency structure of background clutter induced by random dispersive media in single-snapshot FDA-MIMO-GPR. Representative media are modeled by the Cole--Cole formulation to relate dispersive constitutive behavior to the reference propagation environment and observation-domain statistics. A normalized incremental contrast function is introduced under a reference-medium framework, and a single-snapshot background-response expression with first-order propagation-kernel feedback is derived. Based on this expression, a cross-frequency coupling strength of the leading-order background covariance is defined. Numerical results show that, in weakly dispersive scenes, the proposed analysis remains consistent across constitutive mapping, the zeroth-order propagation skeleton, first-order distorted-Born truncation, propagation-kernel feedback, and single-channel response closure. The proposed metric distinguishes uncoupled and explicitly coupled constructions, remains stable under pure energy scaling, responds clearly to correlation length and relaxation-location parameters, and corresponds directly to the error of the frequency block-diagonal approximation. Additional experiments show that the resulting cross-frequency structure affects whitening and principal-subspace extraction. In scenes with pronounced relaxation, abrupt breakdown under strong perturbations and high-error plateaus indicate that the present theory is mainly applicable within the validity range of first-order feedback.
Z-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Mar 26, 2026Concept erasure serves as a vital safety mechanism for removing unwanted concepts from text-to-image (T2I) models. While extensively studied in U-Net and dual-stream architectures (e.g., Flux), this task remains under-explored in the recent emerging paradigm of single-stream diffusion transformers (e.g., Z-Image). In this new paradigm, text and image tokens are processed as a single unified sequence via shared parameters. Consequently, directly applying prior erasure methods typically leads to generation collapse. To bridge this gap, we introduce Z-Erase, the first concept erasure method tailored for single-stream T2I models. To guarantee stable image generation, Z-Erase first proposes a Stream Disentangled Concept Erasure Framework that decouples updates and enables existing methods on single-stream models. Subsequently, within this framework, we introduce Lagrangian-Guided Adaptive Erasure Modulation, a constrained algorithm that further balances the sensitive erasure-preservation trade-off. Moreover, we provide a rigorous convergence analysis proving that Z-Erase can converge to a Pareto stationary point. Experiments demonstrate that Z-Erase successfully overcomes the generation collapse issue, achieving state-of-the-art performance across a wide range of tasks.
Linking Dispersive-Medium Uncertainty to Clutter Analysis in Single-Snapshot FDA-MIMO-GPR
Mar 25, 2026This paper addresses the modeling gap between complex dispersive-medium characterization and clutter statistical analysis in single-snapshot frequency diverse array multiple-input multiple-output ground-penetrating radar (FDA-MIMO-GPR). Existing FDA-MIMO clutter studies have rarely incorporated subsurface dispersion, dissipation, and random inhomogeneity in an explicit statistical framework. To bridge this gap, a continuous relaxation spectrum is adopted to describe complex media, and a statistical propagation chain is established from random relaxation-spectrum perturbations to complex permittivity, complex wavenumber, steering-vector perturbation, medium-induced additional clutter covariance, and total clutter covariance. On this basis, the effects of medium randomness on covariance spectral spreading, effective rank, effective clutter-subspace dimension, and target-clutter separability are further characterized. Numerical results show close agreement between the derived theory and Monte Carlo sample statistics across multiple stages of the propagation chain. The results further indicate that medium uncertainty not only changes clutter-covariance entries, but also reshapes its eigenspectrum and effective subspace, thereby influencing the geometric separation between target and clutter. The study provides an explicit and interpretable theoretical interface for embedding complex-medium uncertainty into FDA-MIMO-GPR clutter statistical analysis.
Local Path Optimization in The Latent Space Using Learned Distance Gradient
Dec 30, 2025Constrained motion planning is a common but challenging problem in robotic manipulation. In recent years, data-driven constrained motion planning algorithms have shown impressive planning speed and success rate. Among them, the latent motion method based on manifold approximation is the most efficient planning algorithm. Due to errors in manifold approximation and the difficulty in accurately identifying collision conflicts within the latent space, time-consuming path validity checks and path replanning are required. In this paper, we propose a method that trains a neural network to predict the minimum distance between the robot and obstacles using latent vectors as inputs. The learned distance gradient is then used to calculate the direction of movement in the latent space to move the robot away from obstacles. Based on this, a local path optimization algorithm in the latent space is proposed, and it is integrated with the path validity checking process to reduce the time of replanning. The proposed method is compared with state-of-the-art algorithms in multiple planning scenarios, demonstrating the fastest planning speed
* This paper has been published in IROS 2025
Multiple Peg-in-Hole Assembly of Tightly Coupled Multi-manipulator Using Learning-based Visual Servo
Jul 15, 2024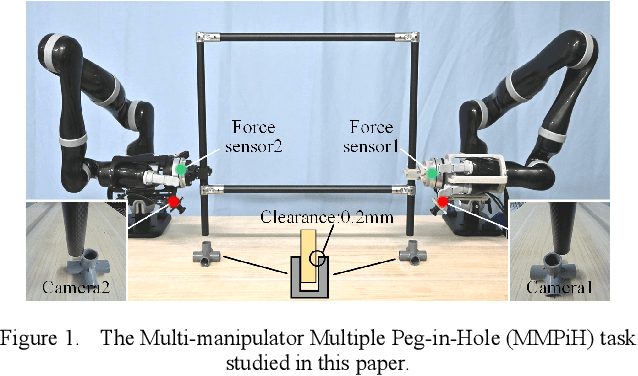
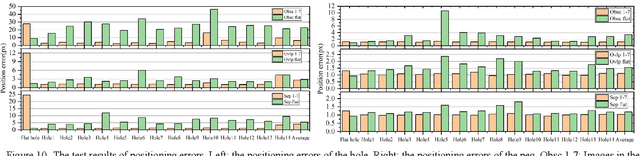


Multiple peg-in-hole assembly is one of the fundamental tasks in robotic assembly. In the multiple peg-in-hole task for large-sized parts, it is challenging for a single manipulator to simultaneously align multiple distant pegs and holes, necessitating tightly coupled multi-manipulator systems. For such Multi-manipulator Multiple Peg-in-Hole (MMPiH) tasks, we proposes a collaborative visual servo control framework that uses only the monocular in-hand cameras of each manipulator to reduce positioning errors. Initially, we train a state classification neural network and a positioning neural network. The former is used to divide the states of peg and hole in the image into three categories: obscured, separated and overlapped, while the latter determines the position of the peg and hole in the image. Based on these findings, we propose a method to integrate the visual features of multiple manipulators using virtual forces, which can naturally combine with the cooperative controller of the multi-manipulator system. To generalize our approach to holes of different appearances, we varied the appearance of the holes during the dataset generation process. The results confirm that by considering the appearance of the holes, classification accuracy and positioning precision can be improved. Finally, the results show that our method achieves an 85% success rate in dual-manipulator dual peg-in-hole tasks with a clearance of 0.2 mm.
Incremental Self-training for Semi-supervised Learning
Apr 14, 2024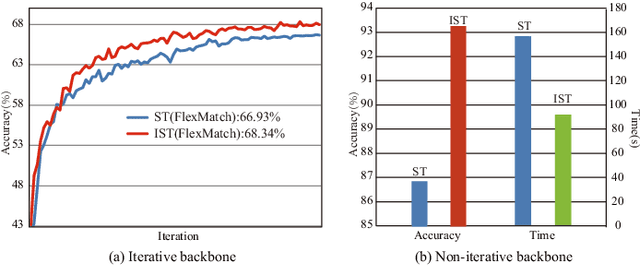
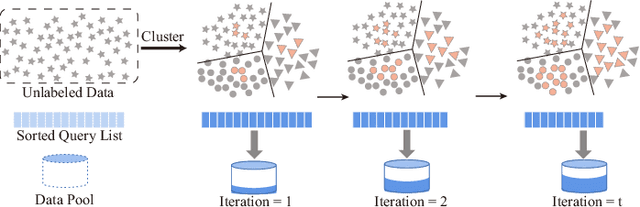
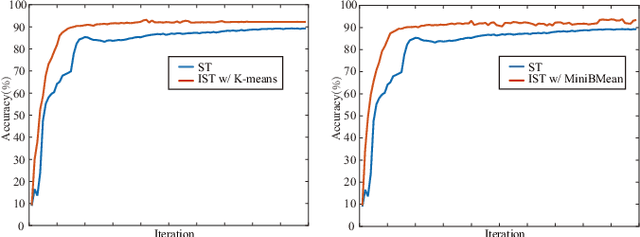
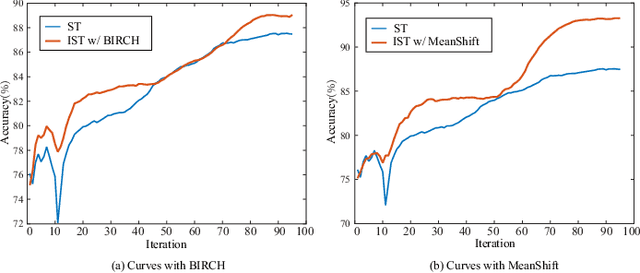
Semi-supervised learning provides a solution to reduce the dependency of machine learning on labeled data. As one of the efficient semi-supervised techniques, self-training (ST) has received increasing attention. Several advancements have emerged to address challenges associated with noisy pseudo-labels. Previous works on self-training acknowledge the importance of unlabeled data but have not delved into their efficient utilization, nor have they paid attention to the problem of high time consumption caused by iterative learning. This paper proposes Incremental Self-training (IST) for semi-supervised learning to fill these gaps. Unlike ST, which processes all data indiscriminately, IST processes data in batches and priority assigns pseudo-labels to unlabeled samples with high certainty. Then, it processes the data around the decision boundary after the model is stabilized, enhancing classifier performance. Our IST is simple yet effective and fits existing self-training-based semi-supervised learning methods. We verify the proposed IST on five datasets and two types of backbone, effectively improving the recognition accuracy and learning speed. Significantly, it outperforms state-of-the-art competitors on three challenging image classification tasks.
ConvBLS: An Effective and Efficient Incremental Convolutional Broad Learning System for Image Classification
Apr 01, 2023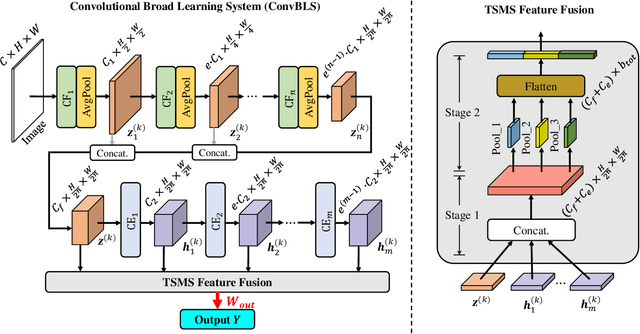
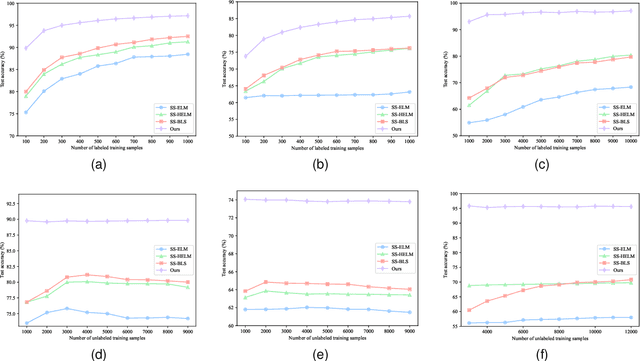
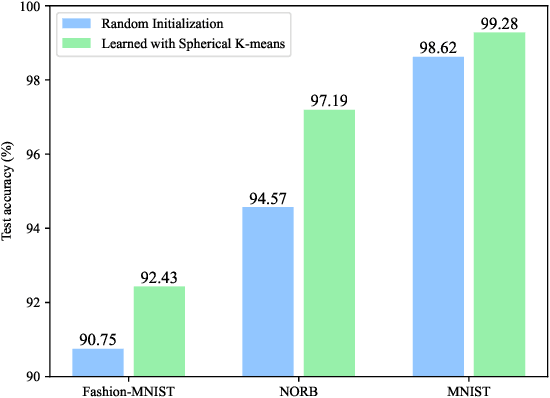

Deep learning generally suffers from enormous computational resources and time-consuming training processes. Broad Learning System (BLS) and its convolutional variants have been proposed to mitigate these issues and have achieved superb performance in image classification. However, the existing convolutional-based broad learning system (C-BLS) either lacks an efficient training method and incremental learning capability or suffers from poor performance. To this end, we propose a convolutional broad learning system (ConvBLS) based on the spherical K-means (SKM) algorithm and two-stage multi-scale (TSMS) feature fusion, which consists of the convolutional feature (CF) layer, convolutional enhancement (CE) layer, TSMS feature fusion layer, and output layer. First, unlike the current C-BLS, the simple yet efficient SKM algorithm is utilized to learn the weights of CF layers. Compared with random filters, the SKM algorithm makes the CF layer learn more comprehensive spatial features. Second, similar to the vanilla BLS, CE layers are established to expand the feature space. Third, the TSMS feature fusion layer is proposed to extract more effective multi-scale features through the integration of CF layers and CE layers. Thanks to the above design and the pseudo-inverse calculation of the output layer weights, our proposed ConvBLS method is unprecedentedly efficient and effective. Finally, the corresponding incremental learning algorithms are presented for rapid remodeling if the model deems to expand. Experiments and comparisons demonstrate the superiority of our method.
Solid Texture Synthesis using Generative Adversarial Networks
Feb 08, 2021

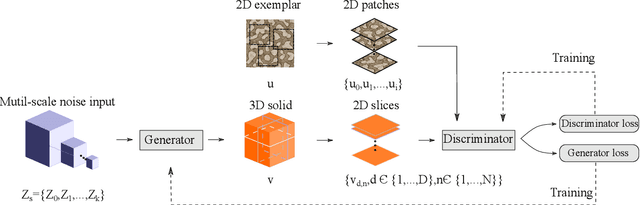
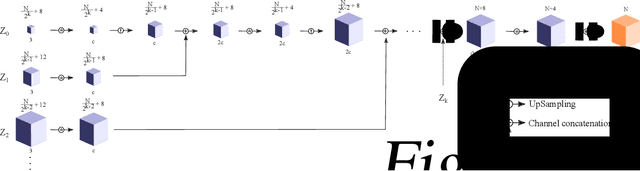
Solid texture synthesis, as an effective way to extend 2D texture to 3D solid texture, exhibits advantages in numerous application domains. However, existing methods generally suffer from synthesis distortion due to the underutilization of texture information. In this paper, we proposed a novel neural network-based approach for the solid texture synthesis based on generative adversarial networks, namely STS-GAN, in which the generator composed of multi-scale modules learns the internal distribution of 2D exemplar and further extends it to a 3D solid texture. In addition, the discriminator evaluates the similarity between 2D exemplar and slices, promoting the generator to synthesize realistic solid texture. Experiment results demonstrate that the proposed method can synthesize high-quality 3D solid texture with similar visual characteristics to the exemplar.