 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMS-Trans: Recurrent Attention Multi-scale Transformer forFine-grained Image Recognition
Paper and Code
Jul 17, 2021
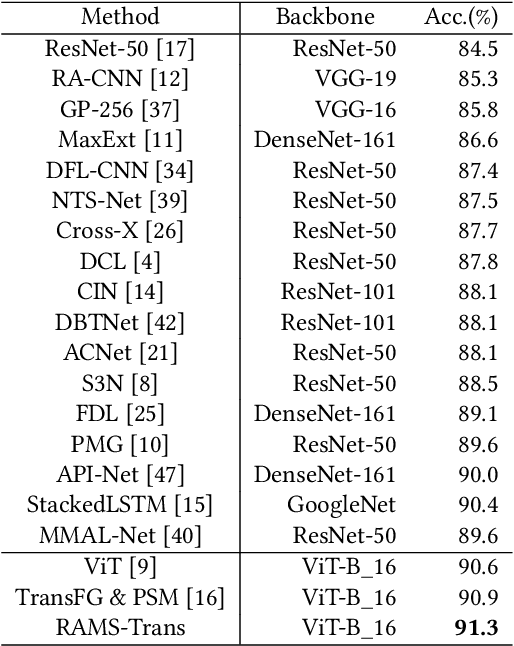
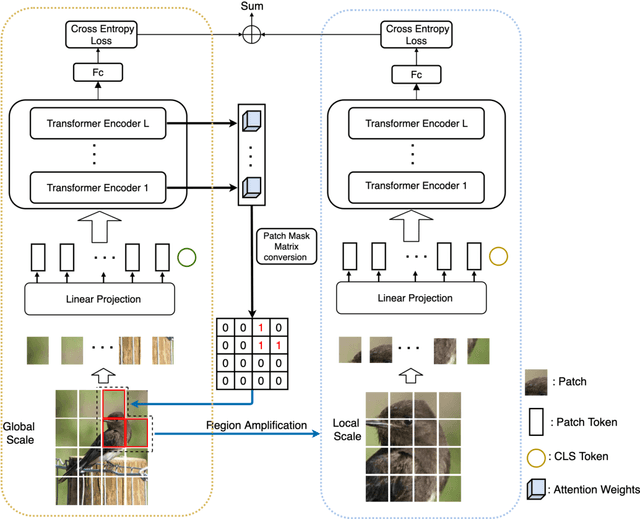
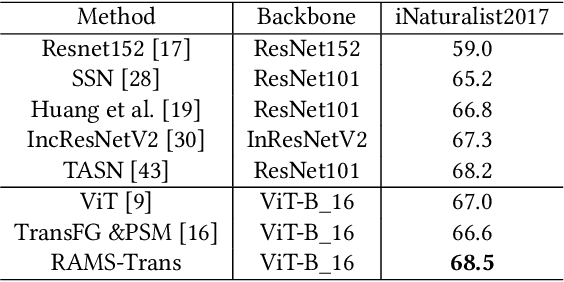
In fine-grained image recognition (FGIR), the localization and amplification of region attention is an important factor, which has been explored a lot by convolutional neural networks (CNNs) based approaches. The recently developed vision transformer (ViT) has achieved promising results on computer vision tasks. Compared with CNNs, Image sequentialization is a brand new manner. However, ViT is limited in its receptive field size and thus lacks local attention like CNNs due to the fixed size of its patches, and is unable to generate multi-scale features to learn discriminative region attention. To facilitate the learning of discriminative region attention without box/part annotations, we use the strength of the attention weights to measure the importance of the patch tokens corresponding to the raw images. We propose the recurrent attention multi-scale transformer (RAMS-Trans), which uses the transformer's self-attention to recursively learn discriminative region attention in a multi-scale manner. Specifically, at the core of our approach lies the dynamic patch proposal module (DPPM) guided region amplification to complete the integration of multi-scale image patches. The DPPM starts with the full-size image patches and iteratively scales up the region attention to generate new patches from global to local by the intensity of the attention weights generated at each scale as an indicator. Our approach requires only the attention weights that come with ViT itself and can be easily trained end-to-end. Extensive experiments demonstrate that RAMS-Trans performs better than concurrent works, in addition to efficient CNN models, achieving state-of-the-art results on three benchmark datasets.