 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Distribution Matching for Few-Step Diffusion Distillation
May 07, 2026Step distillation has become a leading technique for accelerating diffusion models, among which Distribution Matching Distillation (DMD) and Consistency Distillation are two representative paradigms. While consistency methods enforce self-consistency along the full PF-ODE trajectory to steer it toward the clean data manifold, vanilla DMD relies on sparse supervision at a few predefined discrete timesteps. This restricted discrete-time formulation and mode-seeking nature of the reverse KL divergence tends to exhibit visual artifacts and over-smoothed outputs, often necessitating complex auxiliary modules -- such as GANs or reward models -- to restore visual fidelity. In this work, we introduce Continuous-Time Distribution Matching (CDM), migrating the DMD framework from discrete anchoring to continuous optimization for the first time. CDM achieves this through two continuous-time designs. First, we replace the fixed discrete schedule with a dynamic continuous schedule of random length, so that distribution matching is enforced at arbitrary points along sampling trajectories rather than only at a few fixed anchors. Second, we propose a continuous-time alignment objective that performs active off-trajectory matching on latents extrapolated via the student's velocity field, improving generalization and preserving fine visual details. Extensive experiments on different architectures, including SD3-Medium and Longcat-Image, demonstrate that CDM provides highly competitive visual fidelity for few-step image generation without relying on complex auxiliary objectives. Code is available at https://github.com/byliutao/cdm.
Tstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
Anchor Token Matching: Implicit Structure Locking for Training-free AR Image Editing
Apr 14, 2025



Text-to-image generation has seen groundbreaking advancements with diffusion models, enabling high-fidelity synthesis and precise image editing through cross-attention manipulation. Recently, autoregressive (AR) models have re-emerged as powerful alternatives, leveraging next-token generation to match diffusion models. However, existing editing techniques designed for diffusion models fail to translate directly to AR models due to fundamental differences in structural control. Specifically, AR models suffer from spatial poverty of attention maps and sequential accumulation of structural errors during image editing, which disrupt object layouts and global consistency. In this work, we introduce Implicit Structure Locking (ISLock), the first training-free editing strategy for AR visual models. Rather than relying on explicit attention manipulation or fine-tuning, ISLock preserves structural blueprints by dynamically aligning self-attention patterns with reference images through the Anchor Token Matching (ATM) protocol. By implicitly enforcing structural consistency in latent space, our method ISLock enables structure-aware editing while maintaining generative autonomy. Extensive experiments demonstrate that ISLock achieves high-quality, structure-consistent edits without additional training and is superior or comparable to conventional editing techniques. Our findings pioneer the way for efficient and flexible AR-based image editing, further bridging the performance gap between diffusion and autoregressive generative models. The code will be publicly available at https://github.com/hutaiHang/ATM
Token Merging for Training-Free Semantic Binding in Text-to-Image Synthesis
Nov 11, 2024



Although text-to-image (T2I) models exhibit remarkable generation capabilities, they frequently fail to accurately bind semantically related objects or attributes in the input prompts; a challenge termed semantic binding. Previous approaches either involve intensive fine-tuning of the entire T2I model or require users or large language models to specify generation layouts, adding complexity. In this paper, we define semantic binding as the task of associating a given object with its attribute, termed attribute binding, or linking it to other related sub-objects, referred to as object binding. We introduce a novel method called Token Merging (ToMe), which enhances semantic binding by aggregating relevant tokens into a single composite token. This ensures that the object, its attributes and sub-objects all share the same cross-attention map. Additionally, to address potential confusion among main objects with complex textual prompts, we propose end token substitution as a complementary strategy. To further refine our approach in the initial stages of T2I generation, where layouts are determined, we incorporate two auxiliary losses, an entropy loss and a semantic binding loss, to iteratively update the composite token to improve the generation integrity. We conducted extensive experiments to validate the effectiveness of ToMe, comparing it against various existing methods on the T2I-CompBench and our proposed GPT-4o object binding benchmark. Our method is particularly effective in complex scenarios that involve multiple objects and attributes, which previous methods often fail to address. The code will be publicly available at \url{https://github.com/hutaihang/ToMe}.
Meta-Unlearning on Diffusion Models: Preventing Relearning Unlearned Concepts
Oct 16, 2024



With the rapid progress of diffusion-based content generation, significant efforts are being made to unlearn harmful or copyrighted concepts from pretrained diffusion models (DMs) to prevent potential model misuse. However, it is observed that even when DMs are properly unlearned before release, malicious finetuning can compromise this process, causing DMs to relearn the unlearned concepts. This occurs partly because certain benign concepts (e.g., "skin") retained in DMs are related to the unlearned ones (e.g., "nudity"), facilitating their relearning via finetuning. To address this, we propose meta-unlearning on DMs. Intuitively, a meta-unlearned DM should behave like an unlearned DM when used as is; moreover, if the meta-unlearned DM undergoes malicious finetuning on unlearned concepts, the related benign concepts retained within it will be triggered to self-destruct, hindering the relearning of unlearned concepts. Our meta-unlearning framework is compatible with most existing unlearning methods, requiring only the addition of an easy-to-implement meta objective. We validate our approach through empirical experiments on meta-unlearning concepts from Stable Diffusion models (SD-v1-4 and SDXL), supported by extensive ablation studies. Our code is available at https://github.com/sail-sg/Meta-Unlearning.
Get What You Want, Not What You Don't: Image Content Suppression for Text-to-Image Diffusion Models
Feb 08, 2024
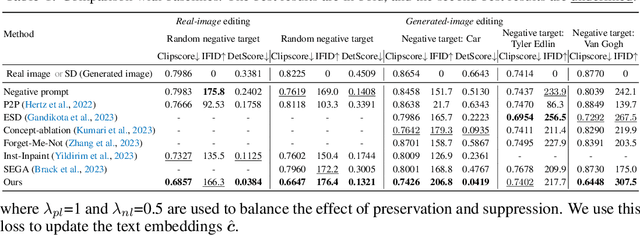
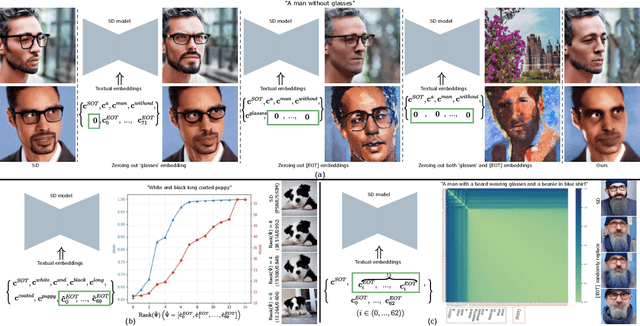
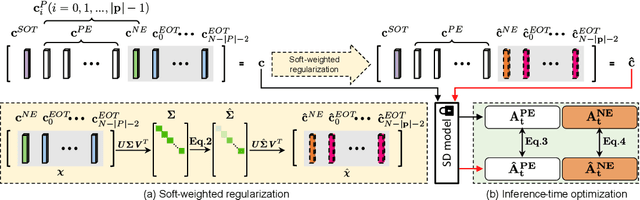
The success of recent text-to-image diffusion models is largely due to their capacity to be guided by a complex text prompt, which enables users to precisely describe the desired content. However, these models struggle to effectively suppress the generation of undesired content, which is explicitly requested to be omitted from the generated image in the prompt. In this paper, we analyze how to manipulate the text embeddings and remove unwanted content from them. We introduce two contributions, which we refer to as $\textit{soft-weighted regularization}$ and $\textit{inference-time text embedding optimization}$. The first regularizes the text embedding matrix and effectively suppresses the undesired content. The second method aims to further suppress the unwanted content generation of the prompt, and encourages the generation of desired content. We evaluate our method quantitatively and qualitatively on extensive experiments, validating its effectiveness. Furthermore, our method is generalizability to both the pixel-space diffusion models (i.e. DeepFloyd-IF) and the latent-space diffusion models (i.e. Stable Diffusion).
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
Dec 15, 2023



One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored. In this work, we conduct the first comprehensive study of the UNet encoder. We empirically analyze the encoder features and provide insights to important questions regarding their changes at the inference process. In particular, we find that encoder features change gently, whereas the decoder features exhibit substantial variations across different time-steps. This finding inspired us to omit the encoder at certain adjacent time-steps and reuse cyclically the encoder features in the previous time-steps for the decoder. Further based on this observation, we introduce a simple yet effective encoder propagation scheme to accelerate the diffusion sampling for a diverse set of tasks. By benefiting from our propagation scheme, we are able to perform in parallel the decoder at certain adjacent time-steps. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and the DeepFloyd-IF models sampling by 41$\%$ and 24$\%$ respectively, while maintaining high-quality generation performance. Our code is available in \href{https://github.com/hutaiHang/Faster-Diffusion}{FasterDiffusion}.
StyleDiffusion: Prompt-Embedding Inversion for Text-Based Editing
Mar 28, 2023



A significant research effort is focused on exploiting the amazing capacities of pretrained diffusion models for the editing of images. They either finetune the model, or invert the image in the latent space of the pretrained model. However, they suffer from two problems: (1) Unsatisfying results for selected regions, and unexpected changes in nonselected regions. (2) They require careful text prompt editing where the prompt should include all visual objects in the input image. To address this, we propose two improvements: (1) Only optimizing the input of the value linear network in the cross-attention layers, is sufficiently powerful to reconstruct a real image. (2) We propose attention regularization to preserve the object-like attention maps after editing, enabling us to obtain accurate style editing without invoking significant structural changes. We further improve the editing technique which is used for the unconditional branch of classifier-free guidance, as well as the conditional one as used by P2P. Extensive experimental prompt-editing results on a variety of images, demonstrate qualitatively and quantitatively that our method has superior editing capabilities than existing and concurrent works.