 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Class Imbalance Problem Using a Counterfactual Method for Data Augmentation
Paper and Code
Nov 05, 2021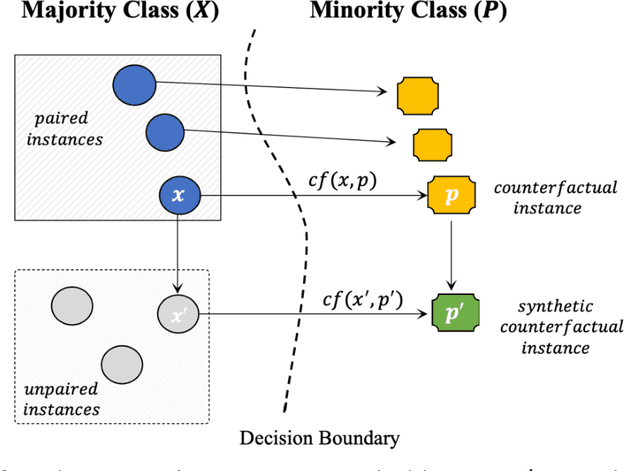
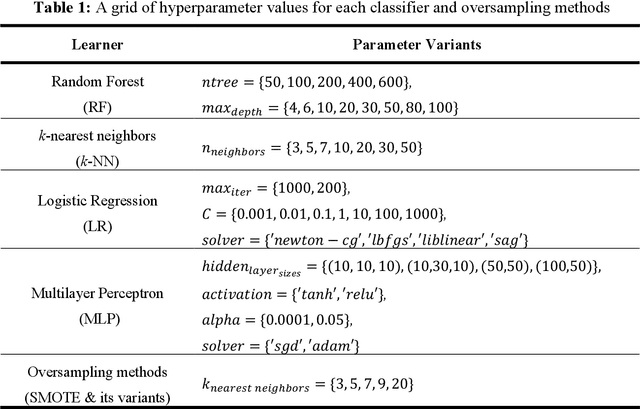
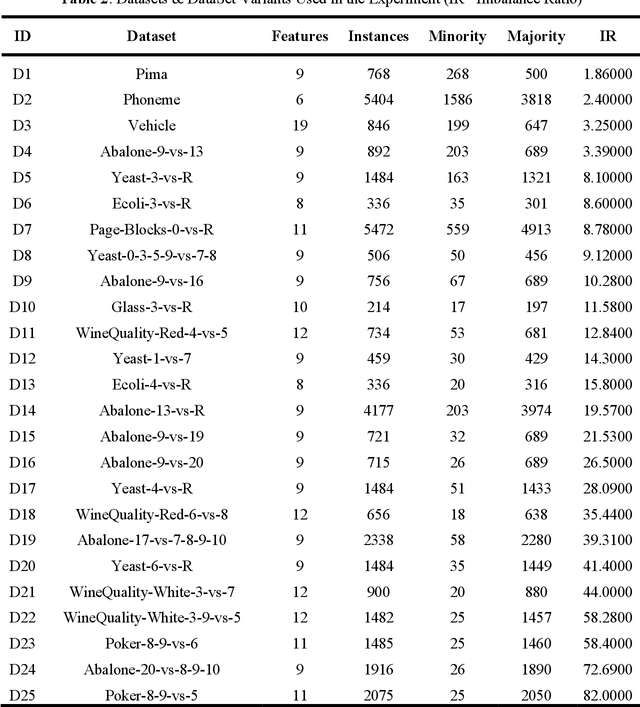
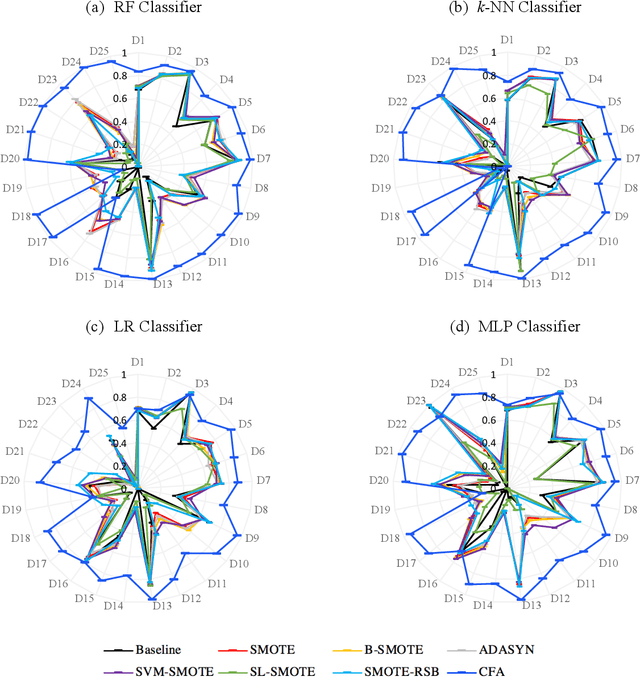
Learning from class imbalanced datasets poses challenges for many machine learning algorithms. Many real-world domains are, by definition, class imbalanced by virtue of having a majority class that naturally has many more instances than its minority class (e.g. genuine bank transactions occur much more often than fraudulent ones). Many methods have been proposed to solve the class imbalance problem, among the most popular being oversampling techniques (such as SMOTE). These methods generate synthetic instances in the minority class, to balance the dataset, performing data augmentations that improve the performance of predictive machine learning (ML) models. In this paper we advance a novel data augmentation method (adapted from eXplainable AI), that generates synthetic, counterfactual instances in the minority class. Unlike other oversampling techniques, this method adaptively combines exist-ing instances from the dataset, using actual feature-values rather than interpolating values between instances. Several experiments using four different classifiers and 25 datasets are reported, which show that this Counterfactual Augmentation method (CFA) generates useful synthetic data points in the minority class. The experiments also show that CFA is competitive with many other oversampling methods many of which are variants of SMOTE. The basis for CFAs performance is discussed, along with the conditions under which it is likely to perform better or worse in future tests.