 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Semantics for Open Vocabulary Spatio-semantic Representations
Oct 08, 2023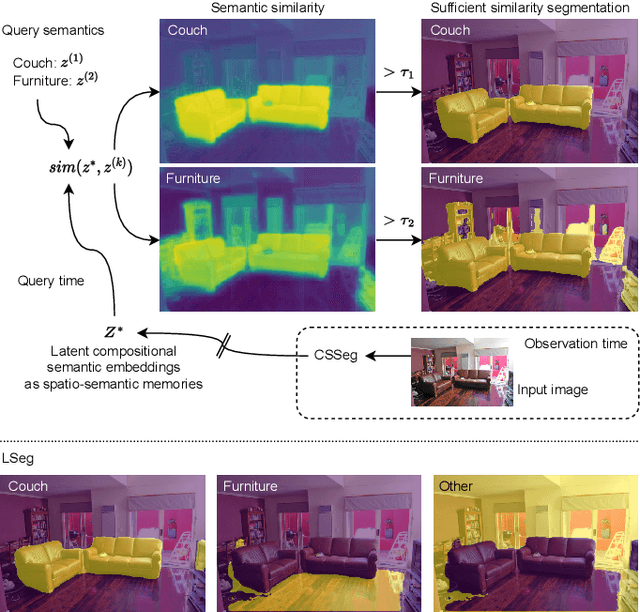
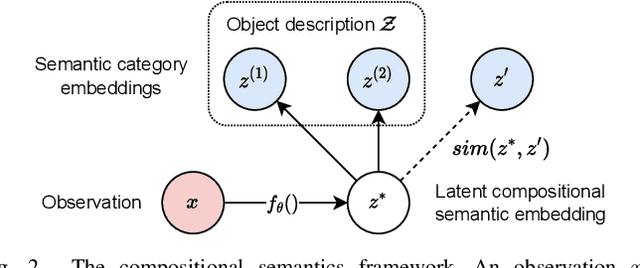
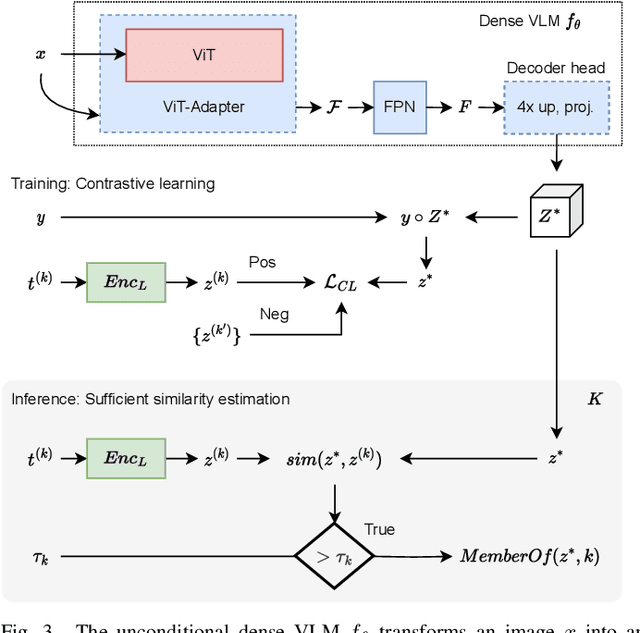
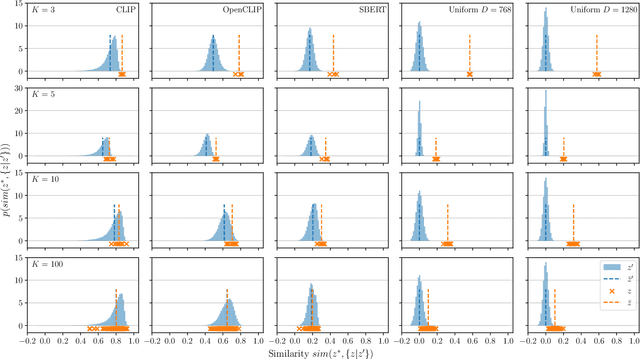
General-purpose mobile robots need to complete tasks without exact human instructions. Large language models (LLMs) is a promising direction for realizing commonsense world knowledge and reasoning-based planning. Vision-language models (VLMs) transform environment percepts into vision-language semantics interpretable by LLMs. However, completing complex tasks often requires reasoning about information beyond what is currently perceived. We propose latent compositional semantic embeddings z* as a principled learning-based knowledge representation for queryable spatio-semantic memories. We mathematically prove that z* can always be found, and the optimal z* is the centroid for any set Z. We derive a probabilistic bound for estimating separability of related and unrelated semantics. We prove that z* is discoverable by iterative optimization by gradient descent from visual appearance and singular descriptions. We experimentally verify our findings on four embedding spaces incl. CLIP and SBERT. Our results show that z* can represent up to 10 semantics encoded by SBERT, and up to 100 semantics for ideal uniformly distributed high-dimensional embeddings. We demonstrate that a simple dense VLM trained on the COCO-Stuff dataset can learn z* for 181 overlapping semantics by 42.23 mIoU, while improving conventional non-overlapping open-vocabulary segmentation performance by +3.48 mIoU compared with a popular SOTA model.
Learning to Predict Navigational Patterns from Partial Observations
Apr 26, 2023



Human beings cooperatively navigate rule-constrained environments by adhering to mutually known navigational patterns, which may be represented as directional pathways or road lanes. Inferring these navigational patterns from incompletely observed environments is required for intelligent mobile robots operating in unmapped locations. However, algorithmically defining these navigational patterns is nontrivial. This paper presents the first self-supervised learning (SSL) method for learning to infer navigational patterns in real-world environments from partial observations only. We explain how geometric data augmentation, predictive world modeling, and an information-theoretic regularizer enables our model to predict an unbiased local directional soft lane probability (DSLP) field in the limit of infinite data. We demonstrate how to infer global navigational patterns by fitting a maximum likelihood graph to the DSLP field. Experiments show that our SSL model outperforms two SOTA supervised lane graph prediction models on the nuScenes dataset. We propose our SSL method as a scalable and interpretable continual learning paradigm for navigation by perception. Code released upon publication.