 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRUformer: Enhancing the driving scene Important object detection with driving relationship self-understanding
Nov 11, 2023
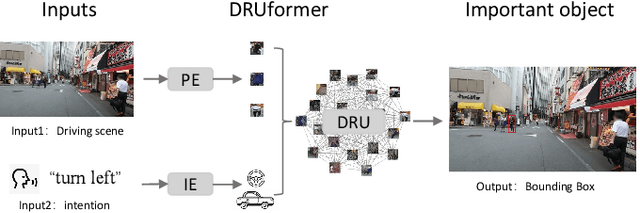
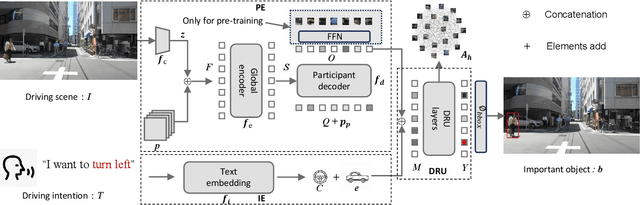
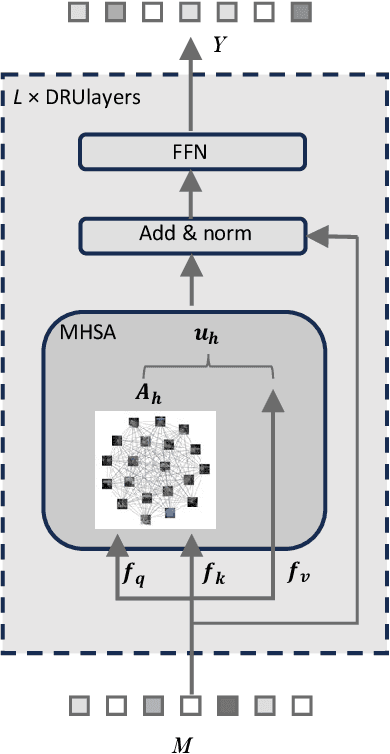
Traffic accidents frequently lead to fatal injuries, contributing to over 50 million deaths until 2023. To mitigate driving hazards and ensure personal safety, it is crucial to assist vehicles in anticipating important objects during travel. Previous research on important object detection primarily assessed the importance of individual participants, treating them as independent entities and frequently overlooking the connections between these participants. Unfortunately, this approach has proven less effective in detecting important objects in complex scenarios. In response, we introduce Driving scene Relationship self-Understanding transformer (DRUformer), designed to enhance the important object detection task. The DRUformer is a transformer-based multi-modal important object detection model that takes into account the relationships between all the participants in the driving scenario. Recognizing that driving intention also significantly affects the detection of important objects during driving, we have incorporated a module for embedding driving intention. To assess the performance of our approach, we conducted a comparative experiment on the DRAMA dataset, pitting our model against other state-of-the-art (SOTA) models. The results demonstrated a noteworthy 16.2\% improvement in mIoU and a substantial 12.3\% boost in ACC compared to SOTA methods. Furthermore, we conducted a qualitative analysis of our model's ability to detect important objects across different road scenarios and classes, highlighting its effectiveness in diverse contexts. Finally, we conducted various ablation studies to assess the efficiency of the proposed modules in our DRUformer model.
Learning to Predict Navigational Patterns from Partial Observations
Apr 26, 2023



Human beings cooperatively navigate rule-constrained environments by adhering to mutually known navigational patterns, which may be represented as directional pathways or road lanes. Inferring these navigational patterns from incompletely observed environments is required for intelligent mobile robots operating in unmapped locations. However, algorithmically defining these navigational patterns is nontrivial. This paper presents the first self-supervised learning (SSL) method for learning to infer navigational patterns in real-world environments from partial observations only. We explain how geometric data augmentation, predictive world modeling, and an information-theoretic regularizer enables our model to predict an unbiased local directional soft lane probability (DSLP) field in the limit of infinite data. We demonstrate how to infer global navigational patterns by fitting a maximum likelihood graph to the DSLP field. Experiments show that our SSL model outperforms two SOTA supervised lane graph prediction models on the nuScenes dataset. We propose our SSL method as a scalable and interpretable continual learning paradigm for navigation by perception. Code released upon publication.
Predictive World Models from Real-World Partial Observations
Jan 12, 2023



Cognitive scientists believe adaptable intelligent agents like humans perform reasoning through learned causal mental simulations of agents and environments. The problem of learning such simulations is called predictive world modeling. Recently, reinforcement learning (RL) agents leveraging world models have achieved SOTA performance in game environments. However, understanding how to apply the world modeling approach in complex real-world environments relevant to mobile robots remains an open question. In this paper, we present a framework for learning a probabilistic predictive world model for real-world road environments. We implement the model using a hierarchical VAE (HVAE) capable of predicting a diverse set of fully observed plausible worlds from accumulated sensor observations. While prior HVAE methods require complete states as ground truth for learning, we present a novel sequential training method to allow HVAEs to learn to predict complete states from partially observed states only. We experimentally demonstrate accurate spatial structure prediction of deterministic regions achieving 96.21 IoU, and close the gap to perfect prediction by 62 % for stochastic regions using the best prediction. By extending HVAEs to cases where complete ground truth states do not exist, we facilitate continual learning of spatial prediction as a step towards realizing explainable and comprehensive predictive world models for real-world mobile robotics applications.
ViCE: Self-Supervised Visual Concept Embeddings as Contextual and Pixel Appearance Invariant Semantic Representations
Nov 24, 2021

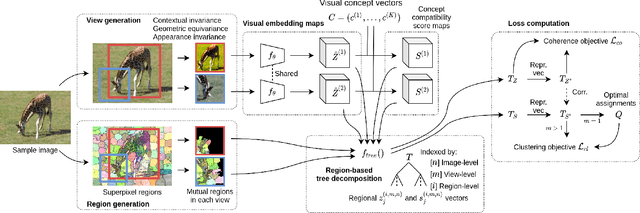

This work presents a self-supervised method to learn dense semantically rich visual concept embeddings for images inspired by methods for learning word embeddings in NLP. Our method improves on prior work by generating more expressive embeddings and by being applicable for high-resolution images. Viewing the generation of natural images as a stochastic process where a set of latent visual concepts give rise to observable pixel appearances, our method is formulated to learn the inverse mapping from pixels to concepts. Our method greatly improves the effectiveness of self-supervised learning for dense embedding maps by introducing superpixelization as a natural hierarchical step up from pixels to a small set of visually coherent regions. Additional contributions are regional contextual masking with nonuniform shapes matching visually coherent patches and complexity-based view sampling inspired by masked language models. The enhanced expressiveness of our dense embeddings is demonstrated by significantly improving the state-of-the-art representation quality benchmarks on COCO (+12.94 mIoU, +87.6\%) and Cityscapes (+16.52 mIoU, +134.2\%). Results show favorable scaling and domain generalization properties not demonstrated by prior work.