 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Images, No Problem: Retaining Knowledge in Continual VQA with Questions-Only Memory
Feb 06, 2025Continual Learning in Visual Question Answering (VQACL) requires models to learn new visual-linguistic tasks (plasticity) while retaining knowledge from previous tasks (stability). The multimodal nature of VQACL presents unique challenges, requiring models to balance stability across visual and textual domains while maintaining plasticity to adapt to novel objects and reasoning tasks. Existing methods, predominantly designed for unimodal tasks, often struggle to balance these demands effectively. In this work, we introduce QUestion-only replay with Attention Distillation (QUAD), a novel approach for VQACL that leverages only past task questions for regularisation, eliminating the need to store visual data and addressing both memory and privacy concerns. QUAD achieves stability by introducing a question-only replay mechanism that selectively uses questions from previous tasks to prevent overfitting to the current task's answer space, thereby mitigating the out-of-answer-set problem. Complementing this, we propose attention consistency distillation, which uniquely enforces both intra-modal and inter-modal attention consistency across tasks, preserving essential visual-linguistic associations. Extensive experiments on VQAv2 and NExT-QA demonstrate that QUAD significantly outperforms state-of-the-art methods, achieving robust performance in continual VQA.
Assessing Open-world Forgetting in Generative Image Model Customization
Oct 18, 2024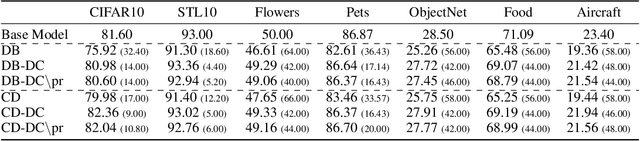
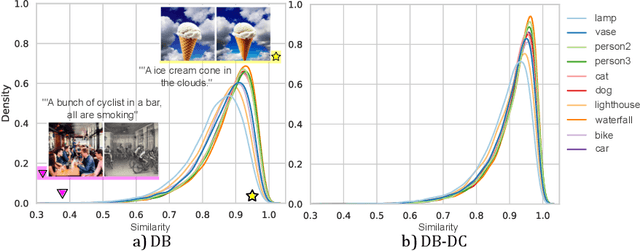


Recent advances in diffusion models have significantly enhanced image generation capabilities. However, customizing these models with new classes often leads to unintended consequences that compromise their reliability. We introduce the concept of open-world forgetting to emphasize the vast scope of these unintended alterations, contrasting it with the well-studied closed-world forgetting, which is measurable by evaluating performance on a limited set of classes or skills. Our research presents the first comprehensive investigation into open-world forgetting in diffusion models, focusing on semantic and appearance drift of representations. We utilize zero-shot classification to analyze semantic drift, revealing that even minor model adaptations lead to unpredictable shifts affecting areas far beyond newly introduced concepts, with dramatic drops in zero-shot classification of up to 60%. Additionally, we observe significant changes in texture and color of generated content when analyzing appearance drift. To address these issues, we propose a mitigation strategy based on functional regularization, designed to preserve original capabilities while accommodating new concepts. Our study aims to raise awareness of unintended changes due to model customization and advocates for the analysis of open-world forgetting in future research on model customization and finetuning methods. Furthermore, we provide insights for developing more robust adaptation methodologies.
Weighted Ensemble Models Are Strong Continual Learners
Dec 14, 2023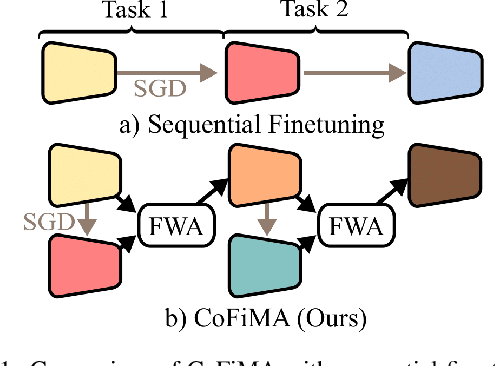
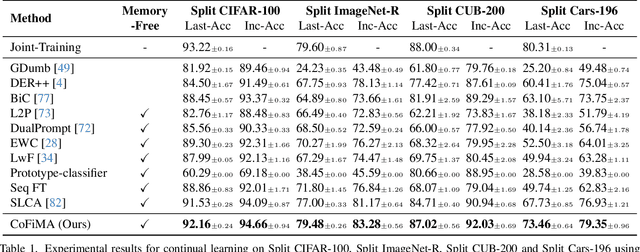
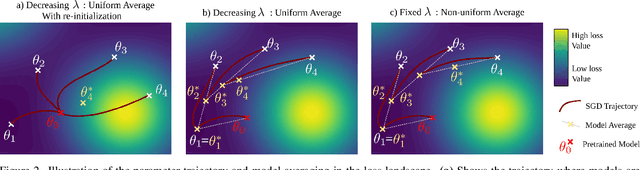
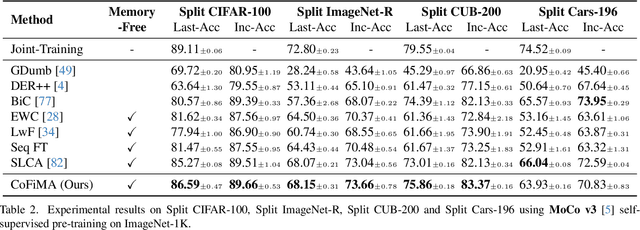
In this work, we study the problem of continual learning (CL) where the goal is to learn a model on a sequence of tasks, such that the data from the previous tasks becomes unavailable while learning on the current task data. CL is essentially a balancing act between being able to learn on the new task (i.e., plasticity) and maintaining the performance on the previously learned concepts (i.e., stability). With an aim to address the stability-plasticity trade-off, we propose to perform weight-ensembling of the model parameters of the previous and current task. This weight-ensembled model, which we call Continual Model Averaging (or CoMA), attains high accuracy on the current task by leveraging plasticity, while not deviating too far from the previous weight configuration, ensuring stability. We also propose an improved variant of CoMA, named Continual Fisher-weighted Model Averaging (or CoFiMA), that selectively weighs each parameter in the weight ensemble by leveraging the Fisher information of the weights of the model. Both the variants are conceptually simple, easy to implement, and effective in attaining state-of-the-art performance on several standard CL benchmarks.
Mini but Mighty: Finetuning ViTs with Mini Adapters
Nov 07, 2023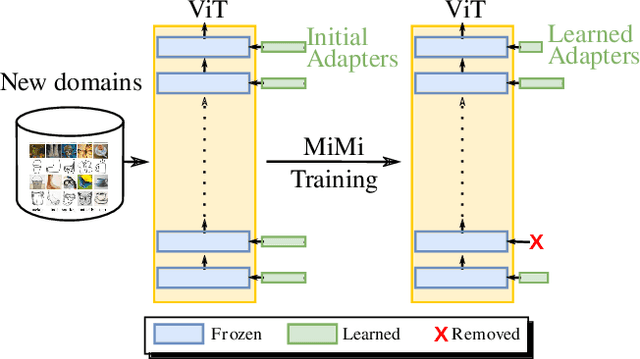
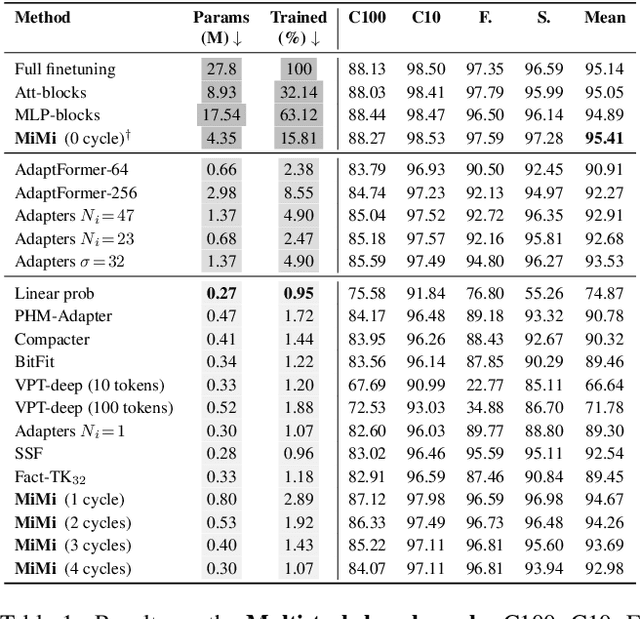
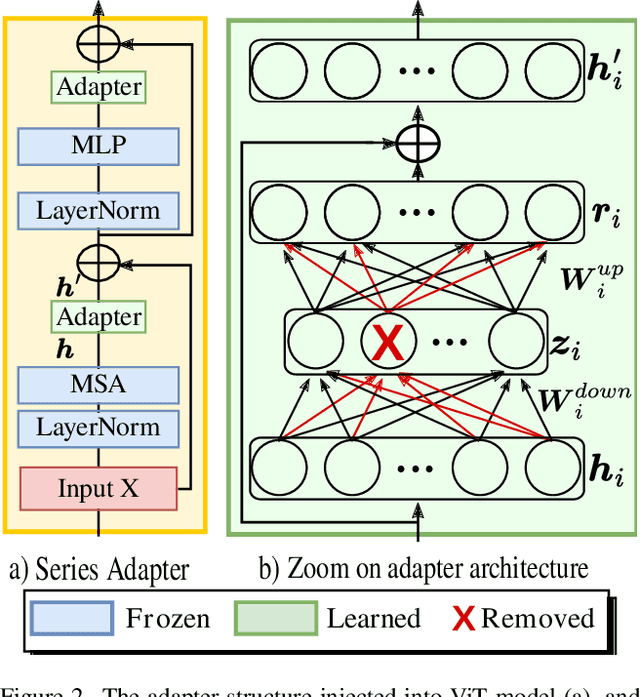
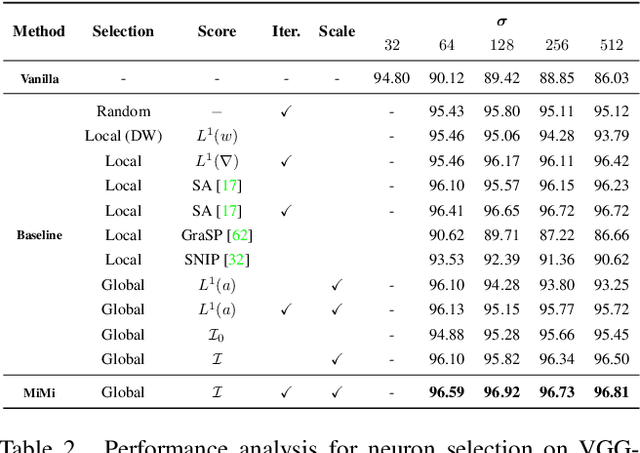
Vision Transformers (ViTs) have become one of the dominant architectures in computer vision, and pre-trained ViT models are commonly adapted to new tasks via fine-tuning. Recent works proposed several parameter-efficient transfer learning methods, such as adapters, to avoid the prohibitive training and storage cost of finetuning. In this work, we observe that adapters perform poorly when the dimension of adapters is small, and we propose MiMi, a training framework that addresses this issue. We start with large adapters which can reach high performance, and iteratively reduce their size. To enable automatic estimation of the hidden dimension of every adapter, we also introduce a new scoring function, specifically designed for adapters, that compares the neuron importance across layers. Our method outperforms existing methods in finding the best trade-off between accuracy and trained parameters across the three dataset benchmarks DomainNet, VTAB, and Multi-task, for a total of 29 datasets.
Rethinking Class-incremental Learning in the Era of Large Pre-trained Models via Test-Time Adaptation
Oct 17, 2023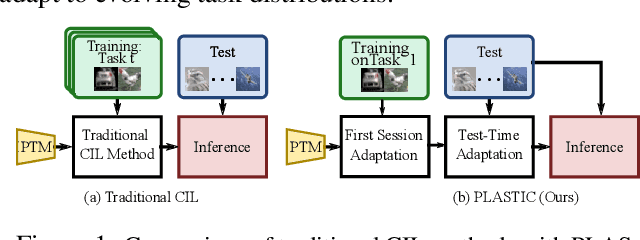
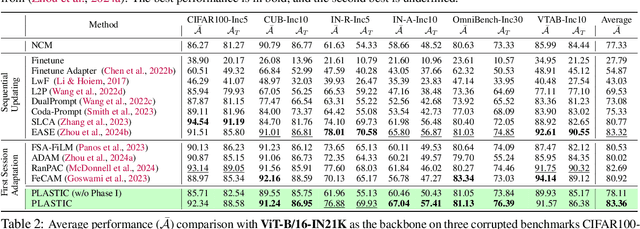
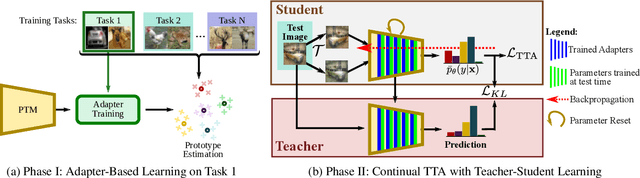

Class-incremental learning (CIL) is a challenging task that involves continually learning to categorize classes into new tasks without forgetting previously learned information. The advent of the large pre-trained models (PTMs) has fast-tracked the progress in CIL due to the highly transferable PTM representations, where tuning a small set of parameters results in state-of-the-art performance when compared with the traditional CIL methods that are trained from scratch. However, repeated fine-tuning on each task destroys the rich representations of the PTMs and further leads to forgetting previous tasks. To strike a balance between the stability and plasticity of PTMs for CIL, we propose a novel perspective of eliminating training on every new task and instead performing test-time adaptation (TTA) directly on the test instances. Concretely, we propose "Test-Time Adaptation for Class-Incremental Learning" (TTACIL) that first fine-tunes Layer Norm parameters of the PTM on each test instance for learning task-specific features, and then resets them back to the base model to preserve stability. As a consequence, TTACIL does not undergo any forgetting, while benefiting each task with the rich PTM features. Additionally, by design, our method is robust to common data corruptions. Our TTACIL outperforms several state-of-the-art CIL methods when evaluated on multiple CIL benchmarks under both clean and corrupted data.