 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAD: A VLM-Augmented Autonomous Driving Framework with Hierarchical Planning and Interpretable Decision Process
Jul 02, 2025Recent advancements in open-source Visual Language Models (VLMs) such as LLaVA, Qwen-VL, and Llama have catalyzed extensive research on their integration with diverse systems. The internet-scale general knowledge encapsulated within these models presents significant opportunities for enhancing autonomous driving perception, prediction, and planning capabilities. In this paper we propose VLAD, a vision-language autonomous driving model, which integrates a fine-tuned VLM with VAD, a state-of-the-art end-to-end system. We implement a specialized fine-tuning approach using custom question-answer datasets designed specifically to improve the spatial reasoning capabilities of the model. The enhanced VLM generates high-level navigational commands that VAD subsequently processes to guide vehicle operation. Additionally, our system produces interpretable natural language explanations of driving decisions, thereby increasing transparency and trustworthiness of the traditionally black-box end-to-end architecture. Comprehensive evaluation on the real-world nuScenes dataset demonstrates that our integrated system reduces average collision rates by 31.82% compared to baseline methodologies, establishing a new benchmark for VLM-augmented autonomous driving systems.
Sparse Prototype Network for Explainable Pedestrian Behavior Prediction
Oct 16, 2024



Predicting pedestrian behavior is challenging yet crucial for applications such as autonomous driving and smart city. Recent deep learning models have achieved remarkable performance in making accurate predictions, but they fail to provide explanations of their inner workings. One reason for this problem is the multi-modal inputs. To bridge this gap, we present Sparse Prototype Network (SPN), an explainable method designed to simultaneously predict a pedestrian's future action, trajectory, and pose. SPN leverages an intermediate prototype bottleneck layer to provide sample-based explanations for its predictions. The prototypes are modality-independent, meaning that they can correspond to any modality from the input. Therefore, SPN can extend to arbitrary combinations of modalities. Regularized by mono-semanticity and clustering constraints, the prototypes learn consistent and human-understandable features and achieve state-of-the-art performance on action, trajectory and pose prediction on TITAN and PIE. Finally, we propose a metric named Top-K Mono-semanticity Scale to quantitatively evaluate the explainability. Qualitative results show the positive correlation between sparsity and explainability. Code available at https://github.com/Equinoxxxxx/SPN.
MulCPred: Learning Multi-modal Concepts for Explainable Pedestrian Action Prediction
Sep 14, 2024



Pedestrian action prediction is of great significance for many applications such as autonomous driving. However, state-of-the-art methods lack explainability to make trustworthy predictions. In this paper, a novel framework called MulCPred is proposed that explains its predictions based on multi-modal concepts represented by training samples. Previous concept-based methods have limitations including: 1) they cannot directly apply to multi-modal cases; 2) they lack locality to attend to details in the inputs; 3) they suffer from mode collapse. These limitations are tackled accordingly through the following approaches: 1) a linear aggregator to integrate the activation results of the concepts into predictions, which associates concepts of different modalities and provides ante-hoc explanations of the relevance between the concepts and the predictions; 2) a channel-wise recalibration module that attends to local spatiotemporal regions, which enables the concepts with locality; 3) a feature regularization loss that encourages the concepts to learn diverse patterns. MulCPred is evaluated on multiple datasets and tasks. Both qualitative and quantitative results demonstrate that MulCPred is promising in improving the explainability of pedestrian action prediction without obvious performance degradation. Furthermore, by removing unrecognizable concepts from MulCPred, the cross-dataset prediction performance is improved, indicating the feasibility of further generalizability of MulCPred.
DRUformer: Enhancing the driving scene Important object detection with driving relationship self-understanding
Nov 11, 2023
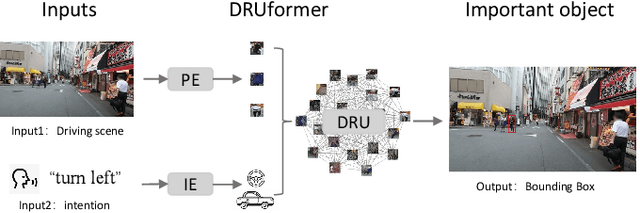
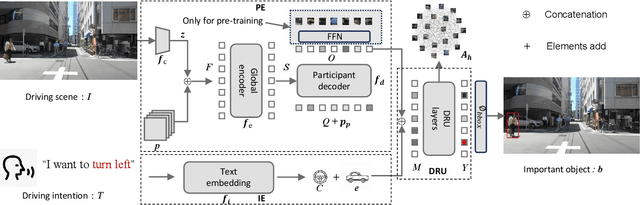
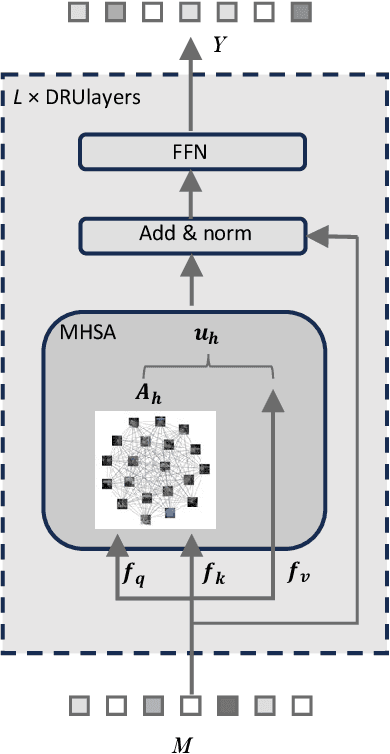
Traffic accidents frequently lead to fatal injuries, contributing to over 50 million deaths until 2023. To mitigate driving hazards and ensure personal safety, it is crucial to assist vehicles in anticipating important objects during travel. Previous research on important object detection primarily assessed the importance of individual participants, treating them as independent entities and frequently overlooking the connections between these participants. Unfortunately, this approach has proven less effective in detecting important objects in complex scenarios. In response, we introduce Driving scene Relationship self-Understanding transformer (DRUformer), designed to enhance the important object detection task. The DRUformer is a transformer-based multi-modal important object detection model that takes into account the relationships between all the participants in the driving scenario. Recognizing that driving intention also significantly affects the detection of important objects during driving, we have incorporated a module for embedding driving intention. To assess the performance of our approach, we conducted a comparative experiment on the DRAMA dataset, pitting our model against other state-of-the-art (SOTA) models. The results demonstrated a noteworthy 16.2\% improvement in mIoU and a substantial 12.3\% boost in ACC compared to SOTA methods. Furthermore, we conducted a qualitative analysis of our model's ability to detect important objects across different road scenarios and classes, highlighting its effectiveness in diverse contexts. Finally, we conducted various ablation studies to assess the efficiency of the proposed modules in our DRUformer model.
Learning to Predict Navigational Patterns from Partial Observations
Apr 26, 2023



Human beings cooperatively navigate rule-constrained environments by adhering to mutually known navigational patterns, which may be represented as directional pathways or road lanes. Inferring these navigational patterns from incompletely observed environments is required for intelligent mobile robots operating in unmapped locations. However, algorithmically defining these navigational patterns is nontrivial. This paper presents the first self-supervised learning (SSL) method for learning to infer navigational patterns in real-world environments from partial observations only. We explain how geometric data augmentation, predictive world modeling, and an information-theoretic regularizer enables our model to predict an unbiased local directional soft lane probability (DSLP) field in the limit of infinite data. We demonstrate how to infer global navigational patterns by fitting a maximum likelihood graph to the DSLP field. Experiments show that our SSL model outperforms two SOTA supervised lane graph prediction models on the nuScenes dataset. We propose our SSL method as a scalable and interpretable continual learning paradigm for navigation by perception. Code released upon publication.
Predictive World Models from Real-World Partial Observations
Jan 12, 2023



Cognitive scientists believe adaptable intelligent agents like humans perform reasoning through learned causal mental simulations of agents and environments. The problem of learning such simulations is called predictive world modeling. Recently, reinforcement learning (RL) agents leveraging world models have achieved SOTA performance in game environments. However, understanding how to apply the world modeling approach in complex real-world environments relevant to mobile robots remains an open question. In this paper, we present a framework for learning a probabilistic predictive world model for real-world road environments. We implement the model using a hierarchical VAE (HVAE) capable of predicting a diverse set of fully observed plausible worlds from accumulated sensor observations. While prior HVAE methods require complete states as ground truth for learning, we present a novel sequential training method to allow HVAEs to learn to predict complete states from partially observed states only. We experimentally demonstrate accurate spatial structure prediction of deterministic regions achieving 96.21 IoU, and close the gap to perfect prediction by 62 % for stochastic regions using the best prediction. By extending HVAEs to cases where complete ground truth states do not exist, we facilitate continual learning of spatial prediction as a step towards realizing explainable and comprehensive predictive world models for real-world mobile robotics applications.
Autonomous Driving in Adverse Weather Conditions: A Survey
Dec 16, 2021



Automated Driving Systems (ADS) open up a new domain for the automotive industry and offer new possibilities for future transportation with higher efficiency and comfortable experiences. However, autonomous driving under adverse weather conditions has been the problem that keeps autonomous vehicles (AVs) from going to level 4 or higher autonomy for a long time. This paper assesses the influences and challenges that weather brings to ADS sensors in an analytic and statistical way, and surveys the solutions against inclement weather conditions. State-of-the-art techniques on perception enhancement with regard to each kind of weather are thoroughly reported. External auxiliary solutions like V2X technology, weather conditions coverage in currently available datasets, simulators, and experimental facilities with weather chambers are distinctly sorted out. By pointing out all kinds of major weather problems the autonomous driving field is currently facing, and reviewing both hardware and computer science solutions in recent years, this survey contributes a holistic overview on the obstacles and directions of ADS development in terms of adverse weather driving conditions.
ViCE: Self-Supervised Visual Concept Embeddings as Contextual and Pixel Appearance Invariant Semantic Representations
Nov 24, 2021

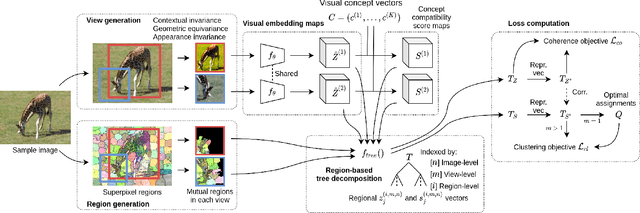

This work presents a self-supervised method to learn dense semantically rich visual concept embeddings for images inspired by methods for learning word embeddings in NLP. Our method improves on prior work by generating more expressive embeddings and by being applicable for high-resolution images. Viewing the generation of natural images as a stochastic process where a set of latent visual concepts give rise to observable pixel appearances, our method is formulated to learn the inverse mapping from pixels to concepts. Our method greatly improves the effectiveness of self-supervised learning for dense embedding maps by introducing superpixelization as a natural hierarchical step up from pixels to a small set of visually coherent regions. Additional contributions are regional contextual masking with nonuniform shapes matching visually coherent patches and complexity-based view sampling inspired by masked language models. The enhanced expressiveness of our dense embeddings is demonstrated by significantly improving the state-of-the-art representation quality benchmarks on COCO (+12.94 mIoU, +87.6\%) and Cityscapes (+16.52 mIoU, +134.2\%). Results show favorable scaling and domain generalization properties not demonstrated by prior work.
Road Scene Graph: A Semantic Graph-Based Scene Representation Dataset for Intelligent Vehicles
Nov 27, 2020
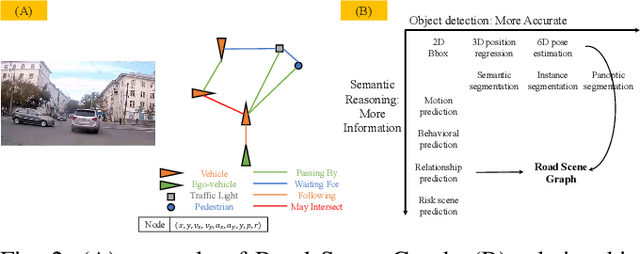
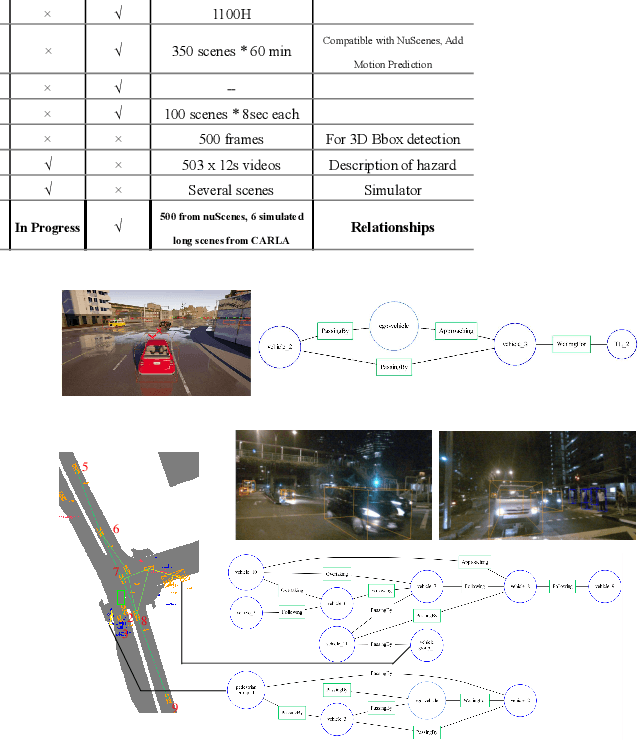
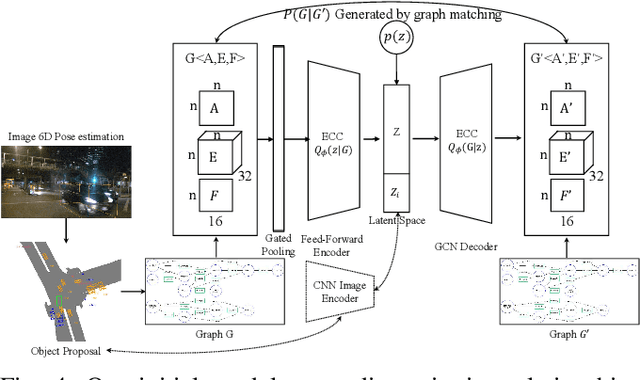
Rich semantic information extraction plays a vital role on next-generation intelligent vehicles. Currently there is great amount of research focusing on fundamental applications such as 6D pose detection, road scene semantic segmentation, etc. And this provides us a great opportunity to think about how shall these data be organized and exploited. In this paper we propose road scene graph,a special scene-graph for intelligent vehicles. Different to classical data representation, this graph provides not only object proposals but also their pair-wise relationships. By organizing them in a topological graph, these data are explainable, fully-connected, and could be easily processed by GCNs (Graph Convolutional Networks). Here we apply scene graph on roads using our Road Scene Graph dataset, including the basic graph prediction model. This work also includes experimental evaluations using the proposed model.
Characterization of Multiple 3D LiDARs for Localization and Mapping using Normal Distributions Transform
Apr 03, 2020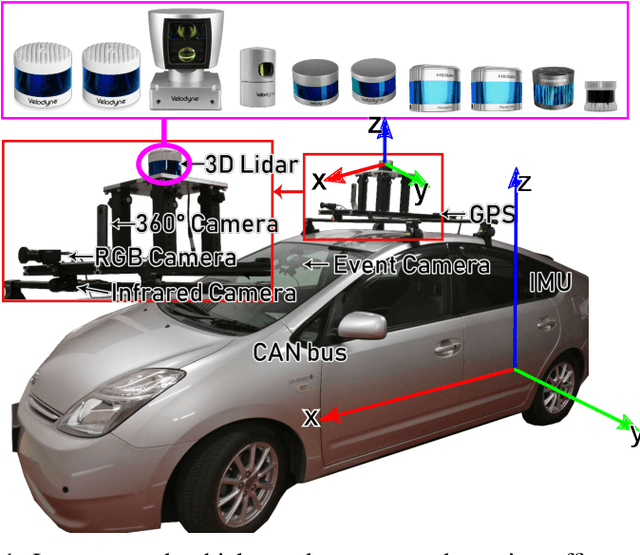

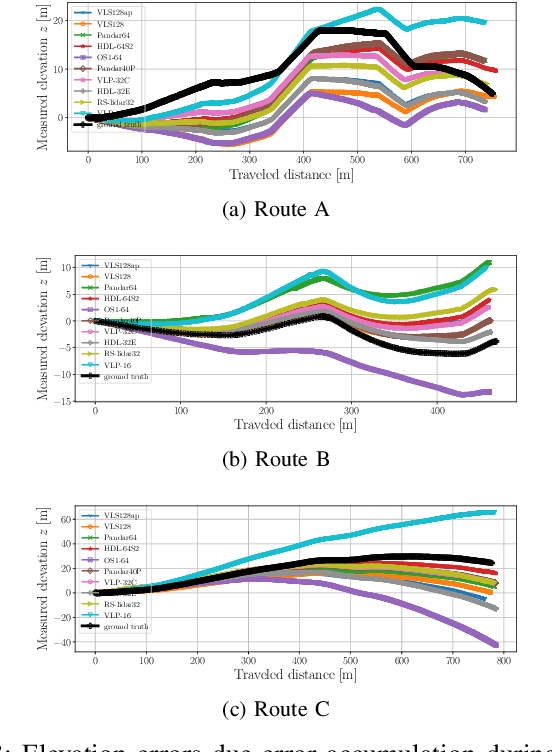

In this work, we present a detailed comparison of ten different 3D LiDAR sensors, covering a range of manufacturers, models, and laser configurations, for the tasks of mapping and vehicle localization, using as common reference the Normal Distributions Transform (NDT) algorithm implemented in the self-driving open source platform Autoware. LiDAR data used in this study is a subset of our LiDAR Benchmarking and Reference (LIBRE) dataset, captured independently from each sensor, from a vehicle driven on public urban roads multiple times, at different times of the day. In this study, we analyze the performance and characteristics of each LiDAR for the tasks of (1) 3D mapping including an assessment map quality based on mean map entropy, and (2) 6-DOF localization using a ground truth reference map.