 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Semantics for Open Vocabulary Spatio-semantic Representations
Paper and Code
Oct 08, 2023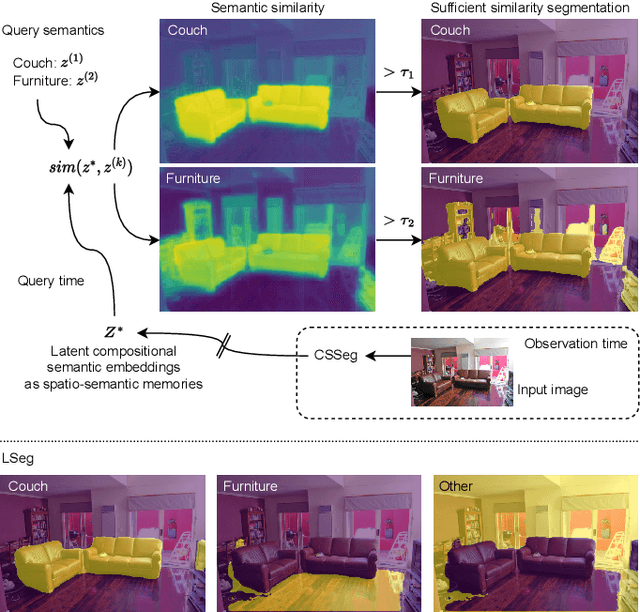
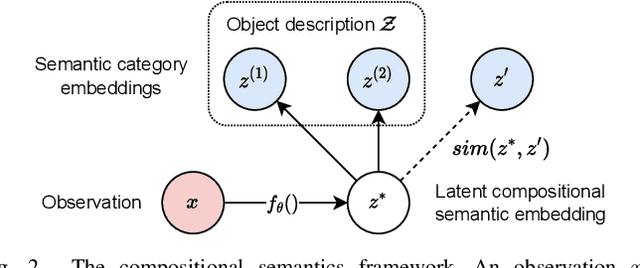
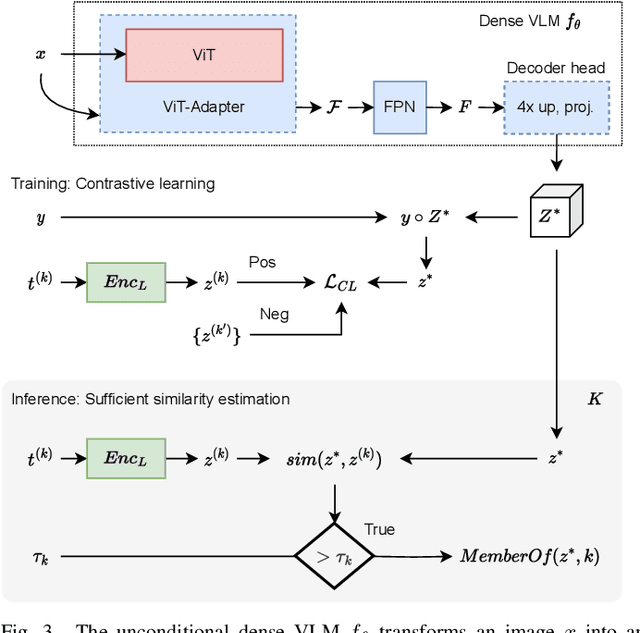
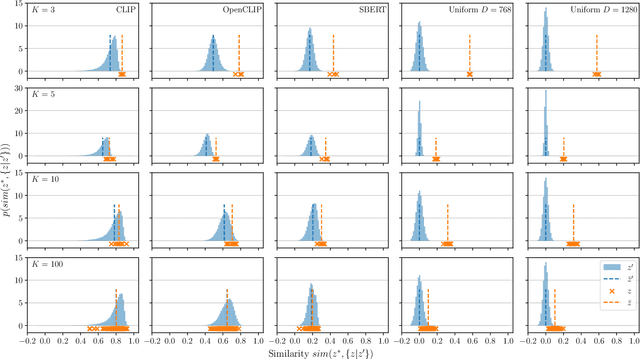
General-purpose mobile robots need to complete tasks without exact human instructions. Large language models (LLMs) is a promising direction for realizing commonsense world knowledge and reasoning-based planning. Vision-language models (VLMs) transform environment percepts into vision-language semantics interpretable by LLMs. However, completing complex tasks often requires reasoning about information beyond what is currently perceived. We propose latent compositional semantic embeddings z* as a principled learning-based knowledge representation for queryable spatio-semantic memories. We mathematically prove that z* can always be found, and the optimal z* is the centroid for any set Z. We derive a probabilistic bound for estimating separability of related and unrelated semantics. We prove that z* is discoverable by iterative optimization by gradient descent from visual appearance and singular descriptions. We experimentally verify our findings on four embedding spaces incl. CLIP and SBERT. Our results show that z* can represent up to 10 semantics encoded by SBERT, and up to 100 semantics for ideal uniformly distributed high-dimensional embeddings. We demonstrate that a simple dense VLM trained on the COCO-Stuff dataset can learn z* for 181 overlapping semantics by 42.23 mIoU, while improving conventional non-overlapping open-vocabulary segmentation performance by +3.48 mIoU compared with a popular SOTA model.