 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Uncertainty in Short-Term PV Forecasting under Missing Data: A Multiple Imputation Approach
Mar 16, 2026Missing values are common in photovoltaic (PV) power data, yet the uncertainty they induce is not propagated into predictive distributions. We develop a framework that incorporates missing-data uncertainty into short-term PV forecasting by combining stochastic multiple imputation with Rubin's rule. The approach is model-agnostic and can be integrated with standard machine-learning predictors. Empirical results show that ignoring missing-data uncertainty leads to overly narrow prediction intervals. Accounting for this uncertainty improves interval calibration while maintaining comparable point prediction accuracy. These results demonstrate the importance of propagating imputation uncertainty in data-driven PV forecasting.
kNNSampler: Stochastic Imputations for Recovering Missing Value Distributions
Sep 10, 2025We study a missing-value imputation method, termed kNNSampler, that imputes a given unit's missing response by randomly sampling from the observed responses of the $k$ most similar units to the given unit in terms of the observed covariates. This method can sample unknown missing values from their distributions, quantify the uncertainties of missing values, and be readily used for multiple imputation. Unlike popular kNNImputer, which estimates the conditional mean of a missing response given an observed covariate, kNNSampler is theoretically shown to estimate the conditional distribution of a missing response given an observed covariate. Experiments demonstrate its effectiveness in recovering the distribution of missing values. The code for kNNSampler is made publicly available (https://github.com/SAP/knn-sampler).
Variable Selection for Comparing High-dimensional Time-Series Data
Dec 09, 2024



Given a pair of multivariate time-series data of the same length and dimensions, an approach is proposed to select variables and time intervals where the two series are significantly different. In applications where one time series is an output from a computationally expensive simulator, the approach may be used for validating the simulator against real data, for comparing the outputs of two simulators, and for validating a machine learning-based emulator against the simulator. With the proposed approach, the entire time interval is split into multiple subintervals, and on each subinterval, the two sample sets are compared to select variables that distinguish their distributions and a two-sample test is performed. The validity and limitations of the proposed approach are investigated in synthetic data experiments. Its usefulness is demonstrated in an application with a particle-based fluid simulator, where a deep neural network model is compared against the simulator, and in an application with a microscopic traffic simulator, where the effects of changing the simulator's parameters on traffic flows are analysed.
Fast Computation of Leave-One-Out Cross-Validation for $k$-NN Regression
May 08, 2024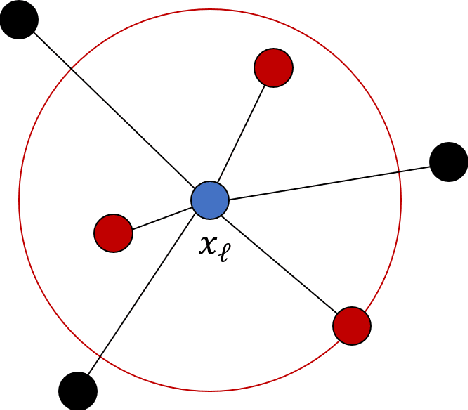
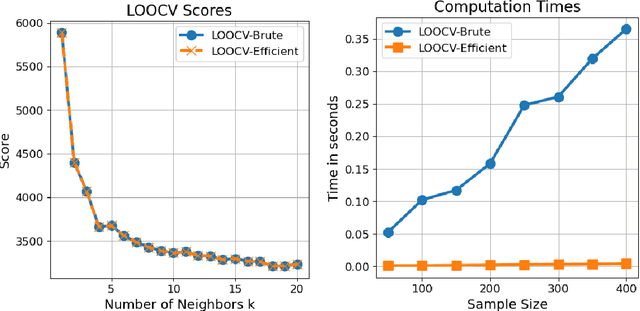
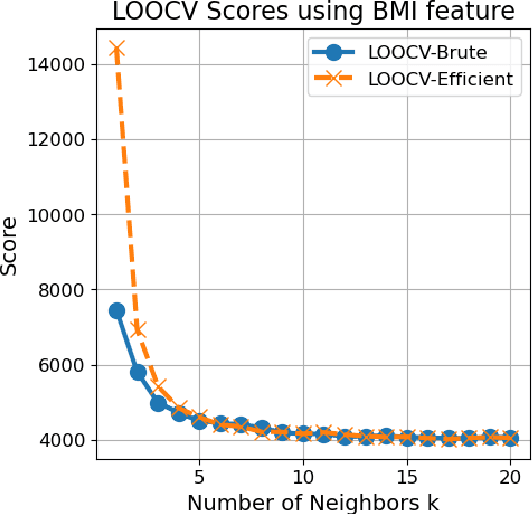
We describe a fast computation method for leave-one-out cross-validation (LOOCV) for $k$-nearest neighbours ($k$-NN) regression. We show that, under a tie-breaking condition for nearest neighbours, the LOOCV estimate of the mean square error for $k$-NN regression is identical to the mean square error of $(k+1)$-NN regression evaluated on the training data, multiplied by the scaling factor $(k+1)^2/k^2$. Therefore, to compute the LOOCV score, one only needs to fit $(k+1)$-NN regression only once, and does not need to repeat training-validation of $k$-NN regression for the number of training data. Numerical experiments confirm the validity of the fast computation method.
Variable Selection in Maximum Mean Discrepancy for Interpretable Distribution Comparison
Nov 02, 2023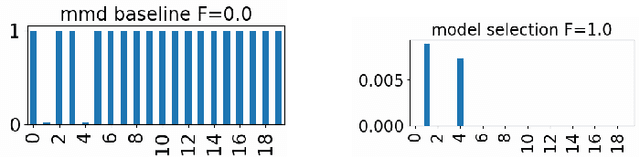



Two-sample testing decides whether two datasets are generated from the same distribution. This paper studies variable selection for two-sample testing, the task being to identify the variables (or dimensions) responsible for the discrepancies between the two distributions. This task is relevant to many problems of pattern analysis and machine learning, such as dataset shift adaptation, causal inference and model validation. Our approach is based on a two-sample test based on the Maximum Mean Discrepancy (MMD). We optimise the Automatic Relevance Detection (ARD) weights defined for individual variables to maximise the power of the MMD-based test. For this optimisation, we introduce sparse regularisation and propose two methods for dealing with the issue of selecting an appropriate regularisation parameter. One method determines the regularisation parameter in a data-driven way, and the other aggregates the results of different regularisation parameters. We confirm the validity of the proposed methods by systematic comparisons with baseline methods, and demonstrate their usefulness in exploratory analysis of high-dimensional traffic simulation data. Preliminary theoretical analyses are also provided, including a rigorous definition of variable selection for two-sample testing.
When is Importance Weighting Correction Needed for Covariate Shift Adaptation?
Mar 07, 2023


This paper investigates when the importance weighting (IW) correction is needed to address covariate shift, a common situation in supervised learning where the input distributions of training and test data differ. Classic results show that the IW correction is needed when the model is parametric and misspecified. In contrast, recent results indicate that the IW correction may not be necessary when the model is nonparametric and well-specified. We examine the missing case in the literature where the model is nonparametric and misspecified, and show that the IW correction is needed for obtaining the best approximation of the true unknown function for the test distribution. We do this by analyzing IW-corrected kernel ridge regression, covering a variety of settings, including parametric and nonparametric models, well-specified and misspecified settings, and arbitrary weighting functions.
Improved Random Features for Dot Product Kernels
Feb 03, 2022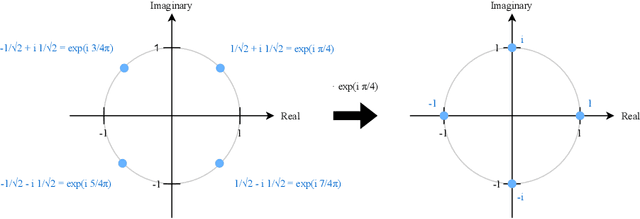

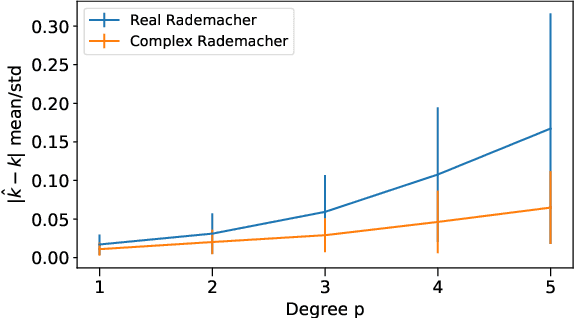
Dot product kernels, such as polynomial and exponential (softmax) kernels, are among the most widely used kernels in machine learning, as they enable modeling the interactions between input features, which is crucial in applications like computer vision, natural language processing, and recommender systems. We make several novel contributions for improving the efficiency of random feature approximations for dot product kernels, to make these kernels more useful in large scale learning. First, we present a generalization of existing random feature approximations for polynomial kernels, such as Rademacher and Gaussian sketches and TensorSRHT, using complex-valued random features. We show empirically that the use of complex features can significantly reduce the variances of these approximations. Second, we provide a theoretical analysis for understanding the factors affecting the efficiency of various random feature approximations, by deriving closed-form expressions for their variances. These variance formulas elucidate conditions under which certain approximations (e.g., TensorSRHT) achieve lower variances than others (e.g., Rademacher sketches), and conditions under which the use of complex features leads to lower variances than real features. Third, by using these variance formulas, which can be evaluated in practice, we develop a data-driven optimization approach to improve random feature approximations for general dot product kernels, which is also applicable to the Gaussian kernel. We describe the improvements brought by these contributions with extensive experiments on a variety of tasks and datasets.
Connections and Equivalences between the Nyström Method and Sparse Variational Gaussian Processes
Jun 02, 2021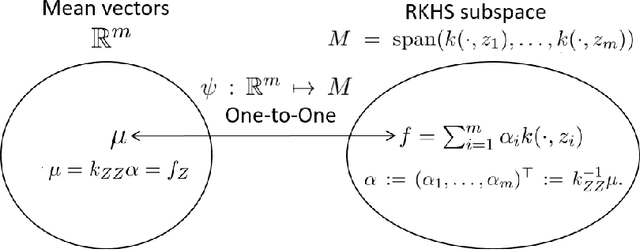
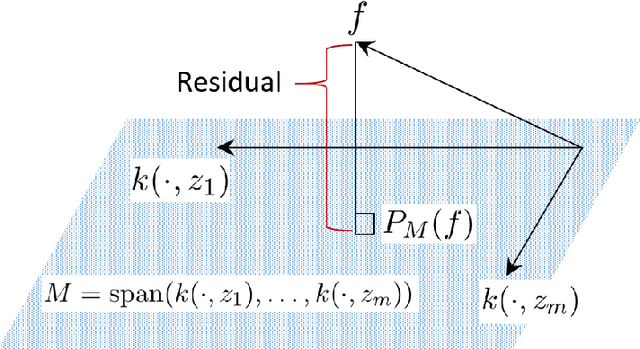
We investigate the connections between sparse approximation methods for making kernel methods and Gaussian processes (GPs) scalable to massive data, focusing on the Nystr\"om method and the Sparse Variational Gaussian Processes (SVGP). While sparse approximation methods for GPs and kernel methods share some algebraic similarities, the literature lacks a deep understanding of how and why they are related. This is a possible obstacle for the communications between the GP and kernel communities, making it difficult to transfer results from one side to the other. Our motivation is to remove this possible obstacle, by clarifying the connections between the sparse approximations for GPs and kernel methods. In this work, we study the two popular approaches, the Nystr\"om and SVGP approximations, in the context of a regression problem, and establish various connections and equivalences between them. In particular, we provide an RKHS interpretation of the SVGP approximation, and show that the Evidence Lower Bound of the SVGP contains the objective function of the Nystr\"om approximation, revealing the origin of the algebraic equivalence between the two approaches. We also study recently established convergence results for the SVGP and how they are related to the approximation quality of the Nystr\"om method.
Convergence Guarantees for Adaptive Bayesian Quadrature Methods
May 24, 2019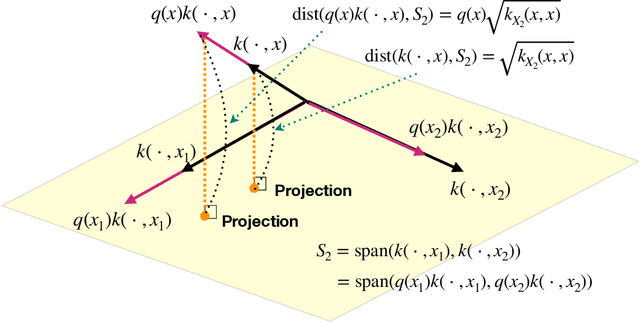
Adaptive Bayesian quadrature (ABQ) is a powerful approach to numerical integration that empirically compares favorably with Monte Carlo integration on problems of medium dimensionality (where non-adaptive quadrature is not competitive). Its key ingredient is an acquisition function that changes as a function of previously collected values of the integrand. While this adaptivity appears to be empirically powerful, it complicates analysis. Consequently, there are no theoretical guarantees so far for this class of methods. In this work, for a broad class of adaptive Bayesian quadrature methods, we prove consistency, deriving non-tight but informative convergence rates. To do so we introduce a new concept we call weak adaptivity. In guaranteeing consistency of ABQ, weak adaptivity is notionally similar to the ideas of detailed balance and ergodicity in Markov Chain Monte Carlo methods, which allow sufficient conditions for consistency of MCMC. Likewise, our results identify a large and flexible class of adaptive Bayesian quadrature rules as consistent, within which practitioners can develop empirically efficient methods.
Model Selection for Simulator-based Statistical Models: A Kernel Approach
Feb 07, 2019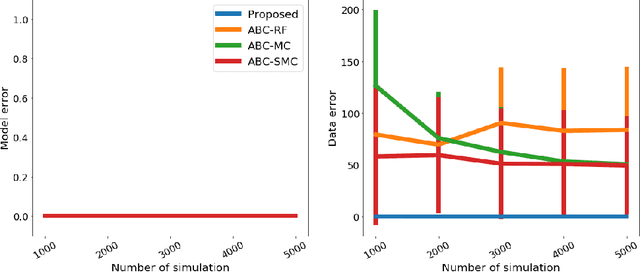
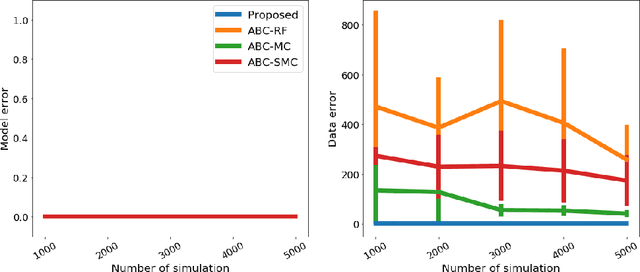
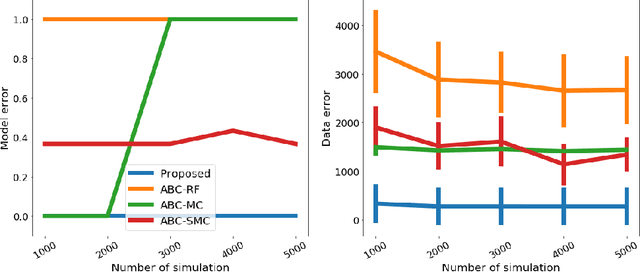
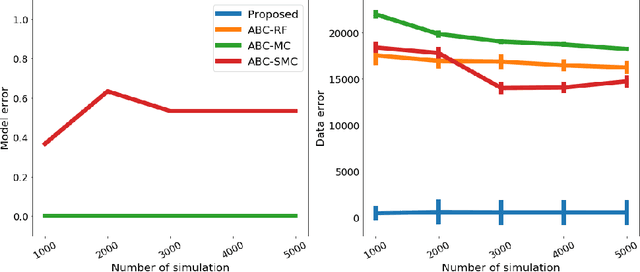
We propose a novel approach to model selection for simulator-based statistical models. The proposed approach defines a mixture of candidate models, and then iteratively updates the weight coefficients for those models as well as the parameters in each model simultaneously; this is done by recursively applying Bayes' rule, using the recently proposed kernel recursive ABC algorithm. The practical advantage of the method is that it can be used even when a modeler lacks appropriate prior knowledge about the parameters in each model. We demonstrate the effectiveness of the proposed approach with a number of experiments, including model selection for dynamical systems in ecology and epidemiology.