 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting The Weather: A Hybrid Counterfactual-SMOTE Algorithm for Improving Crop Growth Prediction When Climate Changes
Nov 14, 2025In recent years, humanity has begun to experience the catastrophic effects of climate change as economic sectors (such as agriculture) struggle with unpredictable and extreme weather events. Artificial Intelligence (AI) should help us handle these climate challenges but its most promising solutions are not good at dealing with climate-disrupted data; specifically, machine learning methods that work from historical data-distributions, are not good at handling out-of-distribution, outlier events. In this paper, we propose a novel data augmentation method, that treats the predictive problems around climate change as being, in part, due to class-imbalance issues; that is, prediction from historical datasets is difficult because, by definition, they lack sufficient minority-class instances of "climate outlier events". This novel data augmentation method -- called Counterfactual-Based SMOTE (CFA-SMOTE) -- combines an instance-based counterfactual method from Explainable AI (XAI) with the well-known class-imbalance method, SMOTE. CFA-SMOTE creates synthetic data-points representing outlier, climate-events that augment the dataset to improve predictive performance. We report comparative experiments using this CFA-SMOTE method, comparing it to benchmark counterfactual and class-imbalance methods under different conditions (i.e., class-imbalance ratios). The focal climate-change domain used relies on predicting grass growth on Irish dairy farms, during Europe-wide drought and forage crisis of 2018.
Solving the Class Imbalance Problem Using a Counterfactual Method for Data Augmentation
Nov 05, 2021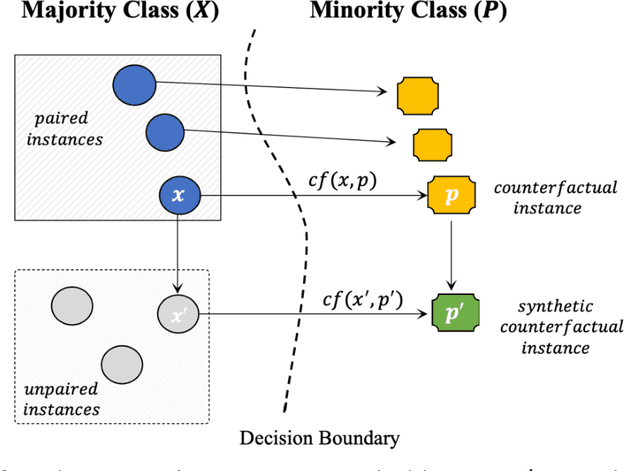
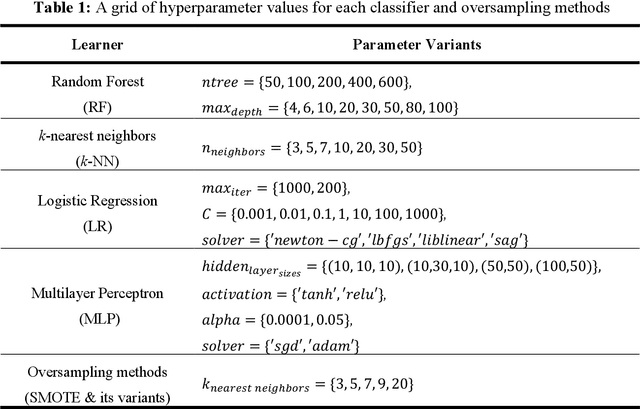
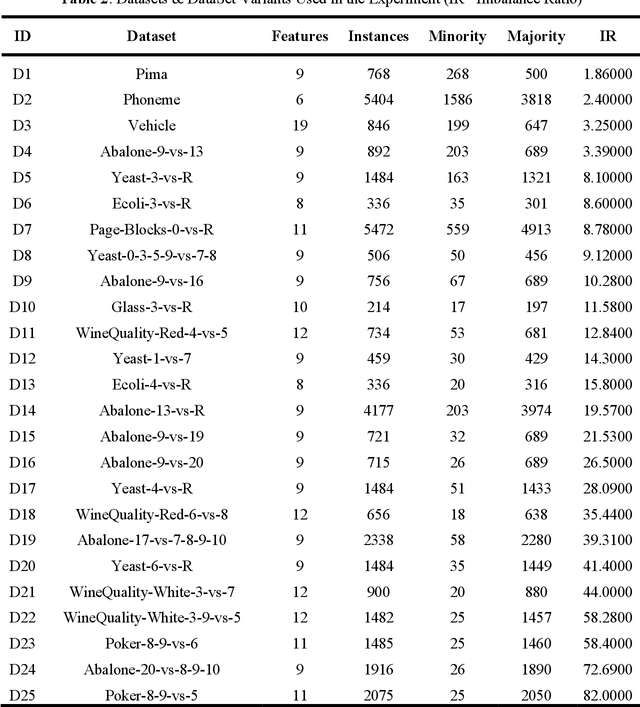
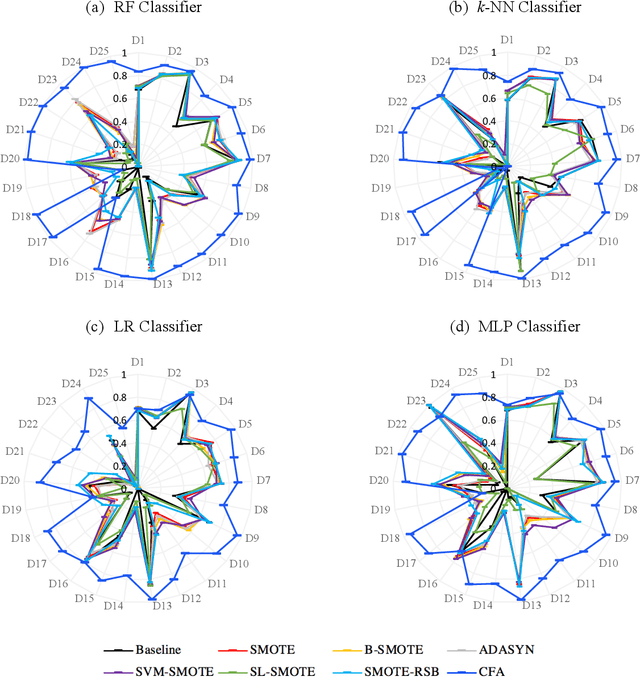
Learning from class imbalanced datasets poses challenges for many machine learning algorithms. Many real-world domains are, by definition, class imbalanced by virtue of having a majority class that naturally has many more instances than its minority class (e.g. genuine bank transactions occur much more often than fraudulent ones). Many methods have been proposed to solve the class imbalance problem, among the most popular being oversampling techniques (such as SMOTE). These methods generate synthetic instances in the minority class, to balance the dataset, performing data augmentations that improve the performance of predictive machine learning (ML) models. In this paper we advance a novel data augmentation method (adapted from eXplainable AI), that generates synthetic, counterfactual instances in the minority class. Unlike other oversampling techniques, this method adaptively combines exist-ing instances from the dataset, using actual feature-values rather than interpolating values between instances. Several experiments using four different classifiers and 25 datasets are reported, which show that this Counterfactual Augmentation method (CFA) generates useful synthetic data points in the minority class. The experiments also show that CFA is competitive with many other oversampling methods many of which are variants of SMOTE. The basis for CFAs performance is discussed, along with the conditions under which it is likely to perform better or worse in future tests.
Twin Systems for DeepCBR: A Menagerie of Deep Learning and Case-Based Reasoning Pairings for Explanation and Data Augmentation
Apr 29, 2021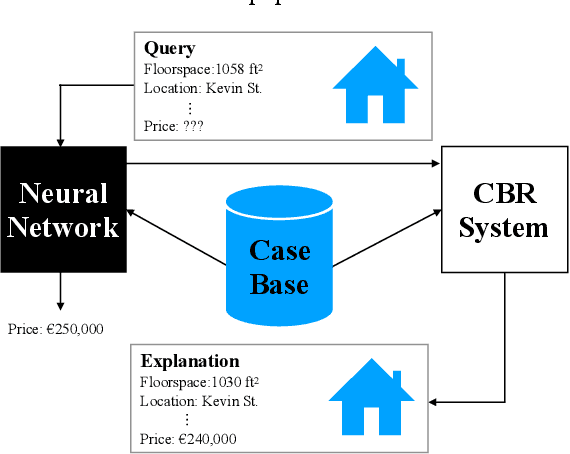
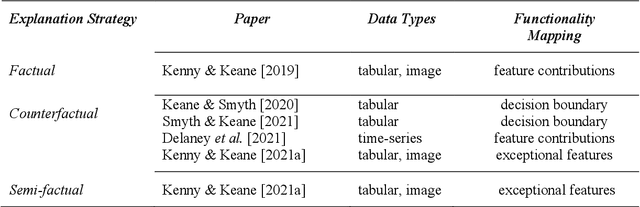
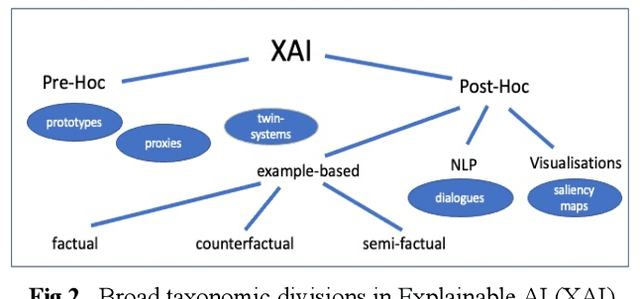

Recently, it has been proposed that fruitful synergies may exist between Deep Learning (DL) and Case Based Reasoning (CBR); that there are insights to be gained by applying CBR ideas to problems in DL (what could be called DeepCBR). In this paper, we report on a program of research that applies CBR solutions to the problem of Explainable AI (XAI) in the DL. We describe a series of twin-systems pairings of opaque DL models with transparent CBR models that allow the latter to explain the former using factual, counterfactual and semi-factual explanation strategies. This twinning shows that functional abstractions of DL (e.g., feature weights, feature importance and decision boundaries) can be used to drive these explanatory solutions. We also raise the prospect that this research also applies to the problem of Data Augmentation in DL, underscoring the fecundity of these DeepCBR ideas.
Handling Climate Change Using Counterfactuals: Using Counterfactuals in Data Augmentation to Predict Crop Growth in an Uncertain Climate Future
Apr 08, 2021

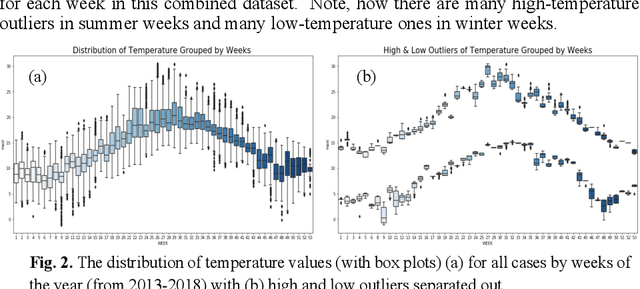
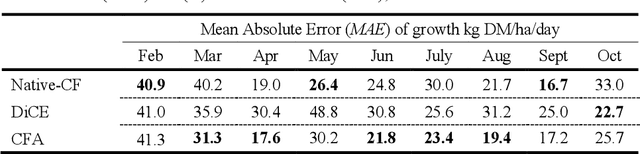
Climate change poses a major challenge to humanity, especially in its impact on agriculture, a challenge that a responsible AI should meet. In this paper, we examine a CBR system (PBI-CBR) designed to aid sustainable dairy farming by supporting grassland management, through accurate crop growth prediction. As climate changes, PBI-CBRs historical cases become less useful in predicting future grass growth. Hence, we extend PBI-CBR using data augmentation, to specifically handle disruptive climate events, using a counterfactual method (from XAI). Study 1 shows that historical, extreme climate-events (climate outlier cases) tend to be used by PBI-CBR to predict grass growth during climate disrupted periods. Study 2 shows that synthetic outliers, generated as counterfactuals on a outlier-boundary, improve the predictive accuracy of PBICBR, during the drought of 2018. This study also shows that an instance-based counterfactual method does better than a benchmark, constraint-guided method.