 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel computations from large-scale random features obtained by Optical Processing Units
Dec 02, 2019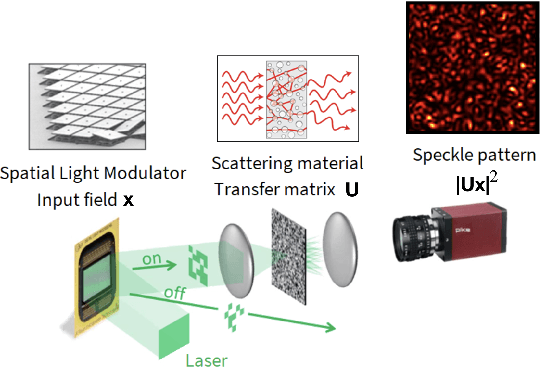

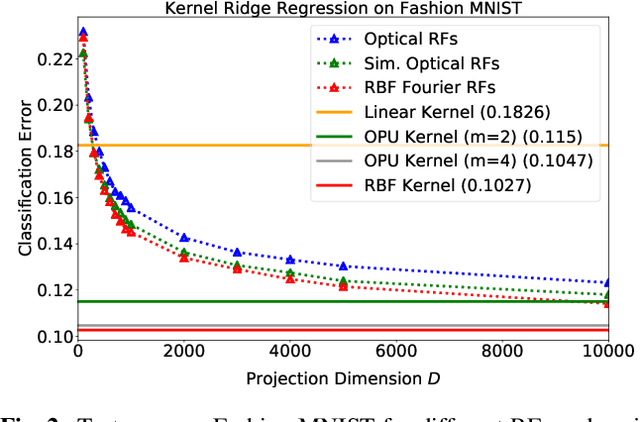
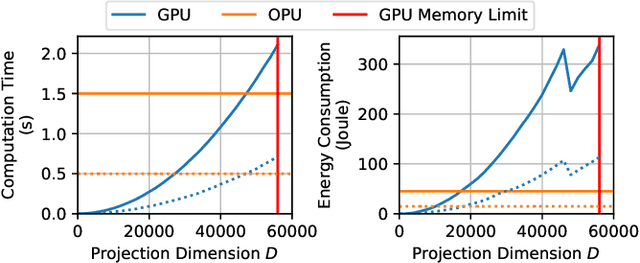
Approximating kernel functions with random features (RFs)has been a successful application of random projections for nonparametric estimation. However, performing random projections presents computational challenges for large-scale problems. Recently, a new optical hardware called Optical Processing Unit (OPU) has been developed for fast and energy-efficient computation of large-scale RFs in the analog domain. More specifically, the OPU performs the multiplication of input vectors by a large random matrix with complex-valued i.i.d. Gaussian entries, followed by the application of an element-wise squared absolute value operation - this last nonlinearity being intrinsic to the sensing process. In this paper, we show that this operation results in a dot-product kernel that has connections to the polynomial kernel, and we extend this computation to arbitrary powers of the feature map. Experiments demonstrate that the OPU kernel and its RF approximation achieve competitive performance in applications using kernel ridge regression and transfer learning for image classification. Crucially, thanks to the use of the OPU, these results are obtained with time and energy savings.
Variational Calibration of Computer Models
Oct 29, 2018



Bayesian calibration of black-box computer models offers an established framework to obtain a posterior distribution over model parameters. Traditional Bayesian calibration involves the emulation of the computer model and an additive model discrepancy term using Gaussian processes; inference is then carried out using MCMC. These choices pose computational and statistical challenges and limitations, which we overcome by proposing the use of approximate Deep Gaussian processes and variational inference techniques. The result is a practical and scalable framework for calibration, which obtains competitive performance compared to the state-of-the-art.
Differentiating the multipoint Expected Improvement for optimal batch design
May 23, 2018


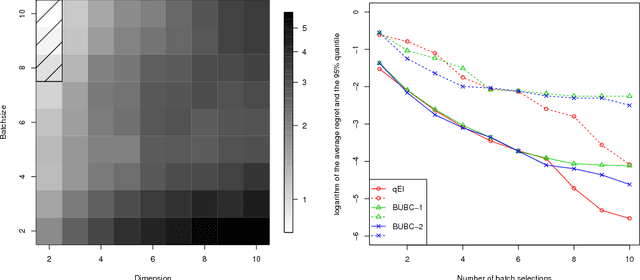
This work deals with parallel optimization of expensive objective functions which are modeled as sample realizations of Gaussian processes. The study is formalized as a Bayesian optimization problem, or continuous multi-armed bandit problem, where a batch of q > 0 arms is pulled in parallel at each iteration. Several algorithms have been developed for choosing batches by trading off exploitation and exploration. As of today, the maximum Expected Improvement (EI) and Upper Confidence Bound (UCB) selection rules appear as the most prominent approaches for batch selection. Here, we build upon recent work on the multipoint Expected Improvement criterion, for which an analytic expansion relying on Tallis' formula was recently established. The computational burden of this selection rule being still an issue in application, we derive a closed-form expression for the gradient of the multipoint Expected Improvement, which aims at facilitating its maximization using gradient-based ascent algorithms. Substantial computational savings are shown in application. In addition, our algorithms are tested numerically and compared to state-of-the-art UCB-based batch-sequential algorithms. Combining starting designs relying on UCB with gradient-based EI local optimization finally appears as a sound option for batch design in distributed Gaussian Process optimization.
Efficient batch-sequential Bayesian optimization with moments of truncated Gaussian vectors
Sep 09, 2016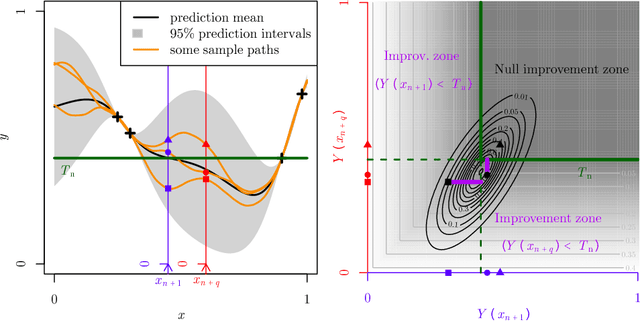


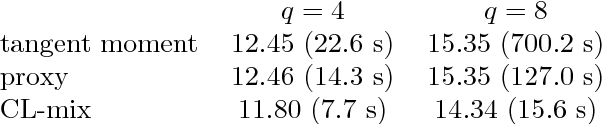
We deal with the efficient parallelization of Bayesian global optimization algorithms, and more specifically of those based on the expected improvement criterion and its variants. A closed form formula relying on multivariate Gaussian cumulative distribution functions is established for a generalized version of the multipoint expected improvement criterion. In turn, the latter relies on intermediate results that could be of independent interest concerning moments of truncated Gaussian vectors. The obtained expansion of the criterion enables studying its differentiability with respect to point batches and calculating the corresponding gradient in closed form. Furthermore , we derive fast numerical approximations of this gradient and propose efficient batch optimization strategies. Numerical experiments illustrate that the proposed approaches enable computational savings of between one and two order of magnitudes, hence enabling derivative-based batch-sequential acquisition function maximization to become a practically implementable and efficient standard.