 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
May 03, 2024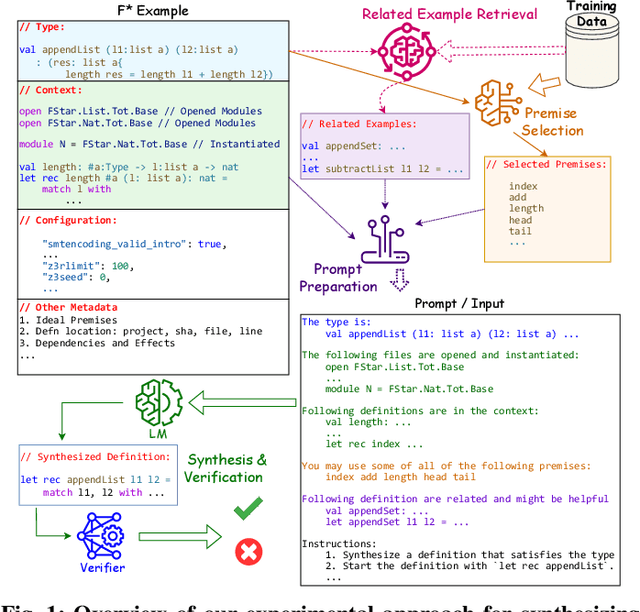
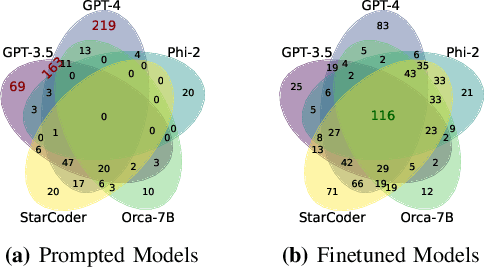
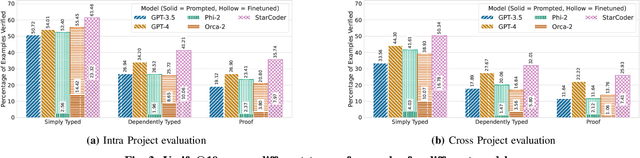
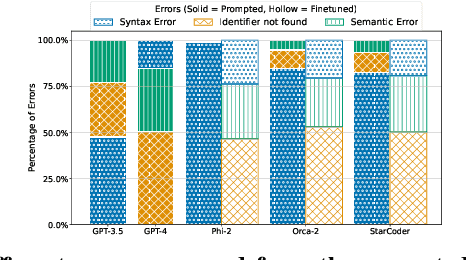
Proof-oriented programs mix computational content with proofs of program correctness. However, the human effort involved in programming and proving is still substantial, despite the use of Satisfiability Modulo Theories (SMT) solvers to automate proofs in languages such as F*. Seeking to spur research on using AI to automate the construction of proof-oriented programs, we curate a dataset of 600K lines of open-source F* programs and proofs, including software used in production systems ranging from Windows and Linux, to Python and Firefox. Our dataset includes around 32K top-level F* definitions, each representing a type-directed program and proof synthesis problem -- producing a definition given a formal specification expressed as an F* type. We provide a program-fragment checker that queries F* to check the correctness of candidate solutions. We believe this is the largest corpus of SMT-assisted program proofs coupled with a reproducible program-fragment checker. Grounded in this dataset, we investigate the use of AI to synthesize programs and their proofs in F*, with promising results. Our main finding in that the performance of fine-tuned smaller language models (such as Phi-2 or StarCoder) compare favorably with large language models (such as GPT-4), at a much lower computational cost. We also identify various type-based retrieval augmentation techniques and find that they boost performance significantly. With detailed error analysis and case studies, we identify potential strengths and weaknesses of models and techniques and suggest directions for future improvements.
Black-Box Prediction of Flaky Test Fix Categories Using Language Models
Jun 21, 2023



Flaky tests are problematic because they non-deterministically pass or fail for the same software version under test, causing confusion and wasting developer time. While machine learning models have been used to predict flakiness and its root causes, there is less work on providing support to fix the problem. To address this gap, we propose a framework that automatically generates labeled datasets for 13 fix categories and train models to predict the fix category of a flaky test by analyzing the test code only. Though it is unrealistic at this stage to accurately predict the fix itself, the categories provide precise guidance about what part of the test code to look at. Our approach is based on language models, namely CodeBERT and UniXcoder, whose output is fine-tuned with a Feed Forward Neural Network (FNN) or a Siamese Network-based Few Shot Learning (FSL). Our experimental results show that UniXcoder outperforms CodeBERT, in correctly predicting most of the categories of fixes a developer should apply. Furthermore, FSL does not appear to have any significant effect. Given the high accuracy obtained for most fix categories, our proposed framework has the potential to help developers to fix flaky tests quickly and accurately.To aid future research, we make our automated labeling tool, dataset, prediction models, and experimental infrastructure publicly available.