 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Self-training for Semi-supervised Learning
Paper and Code
Apr 14, 2024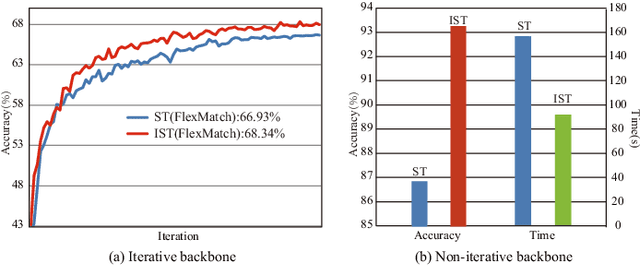
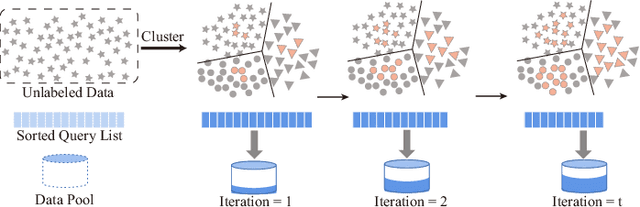
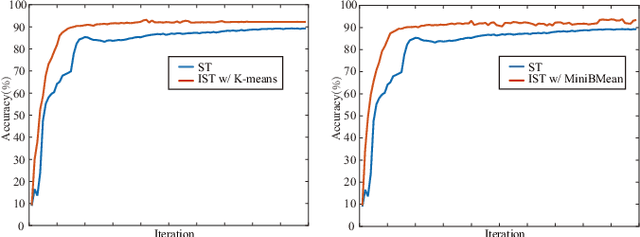
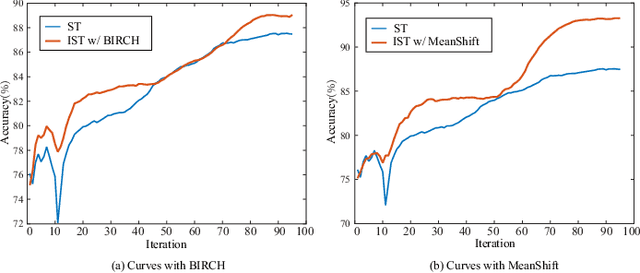
Semi-supervised learning provides a solution to reduce the dependency of machine learning on labeled data. As one of the efficient semi-supervised techniques, self-training (ST) has received increasing attention. Several advancements have emerged to address challenges associated with noisy pseudo-labels. Previous works on self-training acknowledge the importance of unlabeled data but have not delved into their efficient utilization, nor have they paid attention to the problem of high time consumption caused by iterative learning. This paper proposes Incremental Self-training (IST) for semi-supervised learning to fill these gaps. Unlike ST, which processes all data indiscriminately, IST processes data in batches and priority assigns pseudo-labels to unlabeled samples with high certainty. Then, it processes the data around the decision boundary after the model is stabilized, enhancing classifier performance. Our IST is simple yet effective and fits existing self-training-based semi-supervised learning methods. We verify the proposed IST on five datasets and two types of backbone, effectively improving the recognition accuracy and learning speed. Significantly, it outperforms state-of-the-art competitors on three challenging image classification tasks.