 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Cross-Domain Pre-Trained Language Models for Clinical Text Mining: How Do They Perform on Data-Constrained Fine-Tuning?
Oct 31, 2022Pre-trained language models (PLMs) have been deployed in many natural language processing (NLP) tasks and in various domains. Language model pre-training from general or mixed domain rich data plus fine-tuning using small amounts of available data in a low resource domain demonstrated beneficial results by researchers. In this work, we question this statement and verify if BERT-based PLMs from the biomedical domain can perform well in clinical text mining tasks via fine-tuning. We test the state-of-the-art models, i.e. Bioformer which is pre-trained on a large amount of biomedical data from PubMed corpus. We use a historical n2c2 clinical NLP challenge dataset for fine-tuning its task-adapted version (BioformerApt), and show that their performances are actually very low. We also present our own end-to-end model, TransformerCRF, which is developed using Transformer and conditional random fields (CRFs) as encoder and decoder. We further create a new variation model by adding a CRF layer on top of PLM Bioformer (BioformerCRF). We investigate the performances of TransformerCRF on clinical text mining tasks by training from scratch using a limited amount of data, as well as the model BioformerCRF. Experimental evaluation shows that, in a \textit{constrained setting}, all tested models are \textit{far from ideal} regarding extreme low-frequency special token recognition, even though they can achieve relatively higher accuracy on overall text tagging. Our models including source codes will be hosted at \url{https://github.com/poethan/TransformerCRF}.
TsFeX: Contact Tracing Model using Time Series Feature Extraction and Gradient Boosting
Dec 04, 2021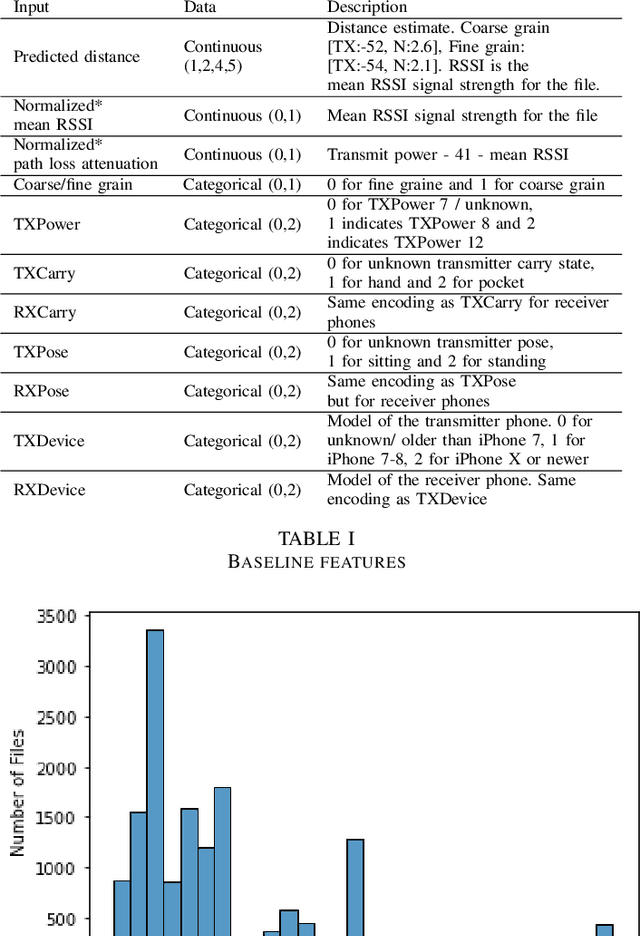
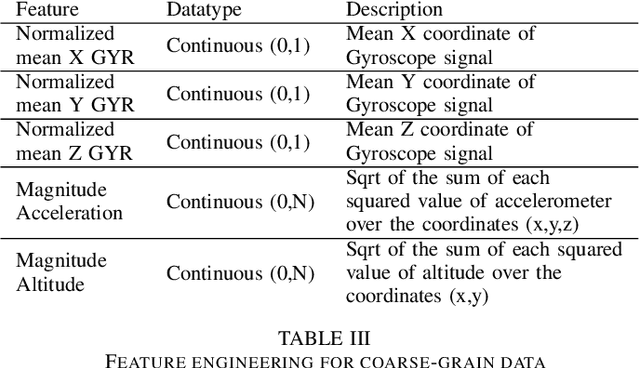
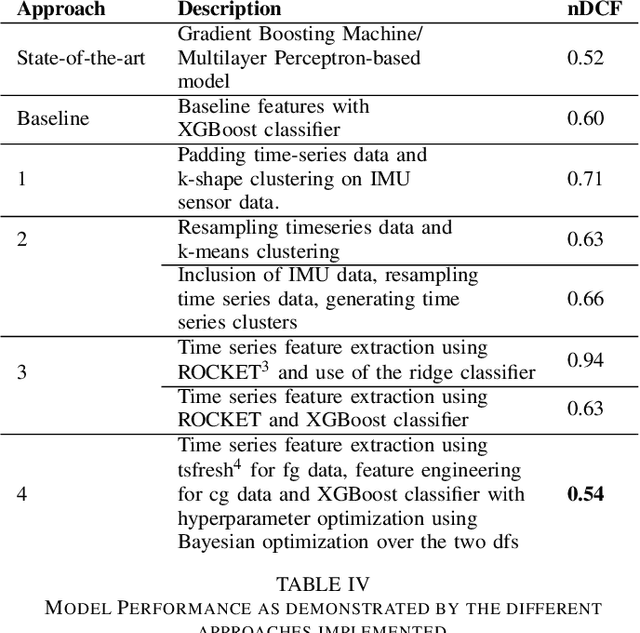
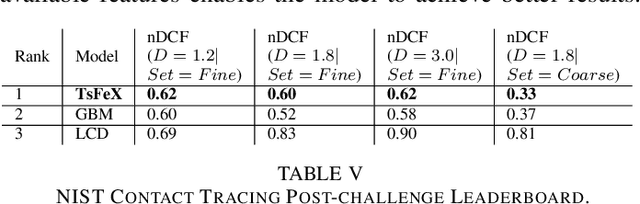
With the outbreak of COVID-19 pandemic, a dire need to effectively identify the individuals who may have come in close-contact to others who have been infected with COVID-19 has risen. This process of identifying individuals, also termed as 'Contact tracing', has significant implications for the containment and control of the spread of this virus. However, manual tracing has proven to be ineffective calling for automated contact tracing approaches. As such, this research presents an automated machine learning system for identifying individuals who may have come in contact with others infected with COVID-19 using sensor data transmitted through handheld devices. This paper describes the different approaches followed in arriving at an optimal solution model that effectually predicts whether a person has been in close proximity to an infected individual using a gradient boosting algorithm and time series feature extraction.