 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUNLP@SemEval-2020 Task 9:Sentiment Analysis of Hindi-English code mixed data using Grid Search Cross Validation
Paper and Code
Sep 02, 2020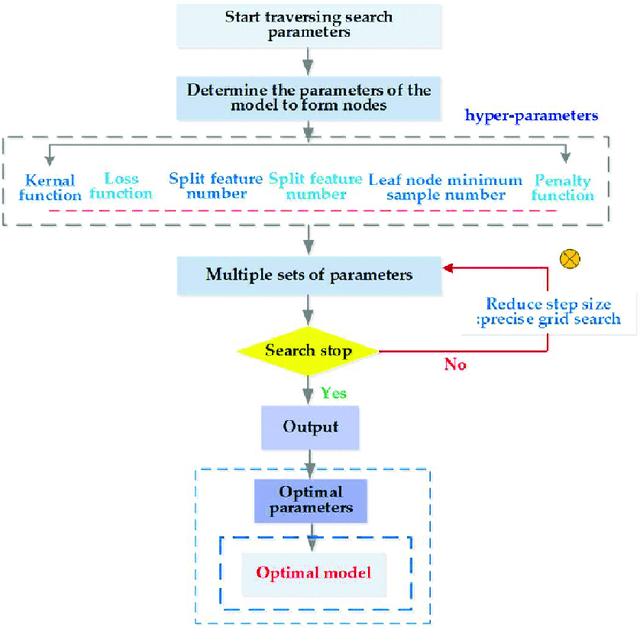
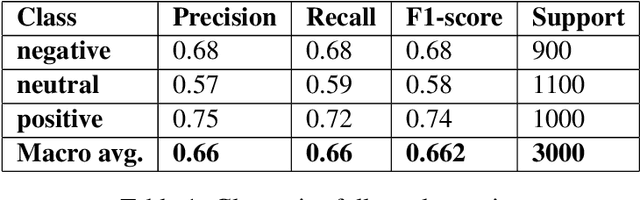
Code-mixing is a phenomenon which arises mainly in multilingual societies. Multilingual people, who are well versed in their native languages and also English speakers, tend to code-mix using English-based phonetic typing and the insertion of anglicisms in their main language. This linguistic phenomenon poses a great challenge to conventional NLP domains such as Sentiment Analysis, Machine Translation, and Text Summarization, to name a few. In this work, we focus on working out a plausible solution to the domain of Code-Mixed Sentiment Analysis. This work was done as participation in the SemEval-2020 Sentimix Task, where we focused on the sentiment analysis of English-Hindi code-mixed sentences. our username for the submission was "sainik.mahata" and team name was "JUNLP". We used feature extraction algorithms in conjunction with traditional machine learning algorithms such as SVR and Grid Search in an attempt to solve the task. Our approach garnered an f1-score of 66.2\% when tested using metrics prepared by the organizers of the task.