Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for Language Identification in Code-Mixed Low Resource Languages
Paper and Code
Oct 31, 2018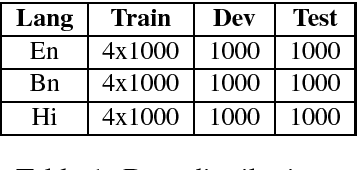
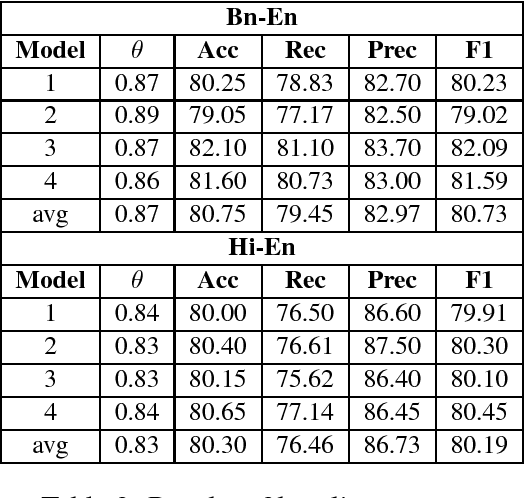
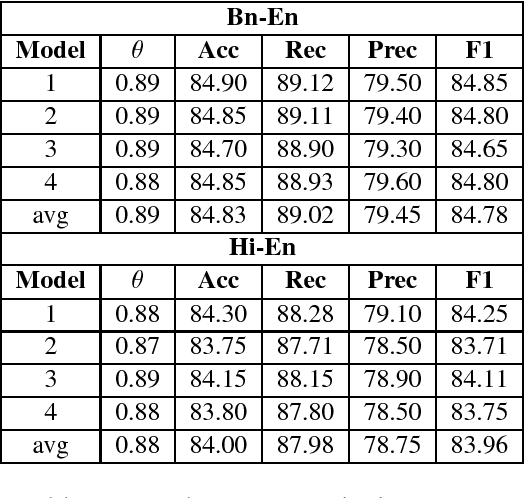
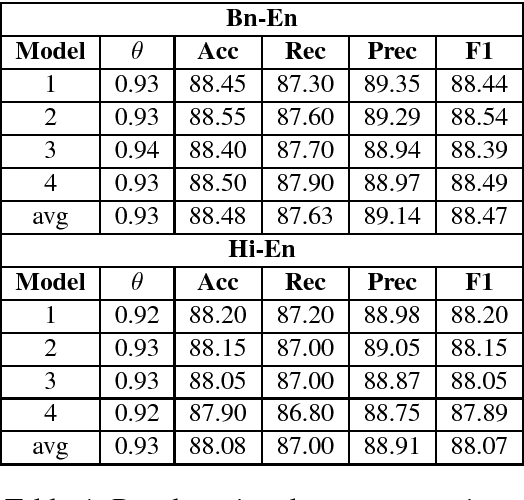
In recent years, substantial work has been done on language tagging of code-mixed data, but most of them use large amounts of data to build their models. In this article, we present three strategies to build a word level language tagger for code-mixed data using very low resources. Each of them secured an accuracy higher than our baseline model, and the best performing system got an accuracy around 91%. Combining all, the ensemble system achieved an accuracy of around 92.6%.
* International Conference on Natural Language Processing (ICON 18) -
Student Paper Competition, Patiala, India
View paper on