 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualizing Spotify's Audiobook List Recommendations with Descriptive Shelves
Apr 18, 2025In this paper, we propose a pipeline to generate contextualized list recommendations with descriptive shelves in the domain of audiobooks. By creating several shelves for topics the user has an affinity to, e.g. Uplifting Women's Fiction, we can help them explore their recommendations according to their interests and at the same time recommend a diverse set of items. To do so, we use Large Language Models (LLMs) to enrich each item's metadata based on a taxonomy created for this domain. Then we create diverse descriptive shelves for each user. A/B tests show improvements in user engagement and audiobook discovery metrics, demonstrating benefits for users and content creators.
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024


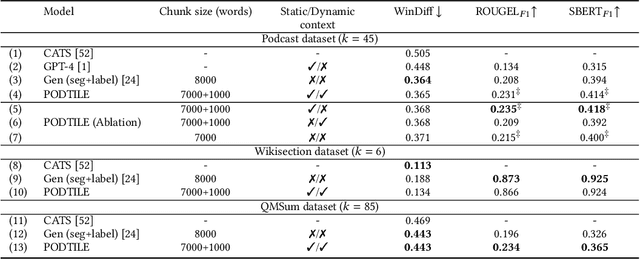
Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.