 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulCPred: Learning Multi-modal Concepts for Explainable Pedestrian Action Prediction
Sep 14, 2024



Pedestrian action prediction is of great significance for many applications such as autonomous driving. However, state-of-the-art methods lack explainability to make trustworthy predictions. In this paper, a novel framework called MulCPred is proposed that explains its predictions based on multi-modal concepts represented by training samples. Previous concept-based methods have limitations including: 1) they cannot directly apply to multi-modal cases; 2) they lack locality to attend to details in the inputs; 3) they suffer from mode collapse. These limitations are tackled accordingly through the following approaches: 1) a linear aggregator to integrate the activation results of the concepts into predictions, which associates concepts of different modalities and provides ante-hoc explanations of the relevance between the concepts and the predictions; 2) a channel-wise recalibration module that attends to local spatiotemporal regions, which enables the concepts with locality; 3) a feature regularization loss that encourages the concepts to learn diverse patterns. MulCPred is evaluated on multiple datasets and tasks. Both qualitative and quantitative results demonstrate that MulCPred is promising in improving the explainability of pedestrian action prediction without obvious performance degradation. Furthermore, by removing unrecognizable concepts from MulCPred, the cross-dataset prediction performance is improved, indicating the feasibility of further generalizability of MulCPred.
Compositional Semantics for Open Vocabulary Spatio-semantic Representations
Oct 08, 2023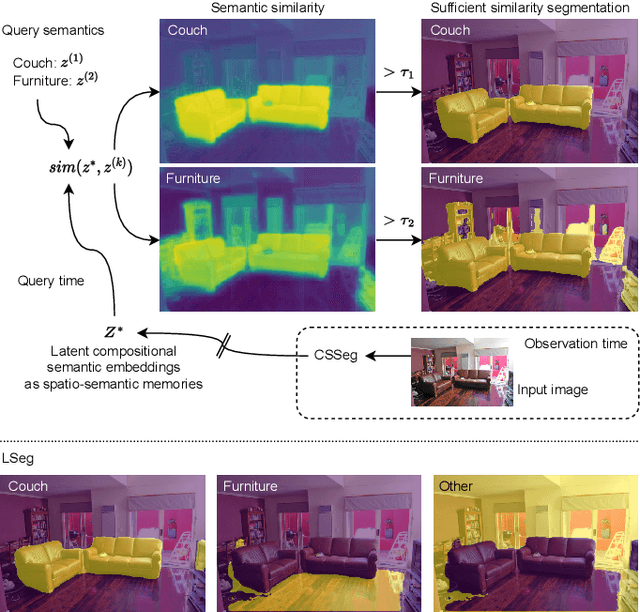
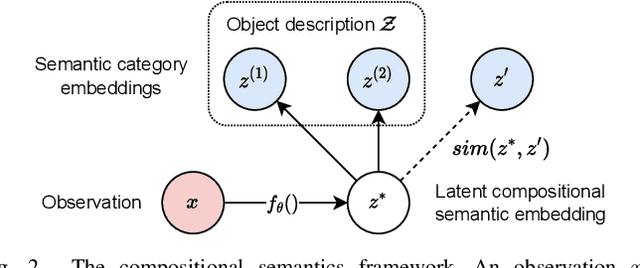
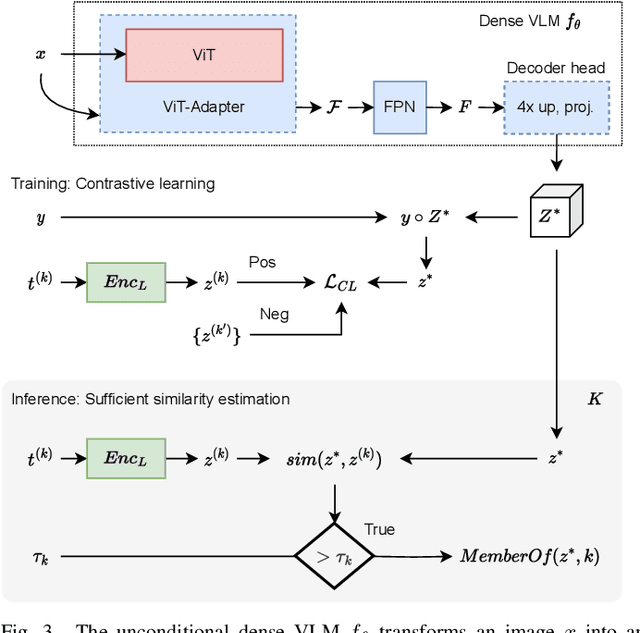
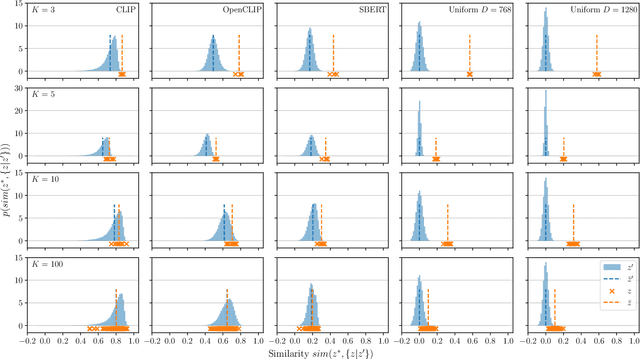
General-purpose mobile robots need to complete tasks without exact human instructions. Large language models (LLMs) is a promising direction for realizing commonsense world knowledge and reasoning-based planning. Vision-language models (VLMs) transform environment percepts into vision-language semantics interpretable by LLMs. However, completing complex tasks often requires reasoning about information beyond what is currently perceived. We propose latent compositional semantic embeddings z* as a principled learning-based knowledge representation for queryable spatio-semantic memories. We mathematically prove that z* can always be found, and the optimal z* is the centroid for any set Z. We derive a probabilistic bound for estimating separability of related and unrelated semantics. We prove that z* is discoverable by iterative optimization by gradient descent from visual appearance and singular descriptions. We experimentally verify our findings on four embedding spaces incl. CLIP and SBERT. Our results show that z* can represent up to 10 semantics encoded by SBERT, and up to 100 semantics for ideal uniformly distributed high-dimensional embeddings. We demonstrate that a simple dense VLM trained on the COCO-Stuff dataset can learn z* for 181 overlapping semantics by 42.23 mIoU, while improving conventional non-overlapping open-vocabulary segmentation performance by +3.48 mIoU compared with a popular SOTA model.
R-Cut: Enhancing Explainability in Vision Transformers with Relationship Weighted Out and Cut
Jul 18, 2023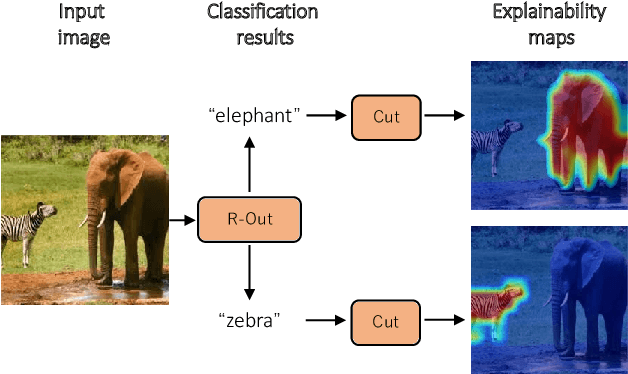
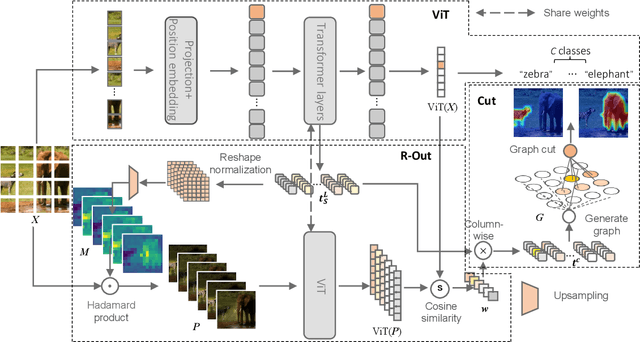


Transformer-based models have gained popularity in the field of natural language processing (NLP) and are extensively utilized in computer vision tasks and multi-modal models such as GPT4. This paper presents a novel method to enhance the explainability of Transformer-based image classification models. Our method aims to improve trust in classification results and empower users to gain a deeper understanding of the model for downstream tasks by providing visualizations of class-specific maps. We introduce two modules: the ``Relationship Weighted Out" and the ``Cut" modules. The ``Relationship Weighted Out" module focuses on extracting class-specific information from intermediate layers, enabling us to highlight relevant features. Additionally, the ``Cut" module performs fine-grained feature decomposition, taking into account factors such as position, texture, and color. By integrating these modules, we generate dense class-specific visual explainability maps. We validate our method with extensive qualitative and quantitative experiments on the ImageNet dataset. Furthermore, we conduct a large number of experiments on the LRN dataset, specifically designed for automatic driving danger alerts, to evaluate the explainability of our method in complex backgrounds. The results demonstrate a significant improvement over previous methods. Moreover, we conduct ablation experiments to validate the effectiveness of each module. Through these experiments, we are able to confirm the respective contributions of each module, thus solidifying the overall effectiveness of our proposed approach.
Learning to Predict Navigational Patterns from Partial Observations
Apr 26, 2023



Human beings cooperatively navigate rule-constrained environments by adhering to mutually known navigational patterns, which may be represented as directional pathways or road lanes. Inferring these navigational patterns from incompletely observed environments is required for intelligent mobile robots operating in unmapped locations. However, algorithmically defining these navigational patterns is nontrivial. This paper presents the first self-supervised learning (SSL) method for learning to infer navigational patterns in real-world environments from partial observations only. We explain how geometric data augmentation, predictive world modeling, and an information-theoretic regularizer enables our model to predict an unbiased local directional soft lane probability (DSLP) field in the limit of infinite data. We demonstrate how to infer global navigational patterns by fitting a maximum likelihood graph to the DSLP field. Experiments show that our SSL model outperforms two SOTA supervised lane graph prediction models on the nuScenes dataset. We propose our SSL method as a scalable and interpretable continual learning paradigm for navigation by perception. Code released upon publication.
Predictive World Models from Real-World Partial Observations
Jan 12, 2023



Cognitive scientists believe adaptable intelligent agents like humans perform reasoning through learned causal mental simulations of agents and environments. The problem of learning such simulations is called predictive world modeling. Recently, reinforcement learning (RL) agents leveraging world models have achieved SOTA performance in game environments. However, understanding how to apply the world modeling approach in complex real-world environments relevant to mobile robots remains an open question. In this paper, we present a framework for learning a probabilistic predictive world model for real-world road environments. We implement the model using a hierarchical VAE (HVAE) capable of predicting a diverse set of fully observed plausible worlds from accumulated sensor observations. While prior HVAE methods require complete states as ground truth for learning, we present a novel sequential training method to allow HVAEs to learn to predict complete states from partially observed states only. We experimentally demonstrate accurate spatial structure prediction of deterministic regions achieving 96.21 IoU, and close the gap to perfect prediction by 62 % for stochastic regions using the best prediction. By extending HVAEs to cases where complete ground truth states do not exist, we facilitate continual learning of spatial prediction as a step towards realizing explainable and comprehensive predictive world models for real-world mobile robotics applications.
ViCE: Self-Supervised Visual Concept Embeddings as Contextual and Pixel Appearance Invariant Semantic Representations
Nov 24, 2021

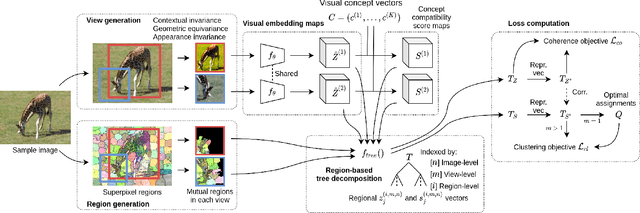

This work presents a self-supervised method to learn dense semantically rich visual concept embeddings for images inspired by methods for learning word embeddings in NLP. Our method improves on prior work by generating more expressive embeddings and by being applicable for high-resolution images. Viewing the generation of natural images as a stochastic process where a set of latent visual concepts give rise to observable pixel appearances, our method is formulated to learn the inverse mapping from pixels to concepts. Our method greatly improves the effectiveness of self-supervised learning for dense embedding maps by introducing superpixelization as a natural hierarchical step up from pixels to a small set of visually coherent regions. Additional contributions are regional contextual masking with nonuniform shapes matching visually coherent patches and complexity-based view sampling inspired by masked language models. The enhanced expressiveness of our dense embeddings is demonstrated by significantly improving the state-of-the-art representation quality benchmarks on COCO (+12.94 mIoU, +87.6\%) and Cityscapes (+16.52 mIoU, +134.2\%). Results show favorable scaling and domain generalization properties not demonstrated by prior work.
Learning a Model for Inferring a Spatial Road Lane Network Graph using Self-Supervision
Jul 05, 2021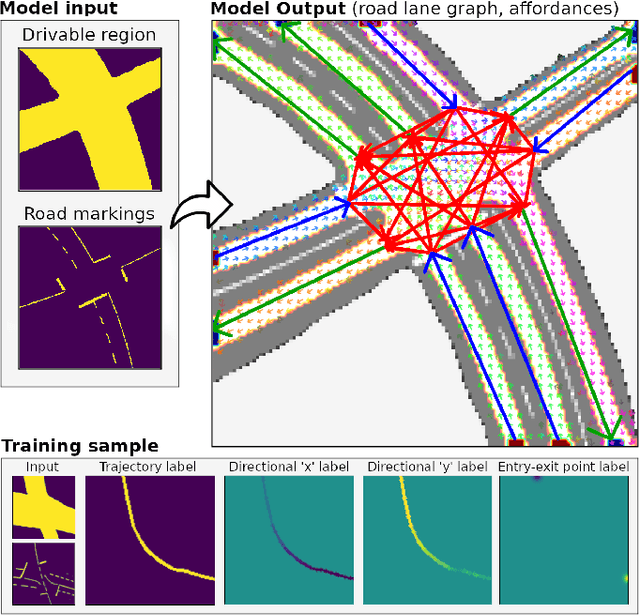
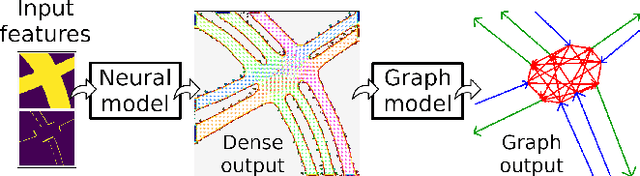


Interconnected road lanes are a central concept for navigating urban roads. Currently, most autonomous vehicles rely on preconstructed lane maps as designing an algorithmic model is difficult. However, the generation and maintenance of such maps is costly and hinders large-scale adoption of autonomous vehicle technology. This paper presents the first self-supervised learning method to train a model to infer a spatially grounded lane-level road network graph based on a dense segmented representation of the road scene generated from onboard sensors. A formal road lane network model is presented and proves that any structured road scene can be represented by a directed acyclic graph of at most depth three while retaining the notion of intersection regions, and that this is the most compressed representation. The formal model is implemented by a hybrid neural and search-based model, utilizing a novel barrier function loss formulation for robust learning from partial labels. Experiments are conducted for all common road intersection layouts. Results show that the model can generalize to new road layouts, unlike previous approaches, demonstrating its potential for real-world application as a practical learning-based lane-level map generator.
Probabilistic Rainfall Estimation from Automotive Lidar
Apr 23, 2021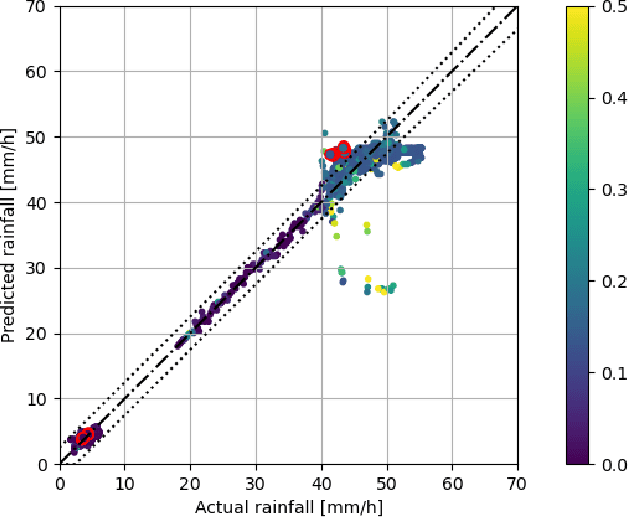
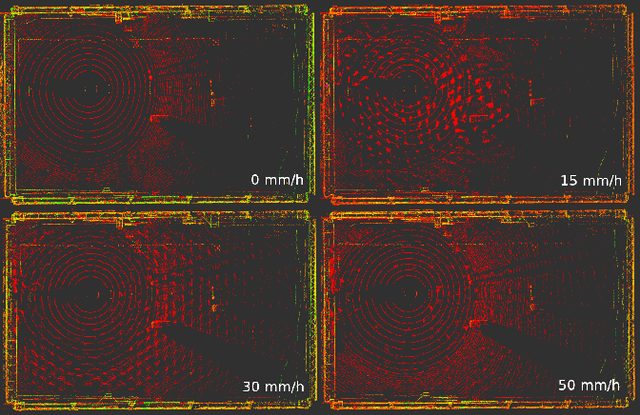


Robust sensing and perception in adverse weather conditions remains one of the biggest challenges for realizing reliable autonomous vehicle mobility services. Prior work has established that rainfall rate is a useful measure for adversity of atmospheric weather conditions. This work presents a probabilistic hierarchical Bayesian model that infers rainfall rate from automotive lidar point cloud sequences with high accuracy and reliability. The model is a hierarchical mixture of expert model, or a probabilistic decision tree, with gating and expert nodes consisting of variational logistic and linear regression models. Experimental data used to train and evaluate the model is collected in a large-scale rainfall experiment facility from both stationary and moving vehicle platforms. The results show prediction accuracy comparable to the measurement resolution of a disdrometer, and the soundness and usefulness of the uncertainty estimation. The model achieves RMSE 2.42 mm/h after filtering out uncertain predictions. The error is comparable to the mean rainfall rate change of 3.5 mm/h between measurements. Model parameter studies show how predictive performance changes with tree depth, sampling duration, and crop box dimension. A second experiment demonstrate the predictability of higher rainfall above 300 mm/h using a different lidar sensor, demonstrating sensor independence.
Learning a Directional Soft Lane Affordance Model for Road Scenes Using Self-Supervision
Feb 17, 2020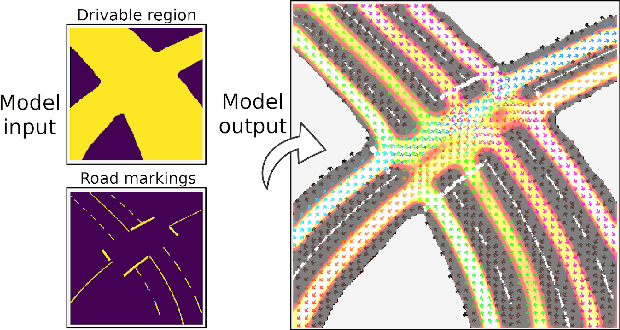

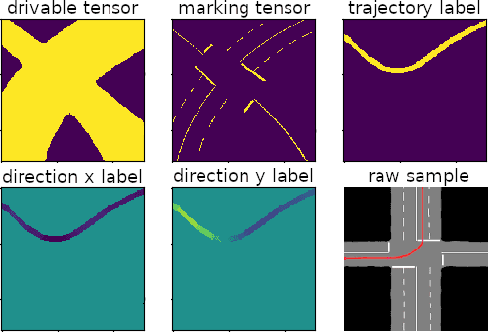
Humans navigate complex environments in an organized yet flexible manner, adapting to the context and implicit social rules. Understanding these naturally learned patterns of behavior is essential for applications such as autonomous vehicles. However, algorithmically defining these implicit rules of human behavior remains difficult. This work proposes a novel self-supervised method for training a probabilistic network model to estimate the regions humans are most likely to drive in as well as a multimodal representation of the inferred direction of travel at each point. The model is trained on individual human trajectories conditioned on a representation of the driving environment. The model is shown to successfully generalize to new road scenes, demonstrating potential for real-world application as a prior for socially acceptable driving behavior in challenging or ambiguous scenarios which are poorly handled by explicit traffic rules.