 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRDF: Determining the Importance of Different Multimodal Information with Dual-Router Dynamic Framework
Paper and Code
Jul 21, 2021

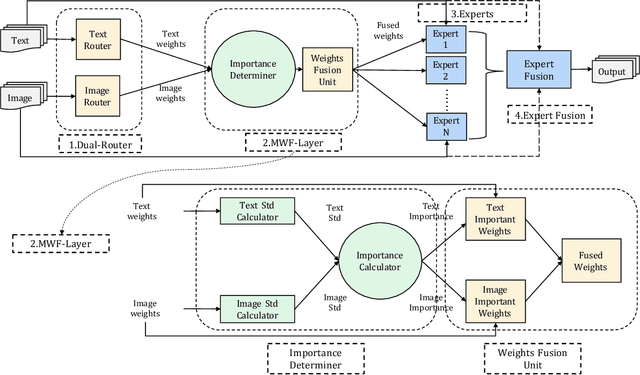
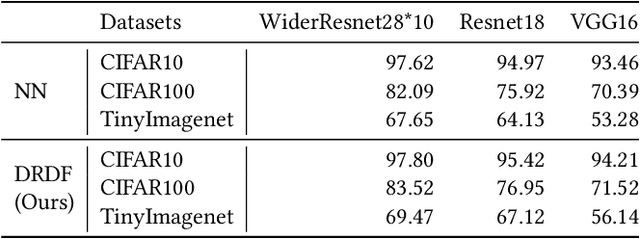
In multimodal tasks, we find that the importance of text and image modal information is different for different input cases, and for this motivation, we propose a high-performance and highly general Dual-Router Dynamic Framework (DRDF), consisting of Dual-Router, MWF-Layer, experts and expert fusion unit. The text router and image router in Dual-Router accept text modal information and image modal information, and use MWF-Layer to determine the importance of modal information. Based on the result of the determination, MWF-Layer generates fused weights for the fusion of experts. Experts are model backbones that match the current task. DRDF has high performance and high generality, and we have tested 12 backbones such as Visual BERT on multimodal dataset Hateful memes, unimodal dataset CIFAR10, CIFAR100, and TinyImagenet. Our DRDF outperforms all the baselines. We also verified the components of DRDF in detail by ablations, compared and discussed the reasons and ideas of DRDF design.