 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntibiotic Resistance Microbiology Dataset (ARMD): A De-identified Resource for Studying Antimicrobial Resistance Using Electronic Health Records
Mar 08, 2025The Antibiotic Resistance Microbiology Dataset (ARMD) is a de-identified resource derived from electronic health records (EHR) that facilitates research into antimicrobial resistance (AMR). ARMD encompasses data from adult patients, focusing on microbiological cultures, antibiotic susceptibilities, and associated clinical and demographic features. Key attributes include organism identification, susceptibility patterns for 55 antibiotics, implied susceptibility rules, and de-identified patient information. This dataset supports studies on antimicrobial stewardship, causal inference, and clinical decision-making. ARMD is designed to be reusable and interoperable, promoting collaboration and innovation in combating AMR. This paper describes the dataset's acquisition, structure, and utility while detailing its de-identification process.
Identifying Differential Patient Care Through Inverse Intent Inference
Nov 11, 2024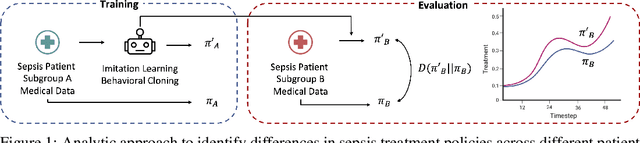


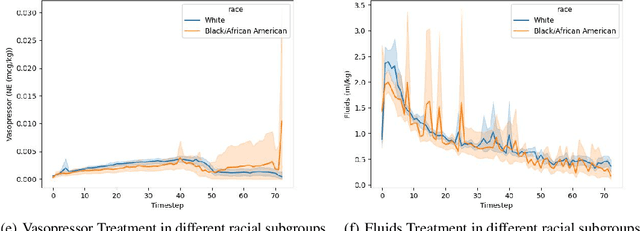
Sepsis is a life-threatening condition defined by end-organ dysfunction due to a dysregulated host response to infection. Although the Surviving Sepsis Campaign has launched and has been releasing sepsis treatment guidelines to unify and normalize the care for sepsis patients, it has been reported in numerous studies that disparities in care exist across the trajectory of patient stay in the emergency department and intensive care unit. Here, we apply a number of reinforcement learning techniques including behavioral cloning, imitation learning, and inverse reinforcement learning, to learn the optimal policy in the management of septic patient subgroups using expert demonstrations. Then we estimate the counterfactual optimal policies by applying the model to another subset of unseen medical populations and identify the difference in cure by comparing it to the real policy. Our data comes from the sepsis cohort of MIMIC-IV and the clinical data warehouses of the Mass General Brigham healthcare system. The ultimate objective of this work is to use the optimal learned policy function to estimate the counterfactual treatment policy and identify deviations across sub-populations of interest. We hope this approach would help us identify any disparities in care and also changes in cure in response to the publication of national sepsis treatment guidelines.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Trajectory Inspection: A Method for Iterative Clinician-Driven Design of Reinforcement Learning Studies
Oct 08, 2020
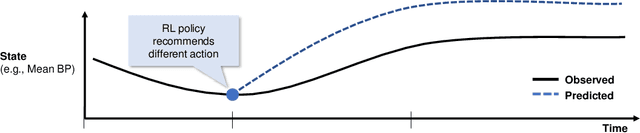

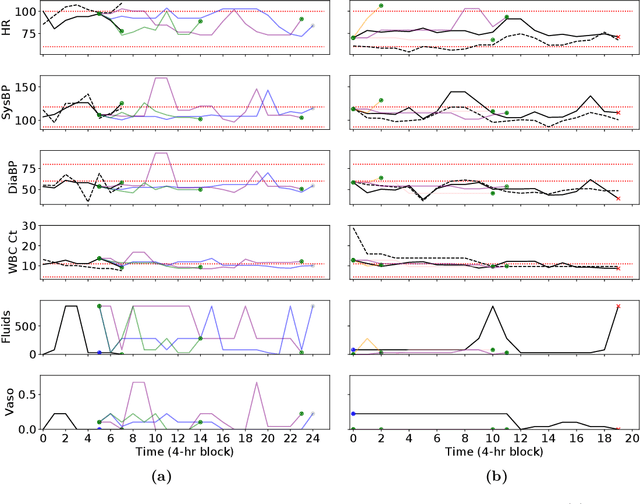
Treatment policies learned via reinforcement learning (RL) from observational health data are sensitive to subtle choices in study design. We highlight a simple approach, trajectory inspection, to bring clinicians into an iterative design process for model-based RL studies. We inspect trajectories where the model recommends unexpectedly aggressive treatments or believes its recommendations would lead to much more positive outcomes. Then, we examine clinical trajectories simulated with the learned model and policy alongside the actual hospital course to uncover possible modeling issues. To demonstrate that this approach yields insights, we apply it to recent work on RL for inpatient sepsis management. We find that a design choice around maximum trajectory length leads to a model bias towards discharge, that the RL policy preference for high vasopressor doses may be linked to small sample sizes, and that the model has a clinically implausible expectation of discharge without weaning off vasopressors.
Treatment Policy Learning in Multiobjective Settings with Fully Observed Outcomes
Jun 01, 2020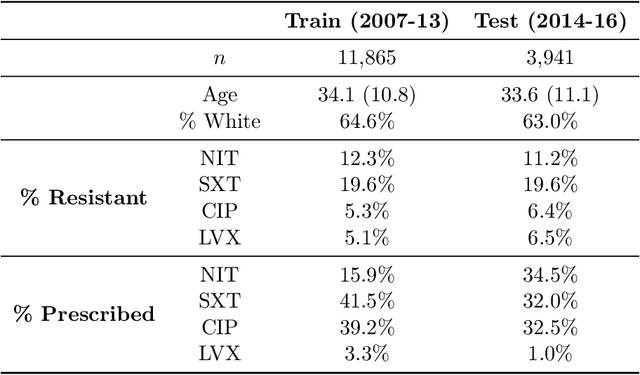
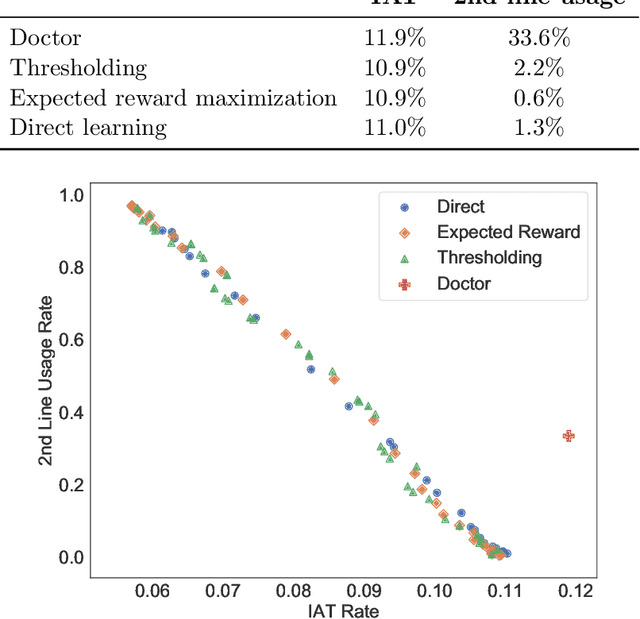
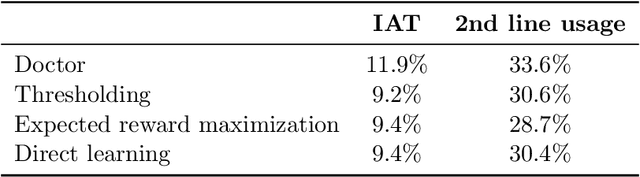
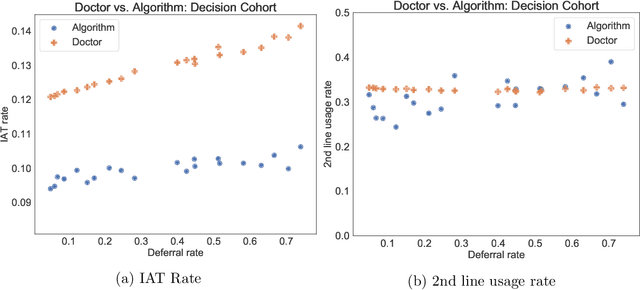
In several medical decision-making problems, such as antibiotic prescription, laboratory testing can provide precise indications for how a patient will respond to different treatment options. This enables us to "fully observe" all potential treatment outcomes, but while present in historical data, these results are infeasible to produce in real-time at the point of the initial treatment decision. Moreover, treatment policies in these settings often need to trade off between multiple competing objectives, such as effectiveness of treatment and harmful side effects. We present, compare, and evaluate three approaches for learning individualized treatment policies in this setting: First, we consider two indirect approaches, which use predictive models of treatment response to construct policies optimal for different trade-offs between objectives. Second, we consider a direct approach that constructs such a set of policies without any intermediate models of outcomes. Using a medical dataset of Urinary Tract Infection (UTI) patients, we show that all approaches are able to find policies that achieve strictly better performance on all outcomes than clinicians, while also trading off between different objectives as desired. We demonstrate additional benefits of the direct approach, including flexibly incorporating other goals such as deferral to physicians on simple cases.