 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
YuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
Apr 04, 2025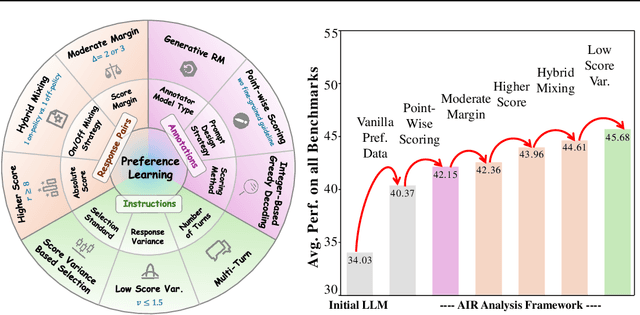
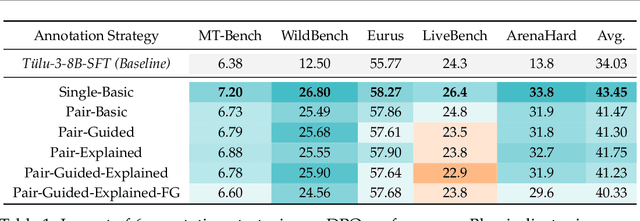
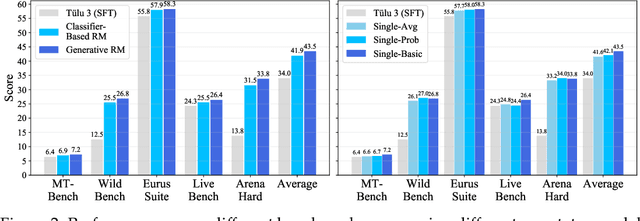

Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.
One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications
Dec 26, 2023The prevalent use of commercial and open-source diffusion models (DMs) for text-to-image generation prompts risk mitigation to prevent undesired behaviors. Existing concept erasing methods in academia are all based on full parameter or specification-based fine-tuning, from which we observe the following issues: 1) Generation alternation towards erosion: Parameter drift during target elimination causes alternations and potential deformations across all generations, even eroding other concepts at varying degrees, which is more evident with multi-concept erased; 2) Transfer inability & deployment inefficiency: Previous model-specific erasure impedes the flexible combination of concepts and the training-free transfer towards other models, resulting in linear cost growth as the deployment scenarios increase. To achieve non-invasive, precise, customizable, and transferable elimination, we ground our erasing framework on one-dimensional adapters to erase multiple concepts from most DMs at once across versatile erasing applications. The concept-SemiPermeable structure is injected as a Membrane (SPM) into any DM to learn targeted erasing, and meantime the alteration and erosion phenomenon is effectively mitigated via a novel Latent Anchoring fine-tuning strategy. Once obtained, SPMs can be flexibly combined and plug-and-play for other DMs without specific re-tuning, enabling timely and efficient adaptation to diverse scenarios. During generation, our Facilitated Transport mechanism dynamically regulates the permeability of each SPM to respond to different input prompts, further minimizing the impact on other concepts. Quantitative and qualitative results across ~40 concepts, 7 DMs and 4 erasing applications have demonstrated the superior erasing of SPM. Our code and pre-tuned SPMs will be available on the project page https://lyumengyao.github.io/projects/spm.
Diverse Instance Discovery: Vision-Transformer for Instance-Aware Multi-Label Image Recognition
Apr 22, 2022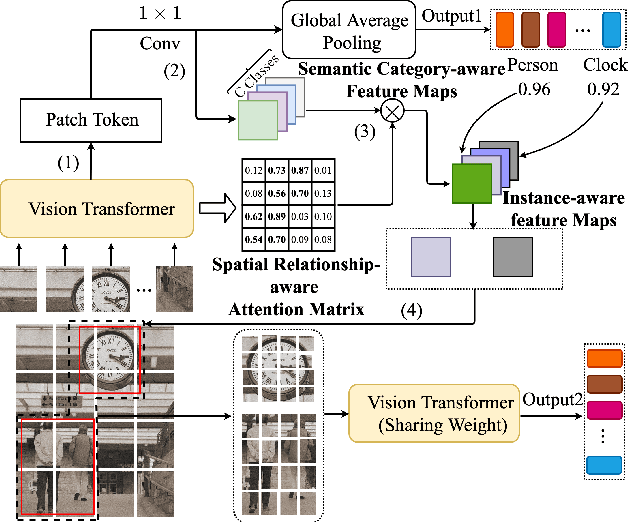
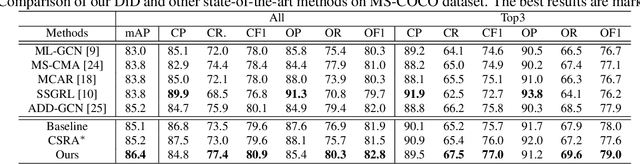
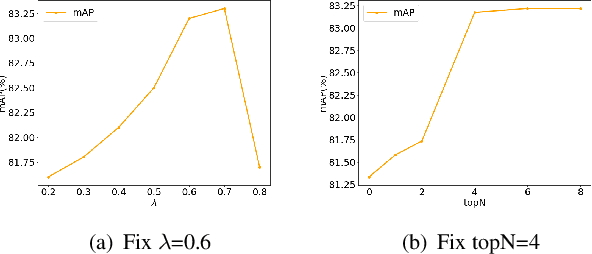
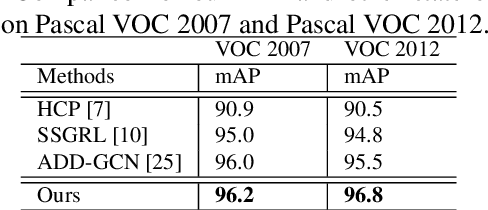
Previous works on multi-label image recognition (MLIR) usually use CNNs as a starting point for research. In this paper, we take pure Vision Transformer (ViT) as the research base and make full use of the advantages of Transformer with long-range dependency modeling to circumvent the disadvantages of CNNs limited to local receptive field. However, for multi-label images containing multiple objects from different categories, scales, and spatial relations, it is not optimal to use global information alone. Our goal is to leverage ViT's patch tokens and self-attention mechanism to mine rich instances in multi-label images, named diverse instance discovery (DiD). To this end, we propose a semantic category-aware module and a spatial relationship-aware module, respectively, and then combine the two by a re-constraint strategy to obtain instance-aware attention maps. Finally, we propose a weakly supervised object localization-based approach to extract multi-scale local features, to form a multi-view pipeline. Our method requires only weakly supervised information at the label level, no additional knowledge injection or other strongly supervised information is required. Experiments on three benchmark datasets show that our method significantly outperforms previous works and achieves state-of-the-art results under fair experimental comparisons.
DRDF: Determining the Importance of Different Multimodal Information with Dual-Router Dynamic Framework
Jul 21, 2021

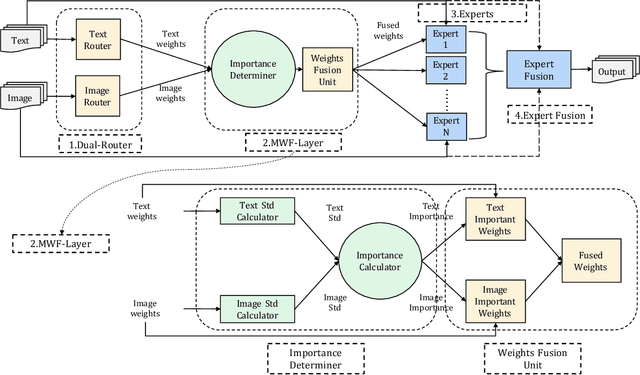
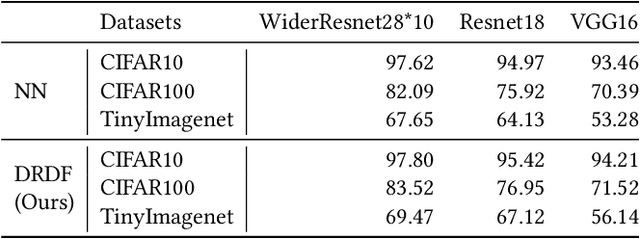
In multimodal tasks, we find that the importance of text and image modal information is different for different input cases, and for this motivation, we propose a high-performance and highly general Dual-Router Dynamic Framework (DRDF), consisting of Dual-Router, MWF-Layer, experts and expert fusion unit. The text router and image router in Dual-Router accept text modal information and image modal information, and use MWF-Layer to determine the importance of modal information. Based on the result of the determination, MWF-Layer generates fused weights for the fusion of experts. Experts are model backbones that match the current task. DRDF has high performance and high generality, and we have tested 12 backbones such as Visual BERT on multimodal dataset Hateful memes, unimodal dataset CIFAR10, CIFAR100, and TinyImagenet. Our DRDF outperforms all the baselines. We also verified the components of DRDF in detail by ablations, compared and discussed the reasons and ideas of DRDF design.
RAMS-Trans: Recurrent Attention Multi-scale Transformer forFine-grained Image Recognition
Jul 17, 2021
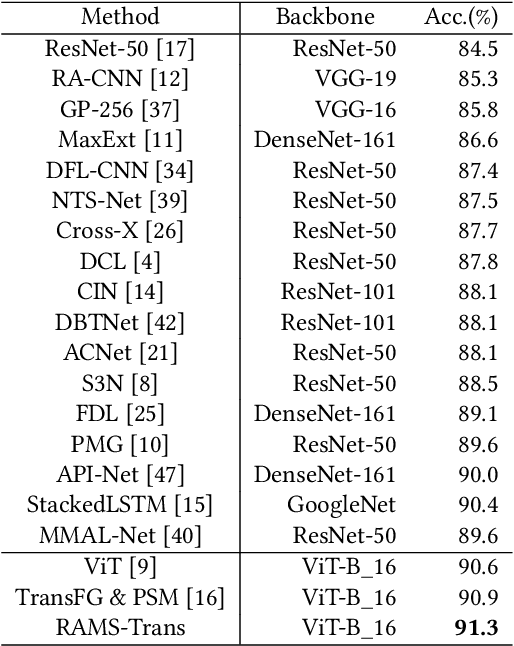
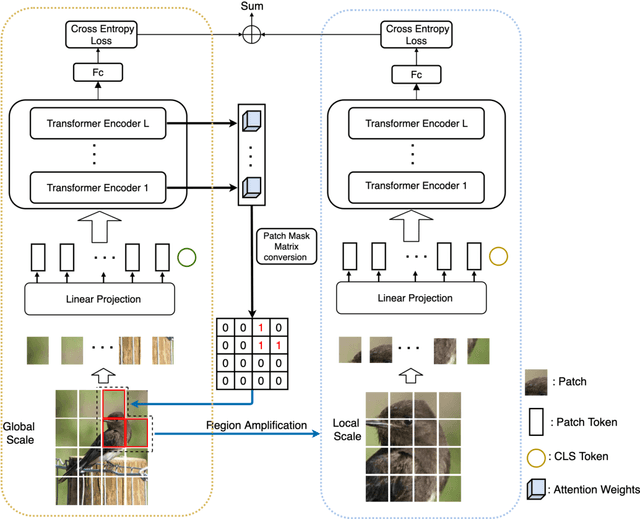
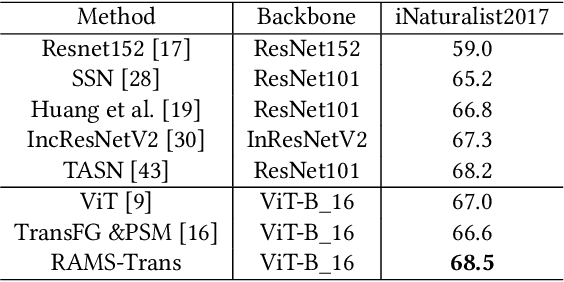
In fine-grained image recognition (FGIR), the localization and amplification of region attention is an important factor, which has been explored a lot by convolutional neural networks (CNNs) based approaches. The recently developed vision transformer (ViT) has achieved promising results on computer vision tasks. Compared with CNNs, Image sequentialization is a brand new manner. However, ViT is limited in its receptive field size and thus lacks local attention like CNNs due to the fixed size of its patches, and is unable to generate multi-scale features to learn discriminative region attention. To facilitate the learning of discriminative region attention without box/part annotations, we use the strength of the attention weights to measure the importance of the patch tokens corresponding to the raw images. We propose the recurrent attention multi-scale transformer (RAMS-Trans), which uses the transformer's self-attention to recursively learn discriminative region attention in a multi-scale manner. Specifically, at the core of our approach lies the dynamic patch proposal module (DPPM) guided region amplification to complete the integration of multi-scale image patches. The DPPM starts with the full-size image patches and iteratively scales up the region attention to generate new patches from global to local by the intensity of the attention weights generated at each scale as an indicator. Our approach requires only the attention weights that come with ViT itself and can be easily trained end-to-end. Extensive experiments demonstrate that RAMS-Trans performs better than concurrent works, in addition to efficient CNN models, achieving state-of-the-art results on three benchmark datasets.