 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvCodeMix: Adversarial Attack on Code-Mixed Data
Paper and Code
Oct 30, 2021


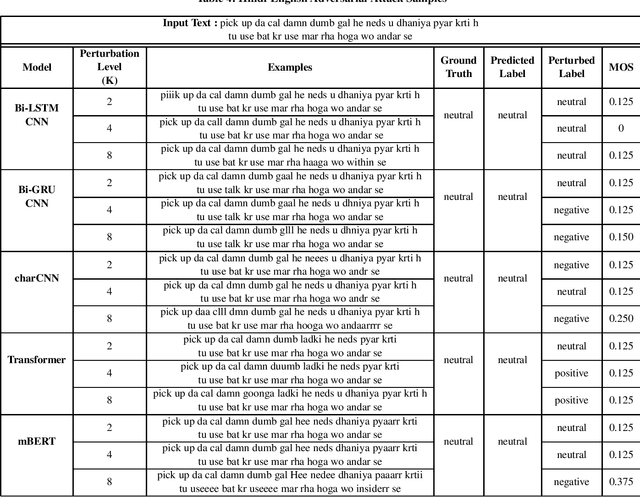
Research on adversarial attacks are becoming widely popular in the recent years. One of the unexplored areas where prior research is lacking is the effect of adversarial attacks on code-mixed data. Therefore, in the present work, we have explained the first generalized framework on text perturbation to attack code-mixed classification models in a black-box setting. We rely on various perturbation techniques that preserve the semantic structures of the sentences and also obscure the attacks from the perception of a human user. The present methodology leverages the importance of a token to decide where to attack by employing various perturbation strategies. We test our strategies on various sentiment classification models trained on Bengali-English and Hindi-English code-mixed datasets, and reduce their F1-scores by nearly 51 % and 53 % respectively, which can be further reduced if a larger number of tokens are perturbed in a given sentence.