 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Approximations for Bayesian Inference in Function Space
Feb 25, 2025We propose a scalable inference algorithm for Bayes posteriors defined on a reproducing kernel Hilbert space (RKHS). Given a likelihood function and a Gaussian random element representing the prior, the corresponding Bayes posterior measure $\Pi_{\text{B}}$ can be obtained as the stationary distribution of an RKHS-valued Langevin diffusion. We approximate the infinite-dimensional Langevin diffusion via a projection onto the first $M$ components of the Kosambi-Karhunen-Lo\`eve expansion. Exploiting the thus obtained approximate posterior for these $M$ components, we perform inference for $\Pi_{\text{B}}$ by relying on the law of total probability and a sufficiency assumption. The resulting method scales as $O(M^3+JM^2)$, where $J$ is the number of samples produced from the posterior measure $\Pi_{\text{B}}$. Interestingly, the algorithm recovers the posterior arising from the sparse variational Gaussian process (SVGP) (see Titsias, 2009) as a special case, owed to the fact that the sufficiency assumption underlies both methods. However, whereas the SVGP is parametrically constrained to be a Gaussian process, our method is based on a non-parametric variational family $\mathcal{P}(\mathbb{R}^M)$ consisting of all probability measures on $\mathbb{R}^M$. As a result, our method is provably close to the optimal $M$-dimensional variational approximation of the Bayes posterior $\Pi_{\text{B}}$ in $\mathcal{P}(\mathbb{R}^M)$ for convex and Lipschitz continuous negative log likelihoods, and coincides with SVGP for the special case of a Gaussian error likelihood.
Variational Gaussian Processes: A Functional Analysis View
Oct 25, 2021Variational Gaussian process (GP) approximations have become a standard tool in fast GP inference. This technique requires a user to select variational features to increase efficiency. So far the common choices in the literature are disparate and lacking generality. We propose to view the GP as lying in a Banach space which then facilitates a unified perspective. This is used to understand the relationship between existing features and to draw a connection between kernel ridge regression and variational GP approximations.
Connections and Equivalences between the Nyström Method and Sparse Variational Gaussian Processes
Jun 02, 2021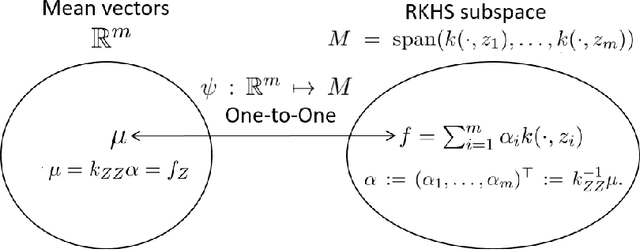
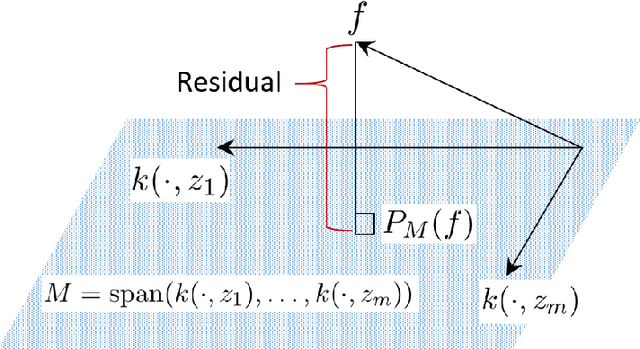
We investigate the connections between sparse approximation methods for making kernel methods and Gaussian processes (GPs) scalable to massive data, focusing on the Nystr\"om method and the Sparse Variational Gaussian Processes (SVGP). While sparse approximation methods for GPs and kernel methods share some algebraic similarities, the literature lacks a deep understanding of how and why they are related. This is a possible obstacle for the communications between the GP and kernel communities, making it difficult to transfer results from one side to the other. Our motivation is to remove this possible obstacle, by clarifying the connections between the sparse approximations for GPs and kernel methods. In this work, we study the two popular approaches, the Nystr\"om and SVGP approximations, in the context of a regression problem, and establish various connections and equivalences between them. In particular, we provide an RKHS interpretation of the SVGP approximation, and show that the Evidence Lower Bound of the SVGP contains the objective function of the Nystr\"om approximation, revealing the origin of the algebraic equivalence between the two approaches. We also study recently established convergence results for the SVGP and how they are related to the approximation quality of the Nystr\"om method.