 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformative Semi-Factuals for XAI: The Elaborated Explanations that People Prefer
Mar 18, 2026Recently, in eXplainable AI (XAI), $\textit{even if}$ explanations -- so-called semi-factuals -- have emerged as a popular strategy that explains how a predicted outcome $\textit{can remain the same}$ even when certain input-features are altered. For example, in the commonly-used banking app scenario, a semi-factual explanation could inform customers about better options, other alternatives for their successful application, by saying "$\textit{Even if}$ you asked for double the loan amount, you would still be accepted". Most semi-factuals XAI algorithms focus on finding maximal value-changes to a single key-feature that do $\textit{not}$ alter the outcome (unlike counterfactual explanations that often find minimal value-changes to several features that alter the outcome). However, no current semi-factual method explains $\textit{why}$ these extreme value-changes do not alter outcomes; for example, a more informative semi-factual could tell the customer that it is their good credit score that allows them to borrow double their requested loan. In this work, we advance a new algorithm -- the $\textit{informative semi-factuals}$ (ISF) method -- that generates more elaborated explanations supplementing semi-factuals with information about additional $\textit{hidden features}$ that influence an automated decision. Experimental results on benchmark datasets show that this ISF method computes semi-factuals that are both informative and of high-quality on key metrics. Furthermore, a user study shows that people prefer these elaborated explanations over the simpler semi-factual explanations generated by current methods.
Even-Ifs From If-Onlys: Are the Best Semi-Factual Explanations Found Using Counterfactuals As Guides?
Mar 01, 2024Recently, counterfactuals using "if-only" explanations have become very popular in eXplainable AI (XAI), as they describe which changes to feature-inputs of a black-box AI system result in changes to a (usually negative) decision-outcome. Even more recently, semi-factuals using "even-if" explanations have gained more attention. They elucidate the feature-input changes that do \textit{not} change the decision-outcome of the AI system, with a potential to suggest more beneficial recourses. Some semi-factual methods use counterfactuals to the query-instance to guide semi-factual production (so-called counterfactual-guided methods), whereas others do not (so-called counterfactual-free methods). In this work, we perform comprehensive tests of 8 semi-factual methods on 7 datasets using 5 key metrics, to determine whether counterfactual guidance is necessary to find the best semi-factuals. The results of these tests suggests not, but rather that computing other aspects of the decision space lead to better semi-factual XAI.
Explaining Groups of Instances Counterfactually for XAI: A Use Case, Algorithm and User Study for Group-Counterfactuals
Mar 16, 2023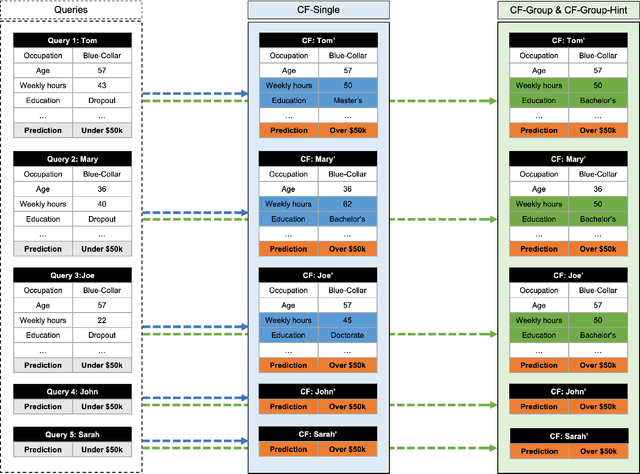
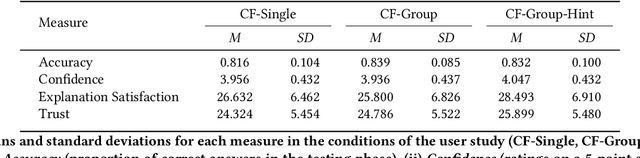

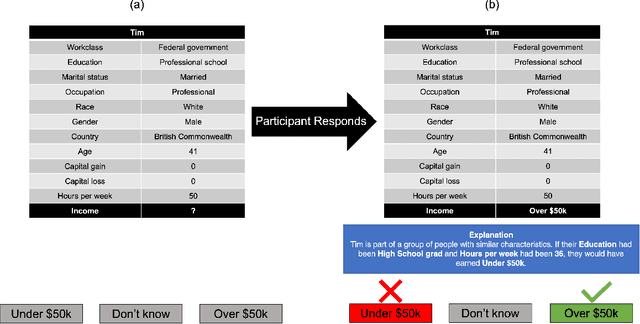
Counterfactual explanations are an increasingly popular form of post hoc explanation due to their (i) applicability across problem domains, (ii) proposed legal compliance (e.g., with GDPR), and (iii) reliance on the contrastive nature of human explanation. Although counterfactual explanations are normally used to explain individual predictive-instances, we explore a novel use case in which groups of similar instances are explained in a collective fashion using ``group counterfactuals'' (e.g., to highlight a repeating pattern of illness in a group of patients). These group counterfactuals meet a human preference for coherent, broad explanations covering multiple events/instances. A novel, group-counterfactual algorithm is proposed to generate high-coverage explanations that are faithful to the to-be-explained model. This explanation strategy is also evaluated in a large, controlled user study (N=207), using objective (i.e., accuracy) and subjective (i.e., confidence, explanation satisfaction, and trust) psychological measures. The results show that group counterfactuals elicit modest but definite improvements in people's understanding of an AI system. The implications of these findings for counterfactual methods and for XAI are discussed.
Counterfactual Explanations for Misclassified Images: How Human and Machine Explanations Differ
Dec 16, 2022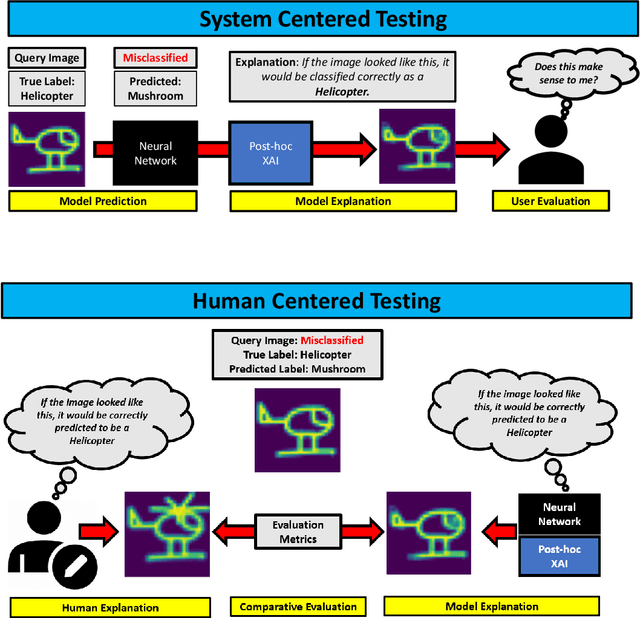
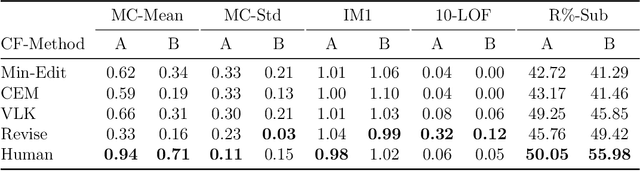
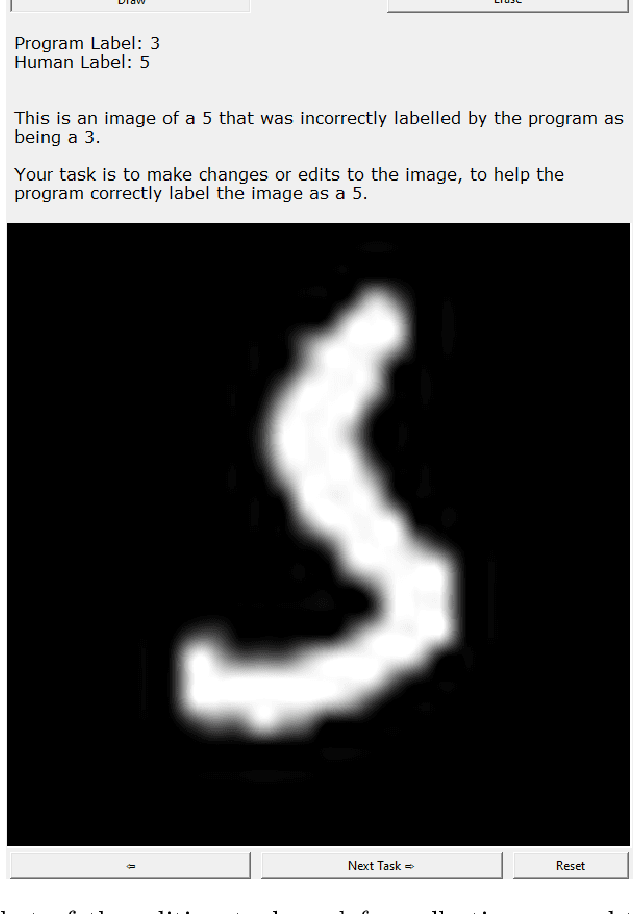
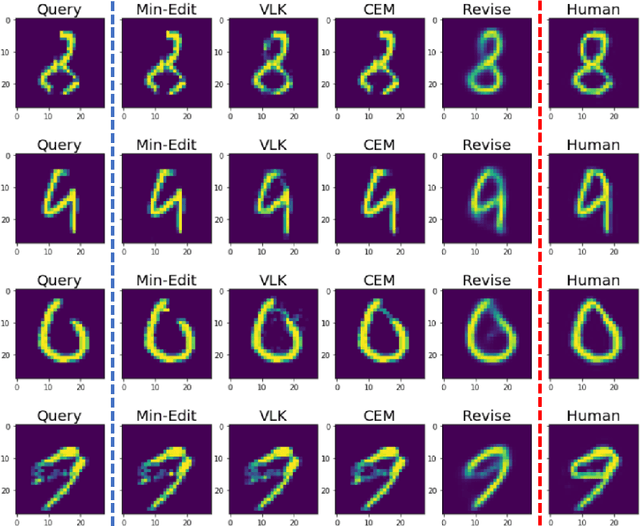
Counterfactual explanations have emerged as a popular solution for the eXplainable AI (XAI) problem of elucidating the predictions of black-box deep-learning systems due to their psychological validity, flexibility across problem domains and proposed legal compliance. While over 100 counterfactual methods exist, claiming to generate plausible explanations akin to those preferred by people, few have actually been tested on users ($\sim7\%$). So, the psychological validity of these counterfactual algorithms for effective XAI for image data is not established. This issue is addressed here using a novel methodology that (i) gathers ground truth human-generated counterfactual explanations for misclassified images, in two user studies and, then, (ii) compares these human-generated ground-truth explanations to computationally-generated explanations for the same misclassifications. Results indicate that humans do not "minimally edit" images when generating counterfactual explanations. Instead, they make larger, "meaningful" edits that better approximate prototypes in the counterfactual class.
Solving the Class Imbalance Problem Using a Counterfactual Method for Data Augmentation
Nov 05, 2021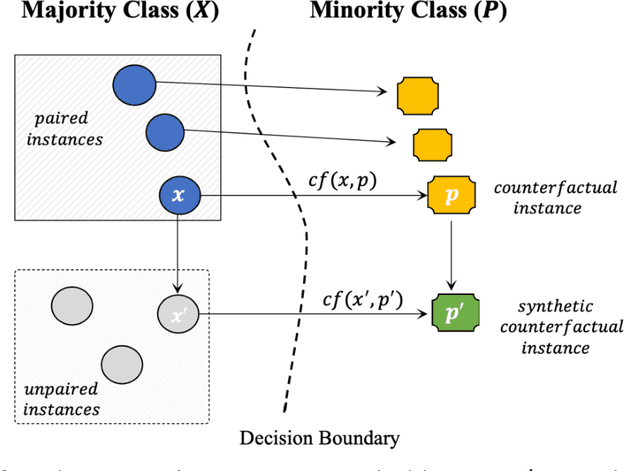
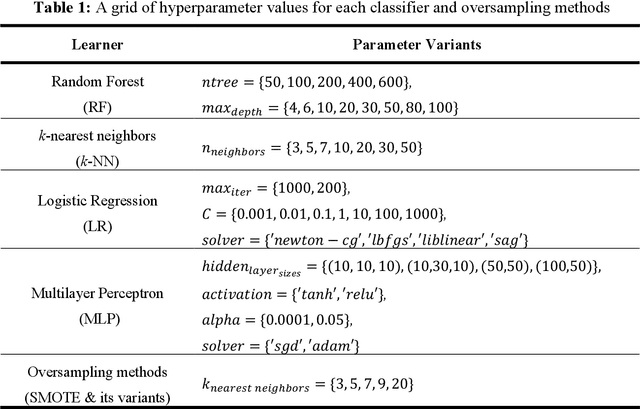
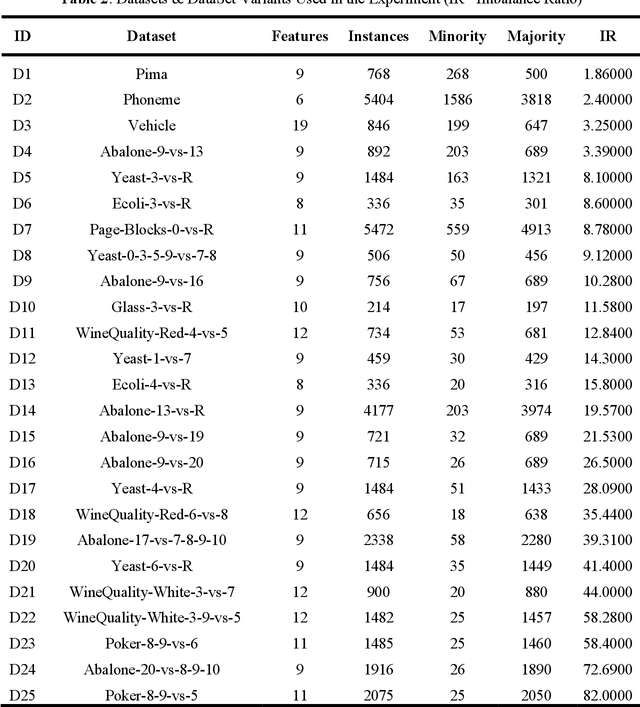
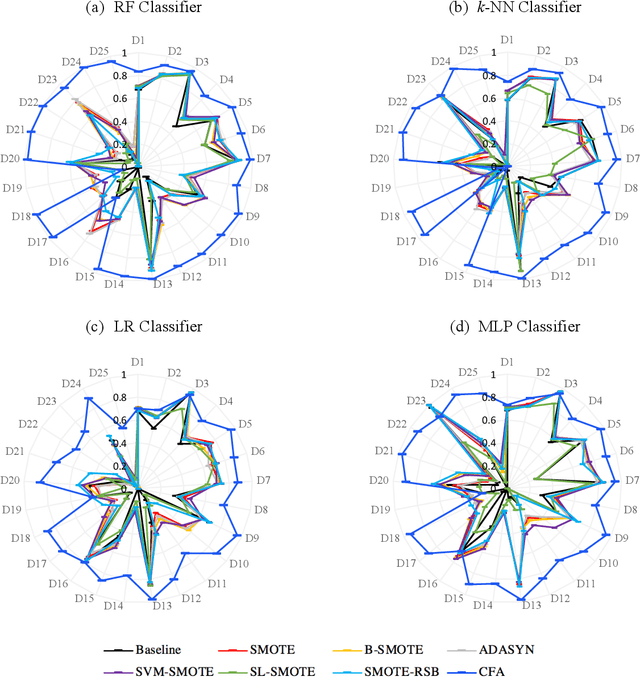
Learning from class imbalanced datasets poses challenges for many machine learning algorithms. Many real-world domains are, by definition, class imbalanced by virtue of having a majority class that naturally has many more instances than its minority class (e.g. genuine bank transactions occur much more often than fraudulent ones). Many methods have been proposed to solve the class imbalance problem, among the most popular being oversampling techniques (such as SMOTE). These methods generate synthetic instances in the minority class, to balance the dataset, performing data augmentations that improve the performance of predictive machine learning (ML) models. In this paper we advance a novel data augmentation method (adapted from eXplainable AI), that generates synthetic, counterfactual instances in the minority class. Unlike other oversampling techniques, this method adaptively combines exist-ing instances from the dataset, using actual feature-values rather than interpolating values between instances. Several experiments using four different classifiers and 25 datasets are reported, which show that this Counterfactual Augmentation method (CFA) generates useful synthetic data points in the minority class. The experiments also show that CFA is competitive with many other oversampling methods many of which are variants of SMOTE. The basis for CFAs performance is discussed, along with the conditions under which it is likely to perform better or worse in future tests.
Uncertainty Estimation and Out-of-Distribution Detection for Counterfactual Explanations: Pitfalls and Solutions
Jul 20, 2021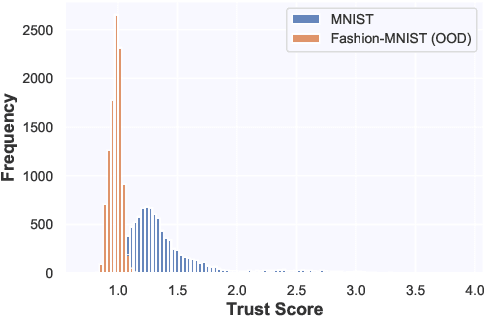
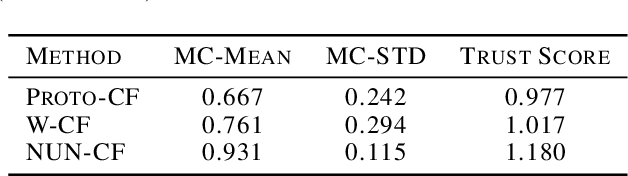
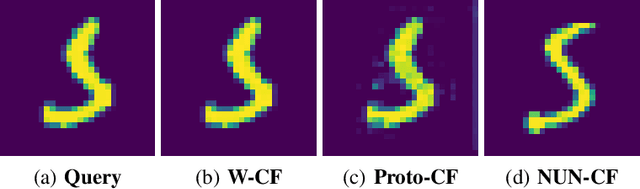
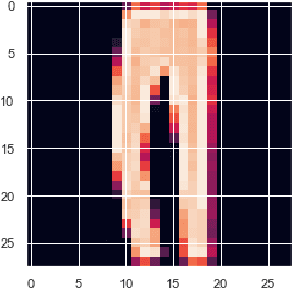
Whilst an abundance of techniques have recently been proposed to generate counterfactual explanations for the predictions of opaque black-box systems, markedly less attention has been paid to exploring the uncertainty of these generated explanations. This becomes a critical issue in high-stakes scenarios, where uncertain and misleading explanations could have dire consequences (e.g., medical diagnosis and treatment planning). Moreover, it is often difficult to determine if the generated explanations are well grounded in the training data and sensitive to distributional shifts. This paper proposes several practical solutions that can be leveraged to solve these problems by establishing novel connections with other research works in explainability (e.g., trust scores) and uncertainty estimation (e.g., Monte Carlo Dropout). Two experiments demonstrate the utility of our proposed solutions.
Predicting Illness for a Sustainable Dairy Agriculture: Predicting and Explaining the Onset of Mastitis in Dairy Cows
Jan 07, 2021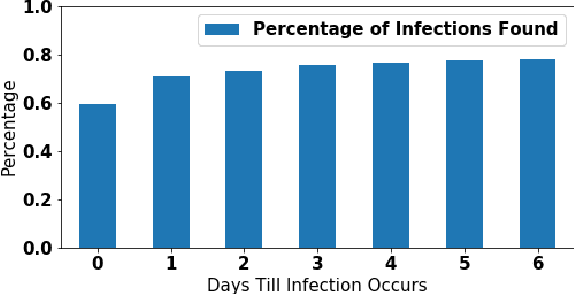
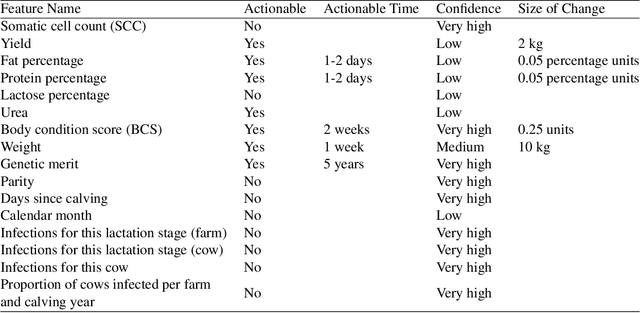

Mastitis is a billion dollar health problem for the modern dairy industry, with implications for antibiotic resistance. The use of AI techniques to identify the early onset of this disease, thus has significant implications for the sustainability of this agricultural sector. Current approaches to treating mastitis involve antibiotics and this practice is coming under ever increasing scrutiny. Using machine learning models to identify cows at risk of developing mastitis and applying targeted treatment regimes to only those animals promotes a more sustainable approach. Incorrect predictions from such models, however, can lead to monetary losses, unnecessary use of antibiotics, and even the premature death of animals, so it is important to generate compelling explanations for predictions to build trust with users and to better support their decision making. In this paper we demonstrate a system developed to predict mastitis infections in cows and provide explanations of these predictions using counterfactuals. We demonstrate the system and describe the engagement with farmers undertaken to build it.
Instance-Based Counterfactual Explanations for Time Series Classification
Sep 28, 2020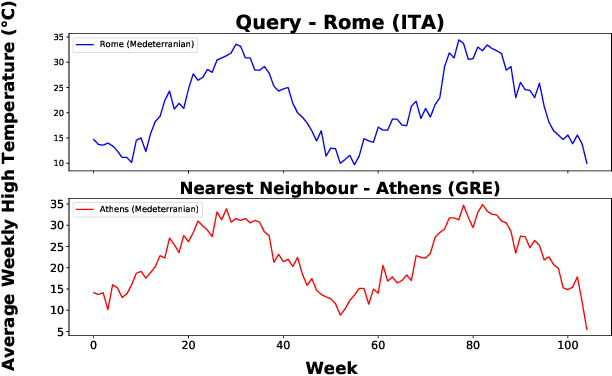

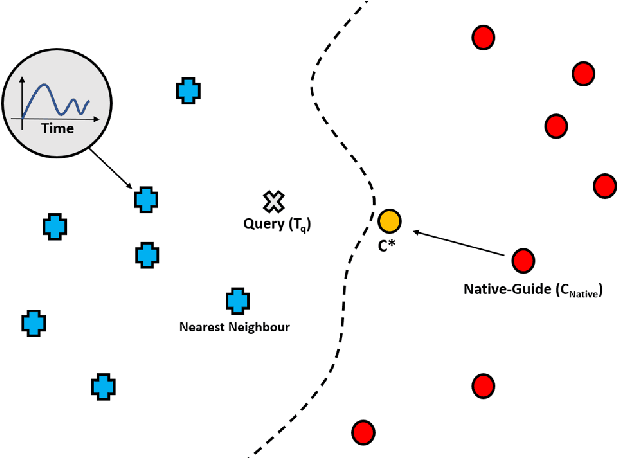
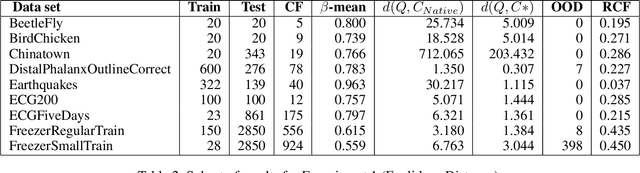
In recent years there has been a cascade of research in attempting to make AI systems more interpretable by providing explanations; so-called Explainable AI (XAI). Most of this research has dealt with the challenges that arise in explaining black-box deep learning systems in classification and regression tasks, with a focus on tabular and image data; for example, there is a rich seam of work on post-hoc counterfactual explanations for a variety of black-box classifiers (e.g., when a user is refused a loan, the counterfactual explanation tells the user about the conditions under which they would get the loan). However, less attention has been paid to the parallel interpretability challenges arising in AI systems dealing with time series data. This paper advances a novel technique, called Native-Guide, for the generation of proximal and plausible counterfactual explanations for instance-based time series classification tasks (e.g., where users are provided with alternative time series to explain how a classification might change). The Native-Guide method retrieves and uses native in-sample counterfactuals that already exist in the training data as "guides" for perturbation in time series counterfactual generation. This method can be coupled with both Euclidean and Dynamic Time Warping (DTW) distance measures. After illustrating the technique on a case study involving a climate classification task, we reported on a comprehensive series of experiments on both real-world and synthetic data sets from the UCR archive. These experiments provide computational evidence of the quality of the counterfactual explanations generated.
Play MNIST For Me! User Studies on the Effects of Post-Hoc, Example-Based Explanations & Error Rates on Debugging a Deep Learning, Black-Box Classifier
Sep 10, 2020

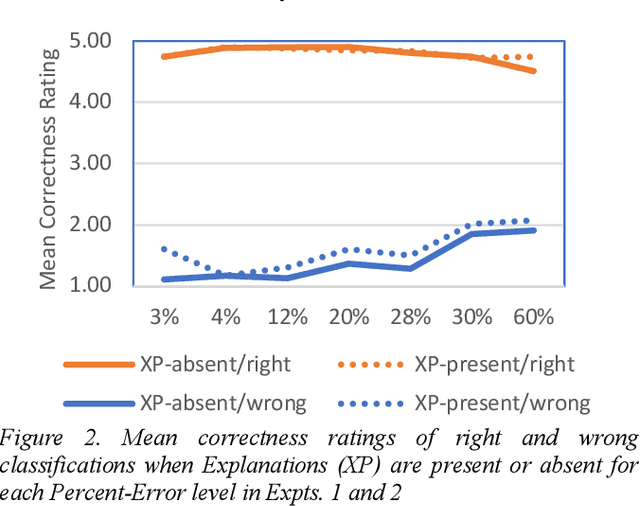
This paper reports two experiments (N=349) on the impact of post hoc explanations by example and error rates on peoples perceptions of a black box classifier. Both experiments show that when people are given case based explanations, from an implemented ANN CBR twin system, they perceive miss classifications to be more correct. They also show that as error rates increase above 4%, people trust the classifier less and view it as being less correct, less reasonable and less trustworthy. The implications of these results for XAI are discussed.
* 2 Figures, 1 Table, 8 pages
On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning
Sep 10, 2020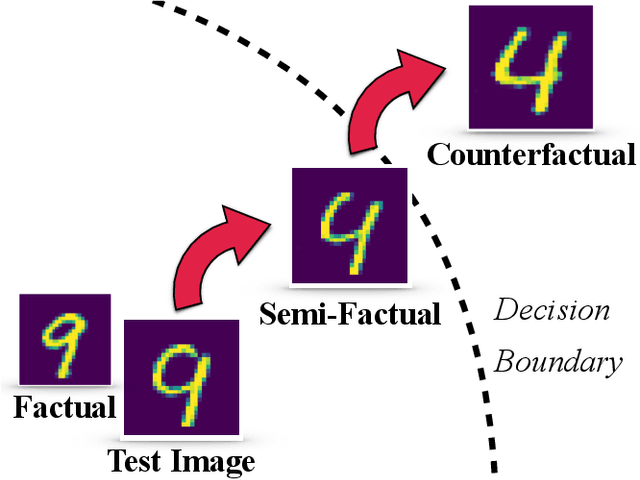



There is a growing concern that the recent progress made in AI, especially regarding the predictive competence of deep learning models, will be undermined by a failure to properly explain their operation and outputs. In response to this disquiet counterfactual explanations have become massively popular in eXplainable AI (XAI) due to their proposed computational psychological, and legal benefits. In contrast however, semifactuals, which are a similar way humans commonly explain their reasoning, have surprisingly received no attention. Most counterfactual methods address tabular rather than image data, partly due to the nondiscrete nature of the latter making good counterfactuals difficult to define. Additionally generating plausible looking explanations which lie on the data manifold is another issue which hampers progress. This paper advances a novel method for generating plausible counterfactuals (and semifactuals) for black box CNN classifiers doing computer vision. The present method, called PlausIble Exceptionality-based Contrastive Explanations (PIECE), modifies all exceptional features in a test image to be normal from the perspective of the counterfactual class (hence concretely defining a counterfactual). Two controlled experiments compare this method to others in the literature, showing that PIECE not only generates the most plausible counterfactuals on several measures, but also the best semifactuals.