 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunQuant: A R package to perform quantization in the context of rare events and time-consuming simulations
Aug 18, 2023



Quantization summarizes continuous distributions by calculating a discrete approximation. Among the widely adopted methods for data quantization is Lloyd's algorithm, which partitions the space into Vorono\"i cells, that can be seen as clusters, and constructs a discrete distribution based on their centroids and probabilistic masses. Lloyd's algorithm estimates the optimal centroids in a minimal expected distance sense, but this approach poses significant challenges in scenarios where data evaluation is costly, and relates to rare events. Then, the single cluster associated to no event takes the majority of the probability mass. In this context, a metamodel is required and adapted sampling methods are necessary to increase the precision of the computations on the rare clusters.
Nested Kriging predictions for datasets with large number of observations
Jul 25, 2017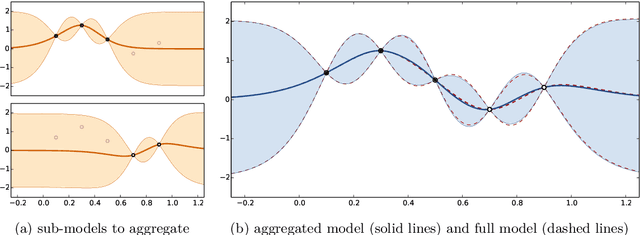



This work falls within the context of predicting the value of a real function at some input locations given a limited number of observations of this function. The Kriging interpolation technique (or Gaussian process regression) is often considered to tackle such a problem but the method suffers from its computational burden when the number of observation points is large. We introduce in this article nested Kriging predictors which are constructed by aggregating sub-models based on subsets of observation points. This approach is proven to have better theoretical properties than other aggregation methods that can be found in the literature. Contrarily to some other methods it can be shown that the proposed aggregation method is consistent. Finally, the practical interest of the proposed method is illustrated on simulated datasets and on an industrial test case with $10^4$ observations in a 6-dimensional space.