 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Processes and Kernel Methods: A Review on Connections and Equivalences
Jul 06, 2018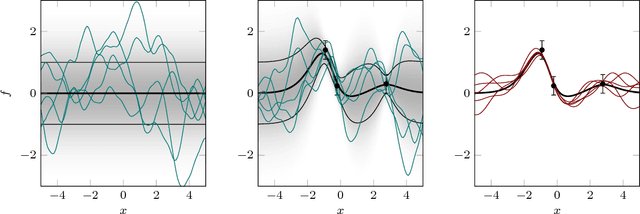

This paper is an attempt to bridge the conceptual gaps between researchers working on the two widely used approaches based on positive definite kernels: Bayesian learning or inference using Gaussian processes on the one side, and frequentist kernel methods based on reproducing kernel Hilbert spaces on the other. It is widely known in machine learning that these two formalisms are closely related; for instance, the estimator of kernel ridge regression is identical to the posterior mean of Gaussian process regression. However, they have been studied and developed almost independently by two essentially separate communities, and this makes it difficult to seamlessly transfer results between them. Our aim is to overcome this potential difficulty. To this end, we review several old and new results and concepts from either side, and juxtapose algorithmic quantities from each framework to highlight close similarities. We also provide discussions on subtle philosophical and theoretical differences between the two approaches.
On the Generalization Ability of Online Learning Algorithms for Pairwise Loss Functions
May 11, 2013
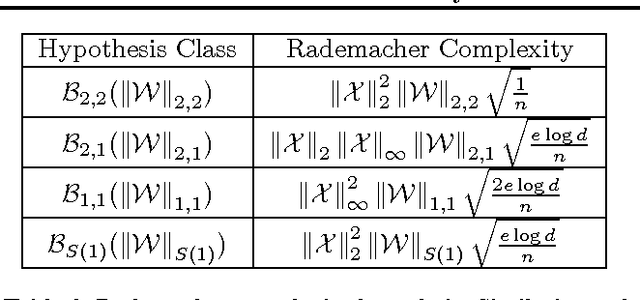


In this paper, we study the generalization properties of online learning based stochastic methods for supervised learning problems where the loss function is dependent on more than one training sample (e.g., metric learning, ranking). We present a generic decoupling technique that enables us to provide Rademacher complexity-based generalization error bounds. Our bounds are in general tighter than those obtained by Wang et al (COLT 2012) for the same problem. Using our decoupling technique, we are further able to obtain fast convergence rates for strongly convex pairwise loss functions. We are also able to analyze a class of memory efficient online learning algorithms for pairwise learning problems that use only a bounded subset of past training samples to update the hypothesis at each step. Finally, in order to complement our generalization bounds, we propose a novel memory efficient online learning algorithm for higher order learning problems with bounded regret guarantees.
* To appear in proceedings of the 30th International Conference on Machine Learning (ICML 2013)