 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Explaining Sources of Uncertainty in Automated Fact-Checking
May 23, 2025



Understanding sources of a model's uncertainty regarding its predictions is crucial for effective human-AI collaboration. Prior work proposes using numerical uncertainty or hedges ("I'm not sure, but ..."), which do not explain uncertainty that arises from conflicting evidence, leaving users unable to resolve disagreements or rely on the output. We introduce CLUE (Conflict-and-Agreement-aware Language-model Uncertainty Explanations), the first framework to generate natural language explanations of model uncertainty by (i) identifying relationships between spans of text that expose claim-evidence or inter-evidence conflicts and agreements that drive the model's predictive uncertainty in an unsupervised way, and (ii) generating explanations via prompting and attention steering that verbalize these critical interactions. Across three language models and two fact-checking datasets, we show that CLUE produces explanations that are more faithful to the model's uncertainty and more consistent with fact-checking decisions than prompting for uncertainty explanations without span-interaction guidance. Human evaluators judge our explanations to be more helpful, more informative, less redundant, and more logically consistent with the input than this baseline. CLUE requires no fine-tuning or architectural changes, making it plug-and-play for any white-box language model. By explicitly linking uncertainty to evidence conflicts, it offers practical support for fact-checking and generalises readily to other tasks that require reasoning over complex information.
Can Community Notes Replace Professional Fact-Checkers?
Feb 19, 2025Two commonly-employed strategies to combat the rise of misinformation on social media are (i) fact-checking by professional organisations and (ii) community moderation by platform users. Policy changes by Twitter/X and, more recently, Meta, signal a shift away from partnerships with fact-checking organisations and towards an increased reliance on crowdsourced community notes. However, the extent and nature of dependencies between fact-checking and helpful community notes remain unclear. To address these questions, we use language models to annotate a large corpus of Twitter/X community notes with attributes such as topic, cited sources, and whether they refute claims tied to broader misinformation narratives. Our analysis reveals that community notes cite fact-checking sources up to five times more than previously reported. Fact-checking is especially crucial for notes on posts linked to broader narratives, which are twice as likely to reference fact-checking sources compared to other sources. In conclusion, our results show that successful community moderation heavily relies on professional fact-checking.
Show Me the Work: Fact-Checkers' Requirements for Explainable Automated Fact-Checking
Feb 13, 2025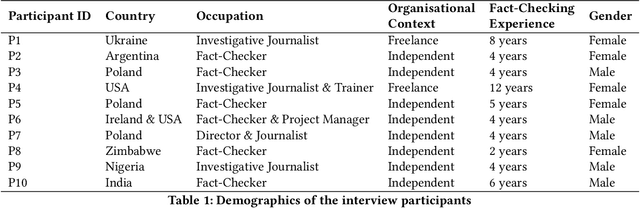
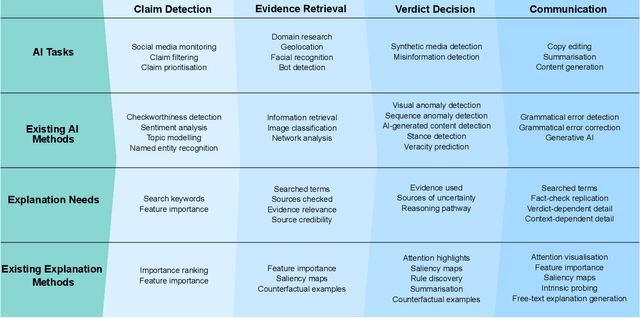
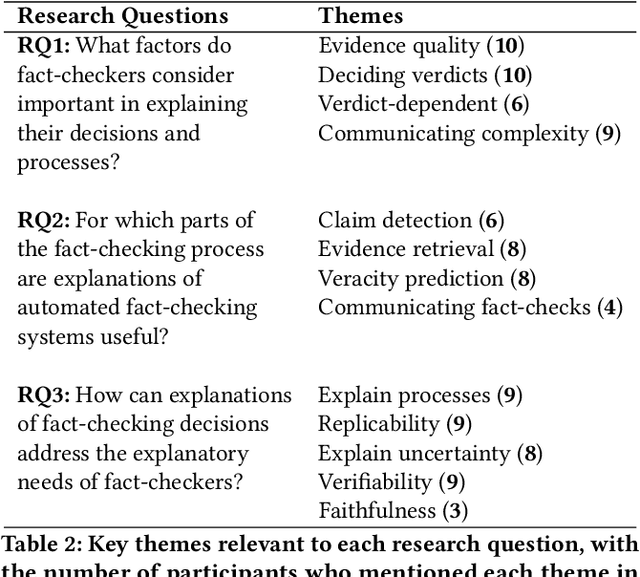
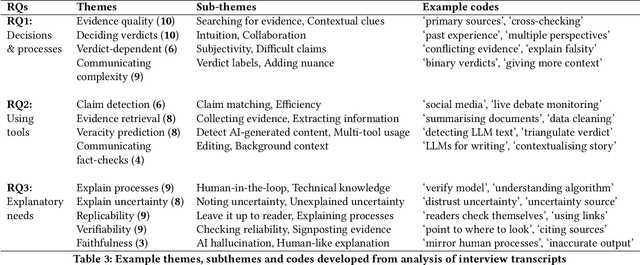
The pervasiveness of large language models and generative AI in online media has amplified the need for effective automated fact-checking to assist fact-checkers in tackling the increasing volume and sophistication of misinformation. The complex nature of fact-checking demands that automated fact-checking systems provide explanations that enable fact-checkers to scrutinise their outputs. However, it is unclear how these explanations should align with the decision-making and reasoning processes of fact-checkers to be effectively integrated into their workflows. Through semi-structured interviews with fact-checking professionals, we bridge this gap by: (i) providing an account of how fact-checkers assess evidence, make decisions, and explain their processes; (ii) examining how fact-checkers use automated tools in practice; and (iii) identifying fact-checker explanation requirements for automated fact-checking tools. The findings show unmet explanation needs and identify important criteria for replicable fact-checking explanations that trace the model's reasoning path, reference specific evidence, and highlight uncertainty and information gaps.
Explaining Groups of Instances Counterfactually for XAI: A Use Case, Algorithm and User Study for Group-Counterfactuals
Mar 16, 2023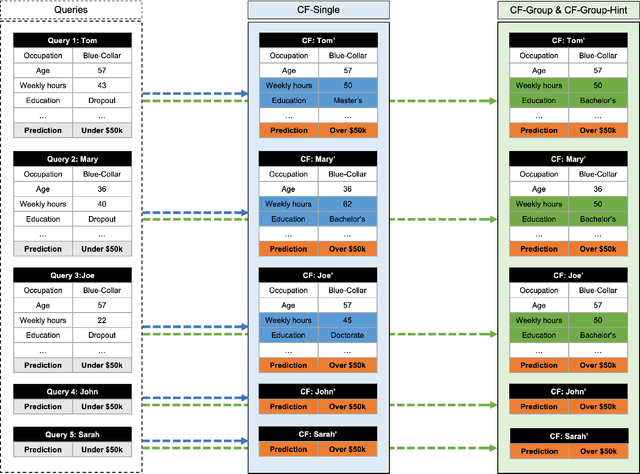
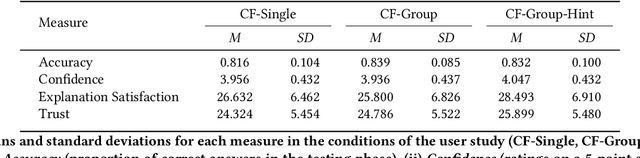

Counterfactual explanations are an increasingly popular form of post hoc explanation due to their (i) applicability across problem domains, (ii) proposed legal compliance (e.g., with GDPR), and (iii) reliance on the contrastive nature of human explanation. Although counterfactual explanations are normally used to explain individual predictive-instances, we explore a novel use case in which groups of similar instances are explained in a collective fashion using ``group counterfactuals'' (e.g., to highlight a repeating pattern of illness in a group of patients). These group counterfactuals meet a human preference for coherent, broad explanations covering multiple events/instances. A novel, group-counterfactual algorithm is proposed to generate high-coverage explanations that are faithful to the to-be-explained model. This explanation strategy is also evaluated in a large, controlled user study (N=207), using objective (i.e., accuracy) and subjective (i.e., confidence, explanation satisfaction, and trust) psychological measures. The results show that group counterfactuals elicit modest but definite improvements in people's understanding of an AI system. The implications of these findings for counterfactual methods and for XAI are discussed.
Features of Explainability: How users understand counterfactual and causal explanations for categorical and continuous features in XAI
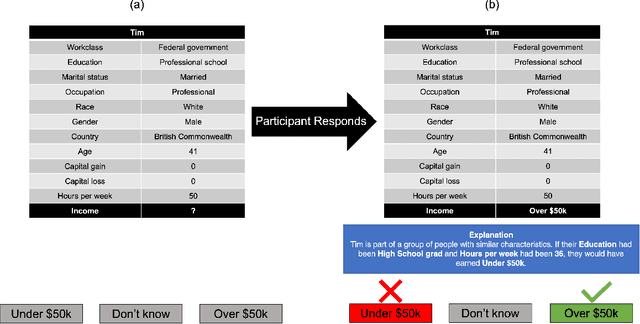
Apr 21, 2022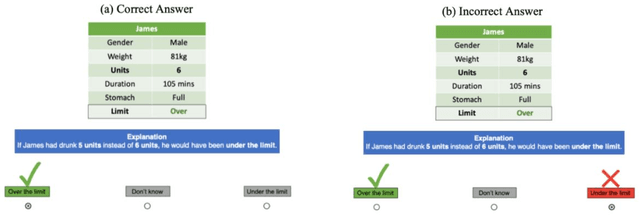
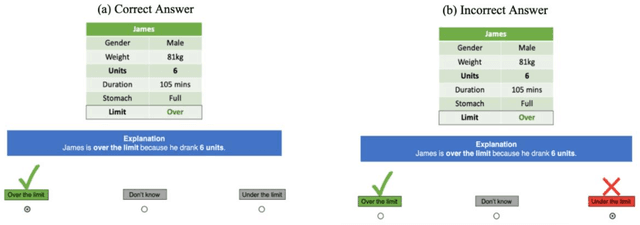

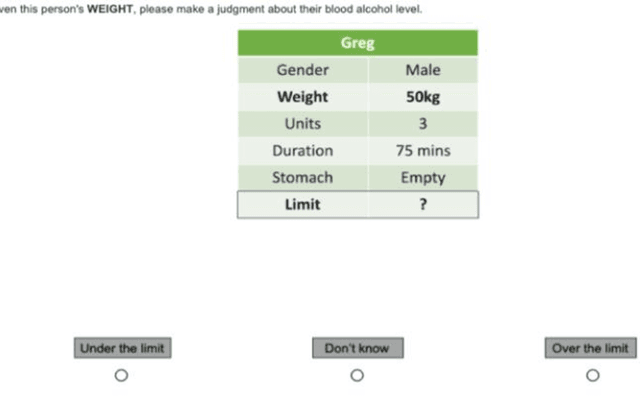
Counterfactual explanations are increasingly used to address interpretability, recourse, and bias in AI decisions. However, we do not know how well counterfactual explanations help users to understand a systems decisions, since no large scale user studies have compared their efficacy to other sorts of explanations such as causal explanations (which have a longer track record of use in rule based and decision tree models). It is also unknown whether counterfactual explanations are equally effective for categorical as for continuous features, although current methods assume they do. Hence, in a controlled user study with 127 volunteer participants, we tested the effects of counterfactual and causal explanations on the objective accuracy of users predictions of the decisions made by a simple AI system, and participants subjective judgments of satisfaction and trust in the explanations. We discovered a dissociation between objective and subjective measures: counterfactual explanations elicit higher accuracy of predictions than no-explanation control descriptions but no higher accuracy than causal explanations, yet counterfactual explanations elicit greater satisfaction and trust than causal explanations. We also found that users understand explanations referring to categorical features more readily than those referring to continuous features. We discuss the implications of these findings for current and future counterfactual methods in XAI.