 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Random Feature Approximations of the Gaussian Kernel
Apr 12, 2022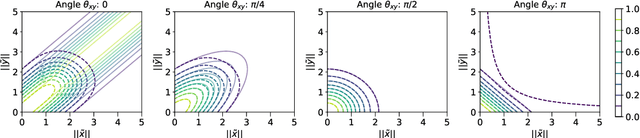

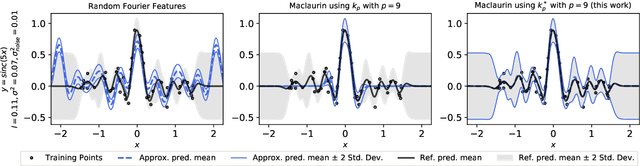
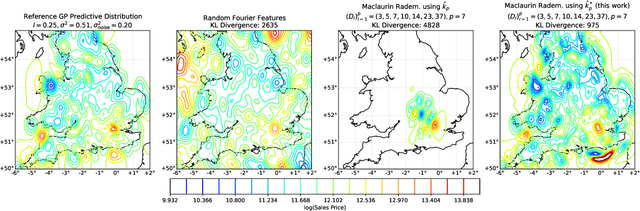
A fundamental drawback of kernel-based statistical models is their limited scalability to large data sets, which requires resorting to approximations. In this work, we focus on the popular Gaussian kernel and on techniques to linearize kernel-based models by means of random feature approximations. In particular, we do so by studying a less explored random feature approximation based on Maclaurin expansions and polynomial sketches. We show that such approaches yield poor results when modelling high-frequency data, and we propose a novel localization scheme that improves kernel approximations and downstream performance significantly in this regime. We demonstrate these gains on a number of experiments involving the application of Gaussian process regression to synthetic and real-world data of different data sizes and dimensions.
Complex-to-Real Random Features for Polynomial Kernels
Feb 10, 2022
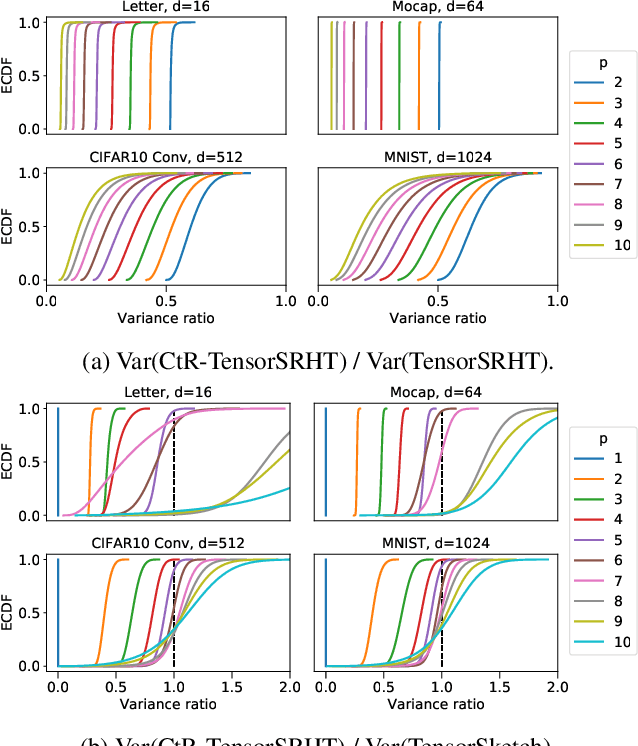
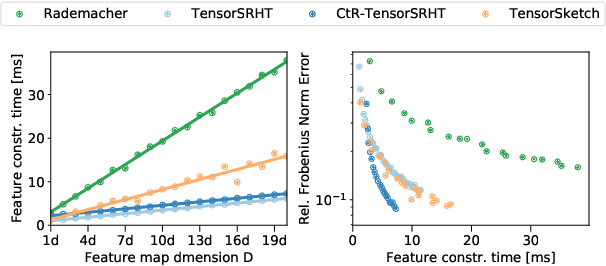

Kernel methods are ubiquitous in statistical modeling due to their theoretical guarantees as well as their competitive empirical performance. Polynomial kernels are of particular importance as their feature maps model the interactions between the dimensions of the input data. However, the construction time of explicit feature maps scales exponentially with the polynomial degree and a naive application of the kernel trick does not scale to large datasets. In this work, we propose Complex-to-Real (CtR) random features for polynomial kernels that leverage intermediate complex random projections and can yield kernel estimates with much lower variances than their real-valued analogs. The resulting features are real-valued, simple to construct and have the following advantages over the state-of-the-art: 1) shorter construction times, 2) lower kernel approximation errors for commonly used degrees, 3) they enable us to obtain a closed-form expression for their variance.
Improved Random Features for Dot Product Kernels
Feb 03, 2022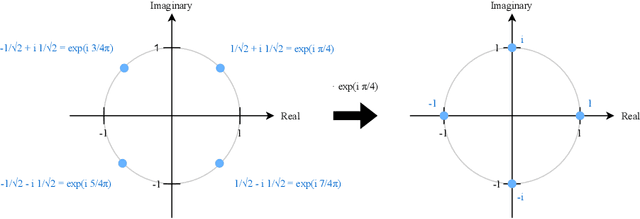

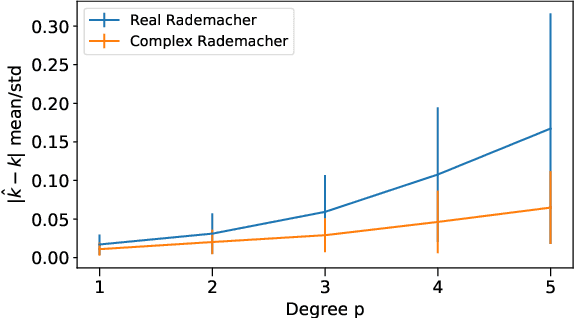
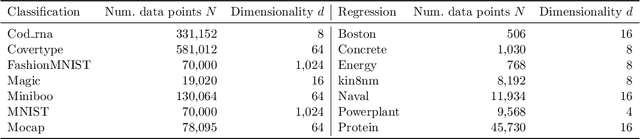
Dot product kernels, such as polynomial and exponential (softmax) kernels, are among the most widely used kernels in machine learning, as they enable modeling the interactions between input features, which is crucial in applications like computer vision, natural language processing, and recommender systems. We make several novel contributions for improving the efficiency of random feature approximations for dot product kernels, to make these kernels more useful in large scale learning. First, we present a generalization of existing random feature approximations for polynomial kernels, such as Rademacher and Gaussian sketches and TensorSRHT, using complex-valued random features. We show empirically that the use of complex features can significantly reduce the variances of these approximations. Second, we provide a theoretical analysis for understanding the factors affecting the efficiency of various random feature approximations, by deriving closed-form expressions for their variances. These variance formulas elucidate conditions under which certain approximations (e.g., TensorSRHT) achieve lower variances than others (e.g., Rademacher sketches), and conditions under which the use of complex features leads to lower variances than real features. Third, by using these variance formulas, which can be evaluated in practice, we develop a data-driven optimization approach to improve random feature approximations for general dot product kernels, which is also applicable to the Gaussian kernel. We describe the improvements brought by these contributions with extensive experiments on a variety of tasks and datasets.
Transfer Learning for Brain Tumor Segmentation
Dec 28, 2019
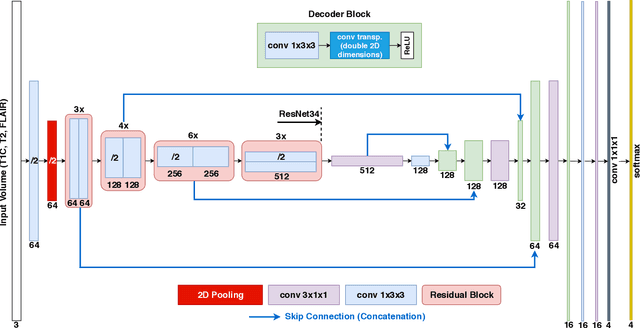
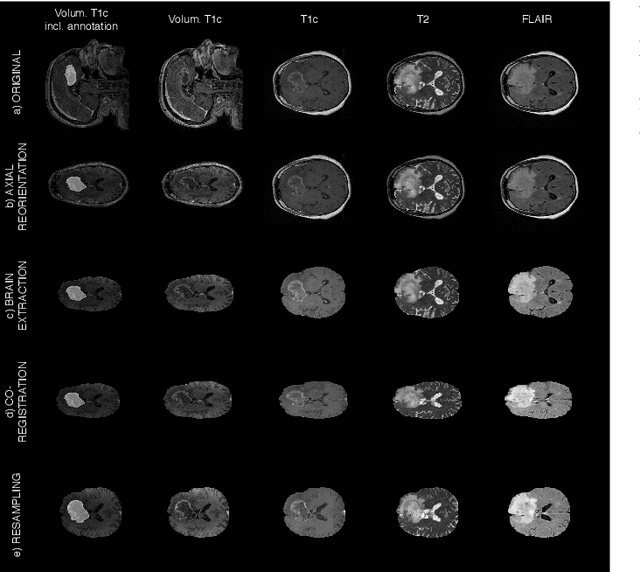

Gliomas are the most common malignant brain tumors that are treated with chemoradiotherapy and surgery. Magnetic Resonance Imaging (MRI) is used by radiotherapists to manually segment brain lesions and to observe their development throughout the therapy. The manual image segmentation process is time-consuming and results tend to vary among different human raters. Therefore, there is a substantial demand for automatic image segmentation algorithms that produce a reliable and accurate segmentation of various brain tissue types. Recent advances in deep learning have led to convolutional neural network architectures that excel at various visual recognition tasks. They have been successfully applied to the medical context including medical image segmentation. In particular, fully convolutional networks (FCNs) such as the U-Net produce state-of-the-art results in the automatic segmentation of brain tumors. MRI brain scans are volumetric and exist in various co-registered modalities that serve as input channels for these FCN architectures. Training algorithms for brain tumor segmentation on this complex input requires large amounts of computational resources and is prone to overfitting. In this work, we construct FCNs with pretrained convolutional encoders. We show that we can stabilize the training process this way and produce more robust predictions. We evaluate our methods on publicly available data as well as on a privately acquired clinical dataset. We also show that the impact of pretraining is even higher for predictions on the clinical data.
Kernel computations from large-scale random features obtained by Optical Processing Units
Dec 02, 2019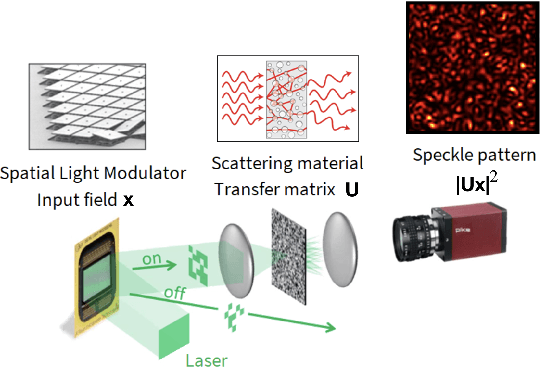

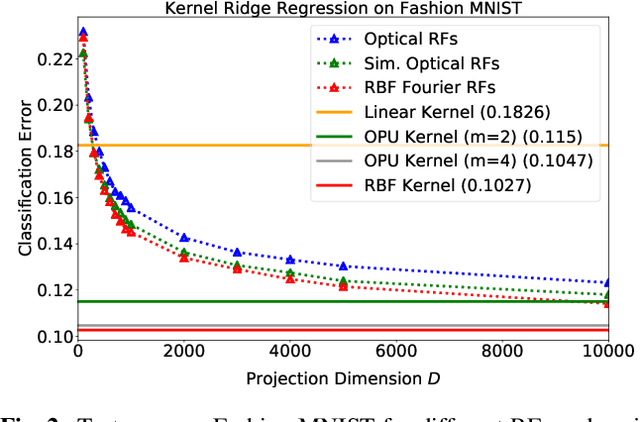
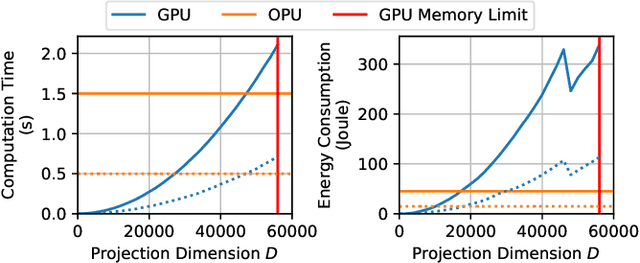
Approximating kernel functions with random features (RFs)has been a successful application of random projections for nonparametric estimation. However, performing random projections presents computational challenges for large-scale problems. Recently, a new optical hardware called Optical Processing Unit (OPU) has been developed for fast and energy-efficient computation of large-scale RFs in the analog domain. More specifically, the OPU performs the multiplication of input vectors by a large random matrix with complex-valued i.i.d. Gaussian entries, followed by the application of an element-wise squared absolute value operation - this last nonlinearity being intrinsic to the sensing process. In this paper, we show that this operation results in a dot-product kernel that has connections to the polynomial kernel, and we extend this computation to arbitrary powers of the feature map. Experiments demonstrate that the OPU kernel and its RF approximation achieve competitive performance in applications using kernel ridge regression and transfer learning for image classification. Crucially, thanks to the use of the OPU, these results are obtained with time and energy savings.