 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBongards at the Boundary of Perception and Reasoning: Programs or Language?
Feb 03, 2026Vision-Language Models (VLMs) have made great strides in everyday visual tasks, such as captioning a natural image, or answering commonsense questions about such images. But humans possess the puzzling ability to deploy their visual reasoning abilities in radically new situations, a skill rigorously tested by the classic set of visual reasoning challenges known as the Bongard problems. We present a neurosymbolic approach to solving these problems: given a hypothesized solution rule for a Bongard problem, we leverage LLMs to generate parameterized programmatic representations for the rule and perform parameter fitting using Bayesian optimization. We evaluate our method on classifying Bongard problem images given the ground truth rule, as well as on solving the problems from scratch.
OmniCode: A Benchmark for Evaluating Software Engineering Agents
Feb 02, 2026LLM-powered coding agents are redefining how real-world software is developed. To drive the research towards better coding agents, we require challenging benchmarks that can rigorously evaluate the ability of such agents to perform various software engineering tasks. However, popular coding benchmarks such as HumanEval and SWE-Bench focus on narrowly scoped tasks such as competition programming and patch generation. In reality, software engineers have to handle a broader set of tasks for real-world software development. To address this gap, we propose OmniCode, a novel software engineering benchmark that contains a broader and more diverse set of task categories beyond code or patch generation. Overall, OmniCode contains 1794 tasks spanning three programming languages (Python, Java, and C++) and four key categories: bug fixing, test generation, code review fixing, and style fixing. In contrast to prior software engineering benchmarks, the tasks in OmniCode are (1) manually validated to eliminate ill-defined problems, and (2) synthetically crafted or recently curated to avoid data leakage issues, presenting a new framework for synthetically generating diverse software tasks from limited real-world data. We evaluate OmniCode with popular agent frameworks such as SWE-Agent and show that while they may perform well on bug fixing for Python, they fall short on tasks such as Test Generation and in languages such as C++ and Java. For instance, SWE-Agent achieves a maximum of 20.9% with DeepSeek-V3.1 on Java Test Generation tasks. OmniCode aims to serve as a robust benchmark and spur the development of agents that can perform well across different aspects of software development. Code and data are available at https://github.com/seal-research/OmniCode.
Do AI Models Perform Human-like Abstract Reasoning Across Modalities?
Oct 02, 2025OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models' abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models' rules are often based on surface-level ``shortcuts'' and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models' output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models' abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.
Memento: Note-Taking for Your Future Self
Jun 25, 2025Large language models (LLMs) excel at reasoning-only tasks, but struggle when reasoning must be tightly coupled with retrieval, as in multi-hop question answering. To overcome these limitations, we introduce a prompting strategy that first decomposes a complex question into smaller steps, then dynamically constructs a database of facts using LLMs, and finally pieces these facts together to solve the question. We show how this three-stage strategy, which we call Memento, can boost the performance of existing prompting strategies across diverse settings. On the 9-step PhantomWiki benchmark, Memento doubles the performance of chain-of-thought (CoT) when all information is provided in context. On the open-domain version of 2WikiMultiHopQA, CoT-RAG with Memento improves over vanilla CoT-RAG by more than 20 F1 percentage points and over the multi-hop RAG baseline, IRCoT, by more than 13 F1 percentage points. On the challenging MuSiQue dataset, Memento improves ReAct by more than 3 F1 percentage points, demonstrating its utility in agentic settings.
Citegeist: Automated Generation of Related Work Analysis on the arXiv Corpus
Mar 29, 2025



Large Language Models provide significant new opportunities for the generation of high-quality written works. However, their employment in the research community is inhibited by their tendency to hallucinate invalid sources and lack of direct access to a knowledge base of relevant scientific articles. In this work, we present Citegeist: An application pipeline using dynamic Retrieval Augmented Generation (RAG) on the arXiv Corpus to generate a related work section and other citation-backed outputs. For this purpose, we employ a mixture of embedding-based similarity matching, summarization, and multi-stage filtering. To adapt to the continuous growth of the document base, we also present an optimized way of incorporating new and modified papers. To enable easy utilization in the scientific community, we release both, a website (https://citegeist.org), as well as an implementation harness that works with several different LLM implementations.
CoCoNUT: Structural Code Understanding does not fall out of a tree
Jan 29, 2025

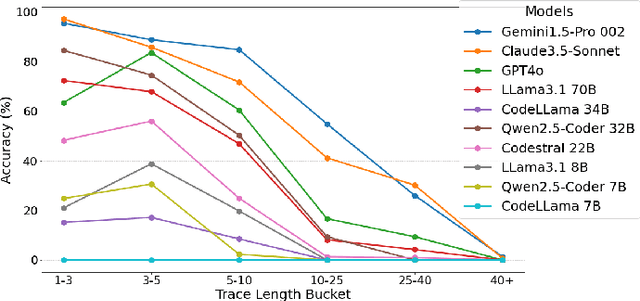

Large Language Models (LLMs) have shown impressive performance across a wide array of tasks involving both structured and unstructured textual data. Recent results on various benchmarks for code generation, repair, or completion suggest that certain models have programming abilities comparable to or even surpass humans. In this work, we demonstrate that high performance on such benchmarks does not correlate to humans' innate ability to understand structural control flow in code. To this end, we extract solutions from the HumanEval benchmark, which the relevant models perform strongly on, and trace their execution path using function calls sampled from the respective test set. Using this dataset, we investigate the ability of seven state-of-the-art LLMs to match the execution trace and find that, despite their ability to generate semantically identical code, they possess limited ability to trace execution paths, especially for longer traces and specific control structures. We find that even the top-performing model, Gemini, can fully and correctly generate only 47% of HumanEval task traces. Additionally, we introduce a subset for three key structures not contained in HumanEval: Recursion, Parallel Processing, and Object-Oriented Programming, including concepts like Inheritance and Polymorphism. Besides OOP, we show that none of the investigated models achieve an accuracy over 5% on the relevant traces. Aggregating these specialized parts with HumanEval tasks, we present CoCoNUT: Code Control Flow for Navigation Understanding and Testing, which measures a model's ability to trace execution of code upon relevant calls, including advanced structural components. We conclude that current LLMs need significant improvement to enhance code reasoning abilities. We hope our dataset helps researchers bridge this gap.
Unlocking Transparent Alignment Through Enhanced Inverse Constitutional AI for Principle Extraction
Jan 28, 2025Traditional methods for aligning Large Language Models (LLMs), such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), rely on implicit principles, limiting interpretability. Constitutional AI (CAI) offers an explicit, rule-based framework for guiding model outputs. Building on this, we refine the Inverse Constitutional AI (ICAI) algorithm, which extracts constitutions from preference datasets. By improving principle generation, clustering, and embedding processes, our approach enhances the accuracy and generalizability of extracted principles across synthetic and real-world datasets. While in-context alignment yields modest improvements, our results highlight the potential of these principles to foster more transparent and adaptable alignment methods, offering a promising direction for future advancements beyond traditional fine-tuning.