 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopPy: Opportunistically Exploiting Parallelism in Python Compound AI Applications
May 18, 2026Compound AI applications, which compose calls to ML models using a general-purpose programming language like Python, are widely used for a variety of user-facing tasks, from software engineering to enterprise automation, making their end-to-end latency a critical bottleneck. In contrast to traditional applications, execution time is dominated by the external components, which cannot be handled by traditional language optimization systems, like optimizing compilers. To address this problem, we develop PopPy, a system that can uncover parallelization opportunities in Python applications that invoke these heavy external components, including those used in compound AI applications. PopPy supports a very expressive fragment of Python and requires minimal developer input to uncover parallelism. It combines an ahead-of-time compiler with a runtime, addressing three key challenges in extracting parallelism from Python applications: language complexity, dynamic dispatch, and variable mutation. On a set of real-world compound AI applications, PopPy achieves up to $6.4\times$ speedups in end-to-end execution time compared to standard Python execution while preserving the sequential program semantics.
A Fast, Reliable, and Secure Programming Language for LLM Agents with Code Actions
Jun 13, 2025Modern large language models (LLMs) are often deployed as agents, calling external tools adaptively to solve tasks. Rather than directly calling tools, it can be more effective for LLMs to write code to perform the tool calls, enabling them to automatically generate complex control flow such as conditionals and loops. Such code actions are typically provided as Python code, since LLMs are quite proficient at it; however, Python may not be the ideal language due to limited built-in support for performance, security, and reliability. We propose a novel programming language for code actions, called Quasar, which has several benefits: (1) automated parallelization to improve performance, (2) uncertainty quantification to improve reliability and mitigate hallucinations, and (3) security features enabling the user to validate actions. LLMs can write code in a subset of Python, which is automatically transpiled to Quasar. We evaluate our approach on the ViperGPT visual question answering agent, applied to the GQA dataset, demonstrating that LLMs with Quasar actions instead of Python actions retain strong performance, while reducing execution time when possible by 42%, improving security by reducing user approval interactions when possible by 52%, and improving reliability by applying conformal prediction to achieve a desired target coverage level.
PAC Prediction Sets for Large Language Models of Code
Feb 17, 2023Prediction sets have recently been shown to be a promising strategy for quantifying the uncertainty of deep neural networks in a way that provides theoretical guarantees. However, existing techniques have largely targeted settings where the space of labels is simple, so prediction sets can be arbitrary subsets of labels. For structured prediction problems where the space of labels is exponential in size, even prediction sets containing a small fraction of all labels can be exponentially large. In the context of code generation, we propose a solution that considers a restricted set of prediction sets that can compactly be represented as partial programs, which are programs with portions replaced with holes. Given a trained code generation model, our algorithm leverages a programming language's abstract syntax tree to generate a set of programs such that the correct program is in the set with high-confidence. Valuable applications of our algorithm include a Codex-style code generator with holes in uncertain parts of the generated code, which provides a partial program with theoretical guarantees. We evaluate our approach on PICARD (a T5 model for SQL semantic parsing) and Codex (a GPT model for over a dozen programming languages, including Python), demonstrating that our approach generates compact PAC prediction sets. This is the first research contribution that generates PAC prediction sets for generative code models.
Counterfactual Explanations for Natural Language Interfaces
Apr 27, 2022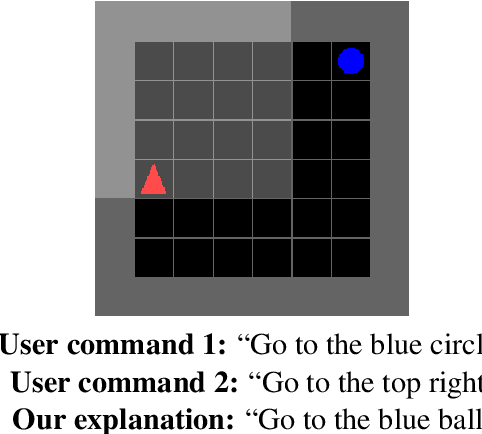

A key challenge facing natural language interfaces is enabling users to understand the capabilities of the underlying system. We propose a novel approach for generating explanations of a natural language interface based on semantic parsing. We focus on counterfactual explanations, which are post-hoc explanations that describe to the user how they could have minimally modified their utterance to achieve their desired goal. In particular, the user provides an utterance along with a demonstration of their desired goal; then, our algorithm synthesizes a paraphrase of their utterance that is guaranteed to achieve their goal. In two user studies, we demonstrate that our approach substantially improves user performance, and that it generates explanations that more closely match the user's intent compared to two ablations.
Safe Predictors for Enforcing Input-Output Specifications
Jan 29, 2020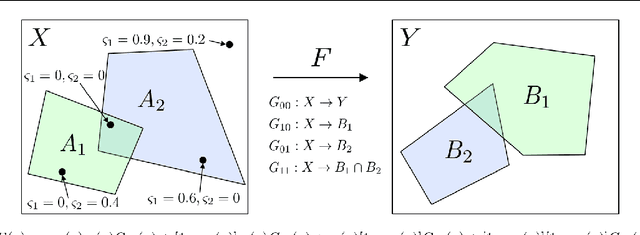


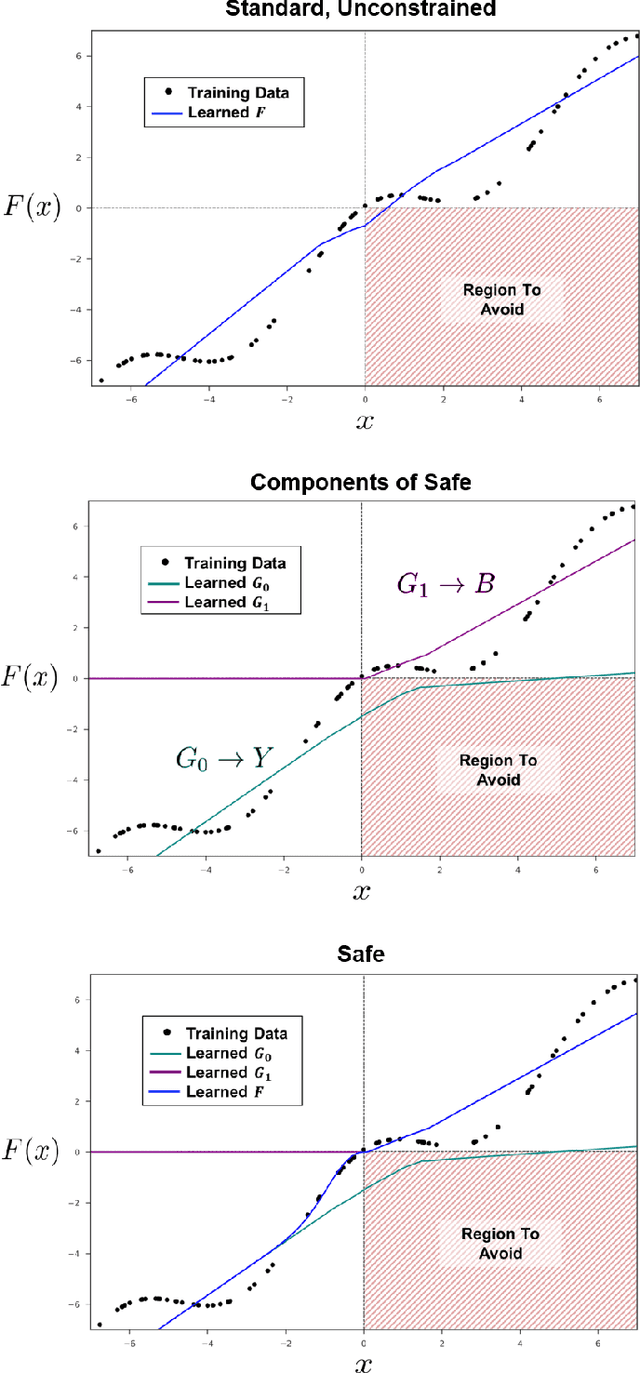
We present an approach for designing correct-by-construction neural networks (and other machine learning models) that are guaranteed to be consistent with a collection of input-output specifications before, during, and after algorithm training. Our method involves designing a constrained predictor for each set of compatible constraints, and combining them safely via a convex combination of their predictions. We demonstrate our approach on synthetic datasets and an aircraft collision avoidance problem.