 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiating the multipoint Expected Improvement for optimal batch design
May 23, 2018


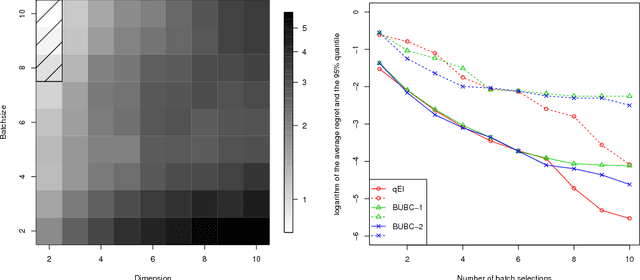
This work deals with parallel optimization of expensive objective functions which are modeled as sample realizations of Gaussian processes. The study is formalized as a Bayesian optimization problem, or continuous multi-armed bandit problem, where a batch of q > 0 arms is pulled in parallel at each iteration. Several algorithms have been developed for choosing batches by trading off exploitation and exploration. As of today, the maximum Expected Improvement (EI) and Upper Confidence Bound (UCB) selection rules appear as the most prominent approaches for batch selection. Here, we build upon recent work on the multipoint Expected Improvement criterion, for which an analytic expansion relying on Tallis' formula was recently established. The computational burden of this selection rule being still an issue in application, we derive a closed-form expression for the gradient of the multipoint Expected Improvement, which aims at facilitating its maximization using gradient-based ascent algorithms. Substantial computational savings are shown in application. In addition, our algorithms are tested numerically and compared to state-of-the-art UCB-based batch-sequential algorithms. Combining starting designs relying on UCB with gradient-based EI local optimization finally appears as a sound option for batch design in distributed Gaussian Process optimization.
Adaptive Design of Experiments for Conservative Estimation of Excursion Sets
Apr 10, 2018



We consider a Gaussian process model trained on few evaluations of an expensive-to-evaluate deterministic function and we study the problem of estimating a fixed excursion set of this function. We focus on conservative estimates as they allow control on false positives while minimizing false negatives. We introduce adaptive strategies that sequentially selects new evaluations of the function by reducing the uncertainty on conservative estimates. Following the Stepwise Uncertainty Reduction approach we obtain new evaluations by minimizing adapted criteria. We provide tractable formulae for the conservative criteria and we benchmark the method on random functions generated under the model assumptions in two and five dimensions. Finally the method is applied to a reliability engineering test case. Overall, the proposed strategy of minimizing false negatives in conservative estimation achieves competitive performance both in terms of model based and a-posteriori indicators.
Nested Kriging predictions for datasets with large number of observations
Jul 25, 2017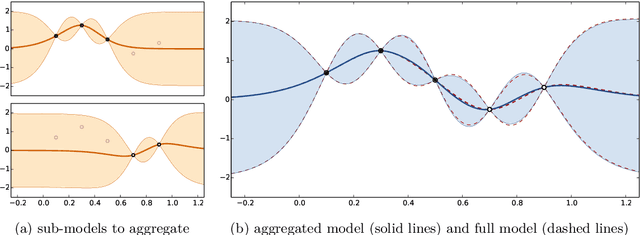



This work falls within the context of predicting the value of a real function at some input locations given a limited number of observations of this function. The Kriging interpolation technique (or Gaussian process regression) is often considered to tackle such a problem but the method suffers from its computational burden when the number of observation points is large. We introduce in this article nested Kriging predictors which are constructed by aggregating sub-models based on subsets of observation points. This approach is proven to have better theoretical properties than other aggregation methods that can be found in the literature. Contrarily to some other methods it can be shown that the proposed aggregation method is consistent. Finally, the practical interest of the proposed method is illustrated on simulated datasets and on an industrial test case with $10^4$ observations in a 6-dimensional space.
Efficient batch-sequential Bayesian optimization with moments of truncated Gaussian vectors
Sep 09, 2016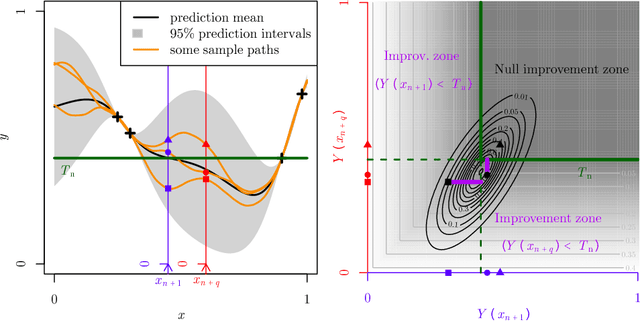


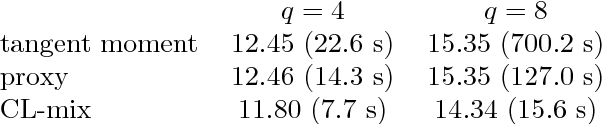
We deal with the efficient parallelization of Bayesian global optimization algorithms, and more specifically of those based on the expected improvement criterion and its variants. A closed form formula relying on multivariate Gaussian cumulative distribution functions is established for a generalized version of the multipoint expected improvement criterion. In turn, the latter relies on intermediate results that could be of independent interest concerning moments of truncated Gaussian vectors. The obtained expansion of the criterion enables studying its differentiability with respect to point batches and calculating the corresponding gradient in closed form. Furthermore , we derive fast numerical approximations of this gradient and propose efficient batch optimization strategies. Numerical experiments illustrate that the proposed approaches enable computational savings of between one and two order of magnitudes, hence enabling derivative-based batch-sequential acquisition function maximization to become a practically implementable and efficient standard.
Quantifying uncertainties on excursion sets under a Gaussian random field prior
Apr 13, 2016



We focus on the problem of estimating and quantifying uncertainties on the excursion set of a function under a limited evaluation budget. We adopt a Bayesian approach where the objective function is assumed to be a realization of a Gaussian random field. In this setting, the posterior distribution on the objective function gives rise to a posterior distribution on excursion sets. Several approaches exist to summarize the distribution of such sets based on random closed set theory. While the recently proposed Vorob'ev approach exploits analytical formulae, further notions of variability require Monte Carlo estimators relying on Gaussian random field conditional simulations. In the present work we propose a method to choose Monte Carlo simulation points and obtain quasi-realizations of the conditional field at fine designs through affine predictors. The points are chosen optimally in the sense that they minimize the posterior expected distance in measure between the excursion set and its reconstruction. The proposed method reduces the computational costs due to Monte Carlo simulations and enables the computation of quasi-realizations on fine designs in large dimensions. We apply this reconstruction approach to obtain realizations of an excursion set on a fine grid which allow us to give a new measure of uncertainty based on the distance transform of the excursion set. Finally we present a safety engineering test case where the simulation method is employed to compute a Monte Carlo estimate of a contour line.
Corrected Kriging update formulae for batch-sequential data assimilation
Mar 29, 2012Recently, a lot of effort has been paid to the efficient computation of Kriging predictors when observations are assimilated sequentially. In particular, Kriging update formulae enabling significant computational savings were derived in Barnes and Watson (1992), Gao et al. (1996), and Emery (2009). Taking advantage of the previous Kriging mean and variance calculations helps avoiding a costly $(n+1) \times (n+1)$ matrix inversion when adding one observation to the $n$ already available ones. In addition to traditional update formulae taking into account a single new observation, Emery (2009) also proposed formulae for the batch-sequential case, i.e. when $r > 1$ new observations are simultaneously assimilated. However, the Kriging variance and covariance formulae given without proof in Emery (2009) for the batch-sequential case are not correct. In this paper we fix this issue and establish corrected expressions for updated Kriging variances and covariances when assimilating several observations in parallel.