 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAPNet: Plug-in Jointly Learning Task-Specific Graph for Dynamic Stock Relation
Jan 31, 2026The advent of the web has led to a paradigm shift in the financial relations, with the real-time dissemination of news, social discourse, and financial filings contributing significantly to the reshaping of financial forecasting. The existing methods rely on establishing relations a priori, i.e. predefining graphs to capture inter-stock relationships. However, the stock-related web signals are characterised by high levels of noise, asynchrony, and challenging to obtain, resulting in poor generalisability and non-alignment between the predefined graphs and the downstream tasks. To address this, we propose GAPNet, a Graph Adaptation Plug-in Network that jointly learns task-specific topology and representations in an end-to-end manner. GAPNet attaches to existing pairwise graph or hypergraph backbone models, enabling the dynamic adaptation and rewiring of edge topologies via two complementary components: a Spatial Perception Layer that captures short-term co-movements across assets, and a Temporal Perception Layer that maintains long-term dependency under distribution shift. Across two real-world stock datasets, GAPNet has been shown to consistently enhance the profitability and stability in comparision to the state-of-the-art models, yielding annualised cumulative returns of up to 0.47 for RT-GCN and 0.63 for CI-STHPAN, with peak Sharpe Ratio of 2.20 and 2.12 respectively. The plug-and-play design of GAPNet ensures its broad applicability to diverse GNN-based architectures. Our results underscore that jointly learning graph structures and representations is essential for task-specific relational modeling.
NGAT: A Node-level Graph Attention Network for Long-term Stock Prediction
Jul 02, 2025Graph representation learning methods have been widely adopted in financial applications to enhance company representations by leveraging inter-firm relationships. However, current approaches face three key challenges: (1) The advantages of relational information are obscured by limitations in downstream task designs; (2) Existing graph models specifically designed for stock prediction often suffer from excessive complexity and poor generalization; (3) Experience-based construction of corporate relationship graphs lacks effective comparison of different graph structures. To address these limitations, we propose a long-term stock prediction task and develop a Node-level Graph Attention Network (NGAT) specifically tailored for corporate relationship graphs. Furthermore, we experimentally demonstrate the limitations of existing graph comparison methods based on model downstream task performance. Experimental results across two datasets consistently demonstrate the effectiveness of our proposed task and model. The project is publicly available on GitHub to encourage reproducibility and future research.
DRUformer: Enhancing the driving scene Important object detection with driving relationship self-understanding
Nov 11, 2023
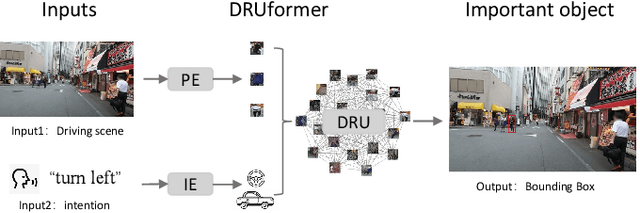
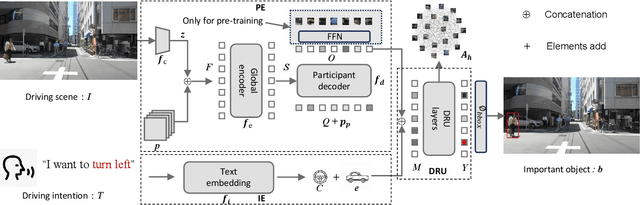
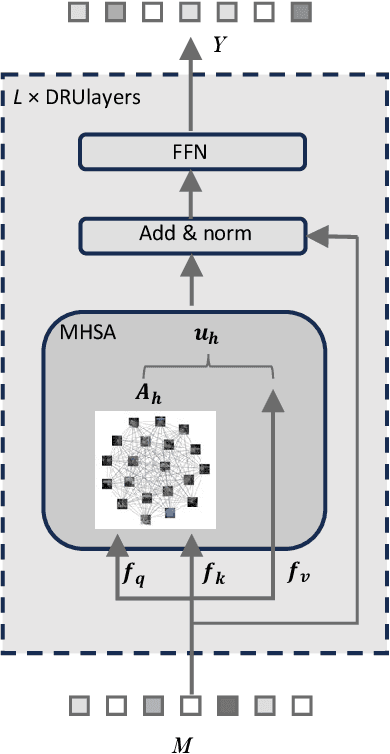
Traffic accidents frequently lead to fatal injuries, contributing to over 50 million deaths until 2023. To mitigate driving hazards and ensure personal safety, it is crucial to assist vehicles in anticipating important objects during travel. Previous research on important object detection primarily assessed the importance of individual participants, treating them as independent entities and frequently overlooking the connections between these participants. Unfortunately, this approach has proven less effective in detecting important objects in complex scenarios. In response, we introduce Driving scene Relationship self-Understanding transformer (DRUformer), designed to enhance the important object detection task. The DRUformer is a transformer-based multi-modal important object detection model that takes into account the relationships between all the participants in the driving scenario. Recognizing that driving intention also significantly affects the detection of important objects during driving, we have incorporated a module for embedding driving intention. To assess the performance of our approach, we conducted a comparative experiment on the DRAMA dataset, pitting our model against other state-of-the-art (SOTA) models. The results demonstrated a noteworthy 16.2\% improvement in mIoU and a substantial 12.3\% boost in ACC compared to SOTA methods. Furthermore, we conducted a qualitative analysis of our model's ability to detect important objects across different road scenarios and classes, highlighting its effectiveness in diverse contexts. Finally, we conducted various ablation studies to assess the efficiency of the proposed modules in our DRUformer model.
R-Cut: Enhancing Explainability in Vision Transformers with Relationship Weighted Out and Cut
Jul 18, 2023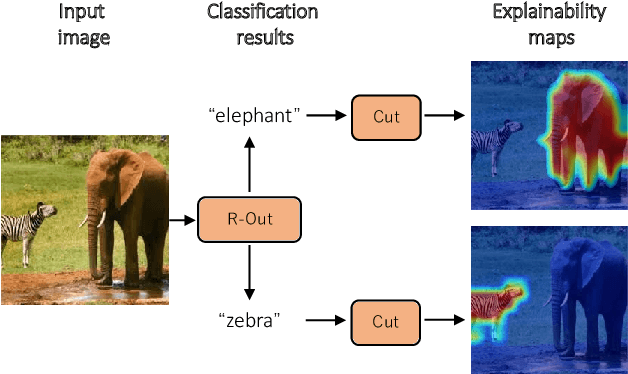
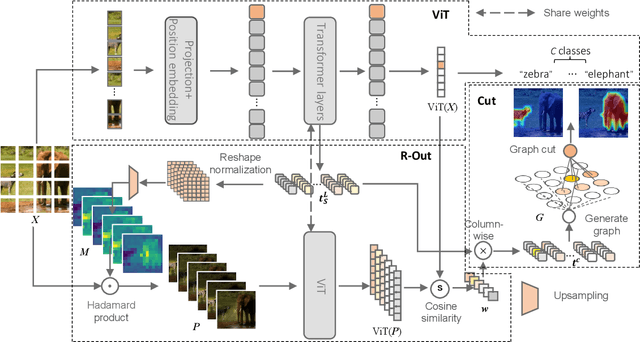


Transformer-based models have gained popularity in the field of natural language processing (NLP) and are extensively utilized in computer vision tasks and multi-modal models such as GPT4. This paper presents a novel method to enhance the explainability of Transformer-based image classification models. Our method aims to improve trust in classification results and empower users to gain a deeper understanding of the model for downstream tasks by providing visualizations of class-specific maps. We introduce two modules: the ``Relationship Weighted Out" and the ``Cut" modules. The ``Relationship Weighted Out" module focuses on extracting class-specific information from intermediate layers, enabling us to highlight relevant features. Additionally, the ``Cut" module performs fine-grained feature decomposition, taking into account factors such as position, texture, and color. By integrating these modules, we generate dense class-specific visual explainability maps. We validate our method with extensive qualitative and quantitative experiments on the ImageNet dataset. Furthermore, we conduct a large number of experiments on the LRN dataset, specifically designed for automatic driving danger alerts, to evaluate the explainability of our method in complex backgrounds. The results demonstrate a significant improvement over previous methods. Moreover, we conduct ablation experiments to validate the effectiveness of each module. Through these experiments, we are able to confirm the respective contributions of each module, thus solidifying the overall effectiveness of our proposed approach.
Learning to Generalize for Cross-domain QA
May 18, 2023



There have been growing concerns regarding the out-of-domain generalization ability of natural language processing (NLP) models, particularly in question-answering (QA) tasks. Current synthesized data augmentation methods for QA are hampered by increased training costs. To address this issue, we propose a novel approach that combines prompting methods and linear probing then fine-tuning strategy, which does not entail additional cost. Our method has been theoretically and empirically shown to be effective in enhancing the generalization ability of both generative and discriminative models. Our approach outperforms state-of-the-art baselines, with an average increase in F1 score of 4.5%-7.9%. Furthermore, our method can be easily integrated into any pre-trained models and offers a promising solution to the under-explored cross-domain QA task. We release our source code at GitHub*.
TsFeX: Contact Tracing Model using Time Series Feature Extraction and Gradient Boosting
Dec 04, 2021
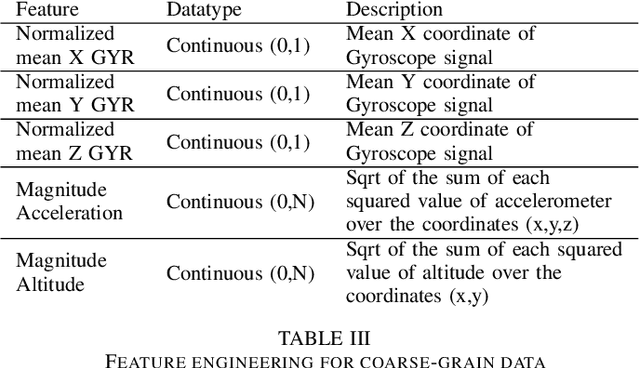
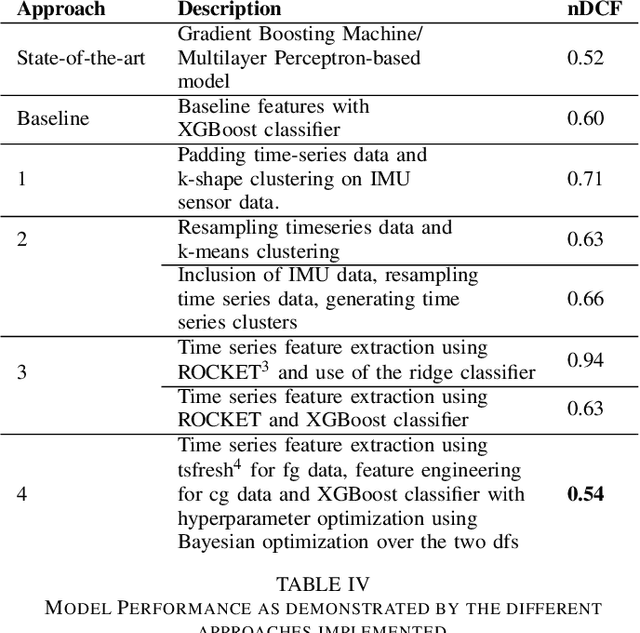
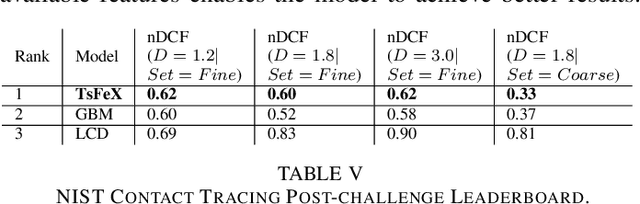
With the outbreak of COVID-19 pandemic, a dire need to effectively identify the individuals who may have come in close-contact to others who have been infected with COVID-19 has risen. This process of identifying individuals, also termed as 'Contact tracing', has significant implications for the containment and control of the spread of this virus. However, manual tracing has proven to be ineffective calling for automated contact tracing approaches. As such, this research presents an automated machine learning system for identifying individuals who may have come in contact with others infected with COVID-19 using sensor data transmitted through handheld devices. This paper describes the different approaches followed in arriving at an optimal solution model that effectually predicts whether a person has been in close proximity to an infected individual using a gradient boosting algorithm and time series feature extraction.