 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocQAC: Adaptive Trie-Guided Decoding for Effective In-Document Query Auto-Completion
Apr 20, 2026Query auto-completion (QAC) has been widely studied in the context of web search, yet remains underexplored for in-document search, which we term DocQAC. DocQAC aims to enhance search productivity within long documents by helping users craft faster, more precise queries, even for complex or hard-to-spell terms. While global historical queries are available to both WebQAC and DocQAC, DocQAC uniquely accesses document-specific context, including the current document's content and its specific history of user query interactions. To address this setting, we propose a novel adaptive trie-guided decoding framework that uses user query prefixes to softly steer language models toward high-quality completions. Our approach introduces an adaptive penalty mechanism with tunable hyperparameters, enabling a principled trade-off between model confidence and trie-based guidance. To efficiently incorporate document context, we explore retrieval-augmented generation (RAG) and lightweight contextual document signals such as titles, keyphrases, and summaries. When applied to encoder-decoder models like T5 and BART, our trie-guided framework outperforms strong baselines and even surpasses much larger instruction-tuned models such as LLaMA-3 and Phi-3 on seen queries across both seen and unseen documents. This demonstrates its practicality for real-world DocQAC deployments, where efficiency and scalability are critical. We evaluate our method on a newly introduced DocQAC benchmark derived from ORCAS, enriched with query-document pairs. We make both the DocQAC dataset (https://bit.ly/3IGEkbH) and code (https://github.com/rahcode7/DocQAC) publicly available.
MetaCheckGPT -- A Multi-task Hallucination Detector Using LLM Uncertainty and Meta-models
Apr 11, 2024Hallucinations in large language models (LLMs) have recently become a significant problem. A recent effort in this direction is a shared task at Semeval 2024 Task 6, SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. This paper describes our winning solution ranked 1st and 2nd in the 2 sub-tasks of model agnostic and model aware tracks respectively. We propose a meta-regressor framework of LLMs for model evaluation and integration that achieves the highest scores on the leaderboard. We also experiment with various transformer-based models and black box methods like ChatGPT, Vectara, and others. In addition, we perform an error analysis comparing GPT4 against our best model which shows the limitations of the former.
LLM-RM at SemEval-2023 Task 2: Multilingual Complex NER using XLM-RoBERTa
May 05, 2023Named Entity Recognition(NER) is a task of recognizing entities at a token level in a sentence. This paper focuses on solving NER tasks in a multilingual setting for complex named entities. Our team, LLM-RM participated in the recently organized SemEval 2023 task, Task 2: MultiCoNER II,Multilingual Complex Named Entity Recognition. We approach the problem by leveraging cross-lingual representation provided by fine-tuning XLM-Roberta base model on datasets of all of the 12 languages provided -- Bangla, Chinese, English, Farsi, French, German, Hindi, Italian, Portuguese, Spanish, Swedish and Ukrainian
Correlated Mixed Membership Modeling of Somatic Mutations
May 21, 2020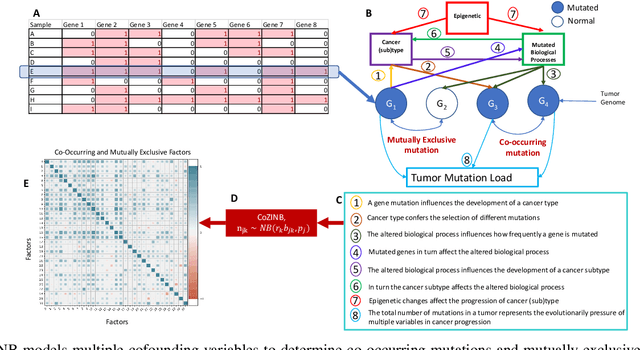
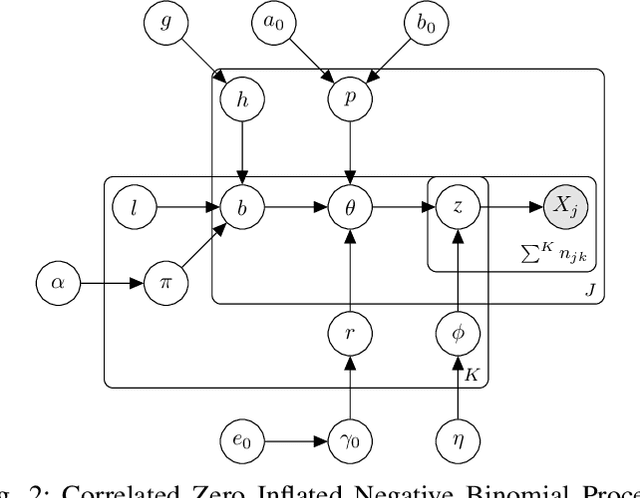
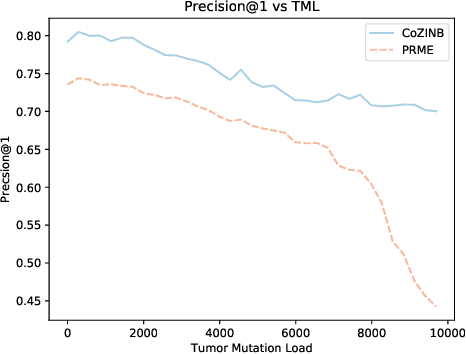
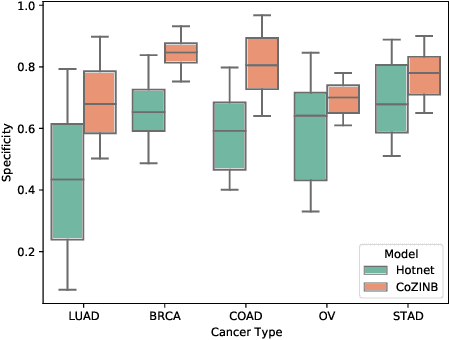
Recent studies of cancer somatic mutation profiles seek to identify mutations for targeted therapy in personalized medicine. Analysis of profiles, however, is not trivial, as each profile is heterogeneous and there are multiple confounding factors that influence the cause-and-effect relationships between cancer genes such as cancer (sub)type, biological processes, total number of mutations, and non-linear mutation interactions. Moreover, cancer is biologically redundant, i.e., distinct mutations can result in the alteration of similar biological processes, so it is important to identify all possible combinatorial sets of mutations for effective patient treatment. To model this phenomena, we propose the correlated zero-inflated negative binomial process to infer the inherent structure of somatic mutation profiles through latent representations. This stochastic process takes into account different, yet correlated, co-occurring mutations using profile-specific negative binomial dispersion parameters that are mixed with a correlated beta-Bernoulli process and a probability parameter to model profile heterogeneity. These model parameters are inferred by iterative optimization via amortized and stochastic variational inference using the Pan Cancer dataset from The Cancer Genomic Archive (TCGA). By examining the the latent space, we identify biologically relevant correlations between somatic mutations.
Sparse Transfer Learning via Winning Lottery Tickets
May 19, 2019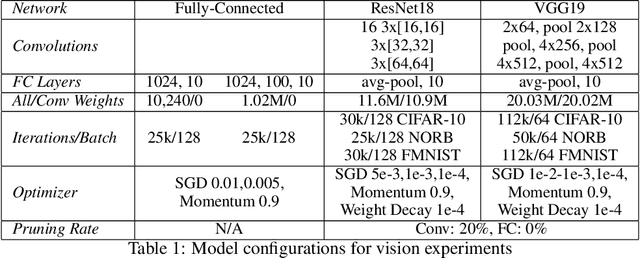
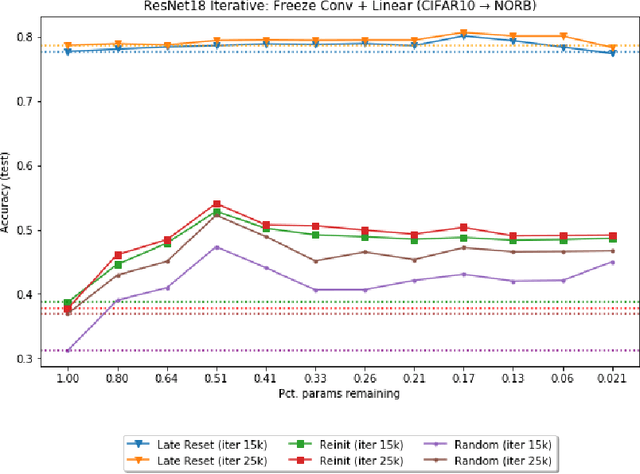
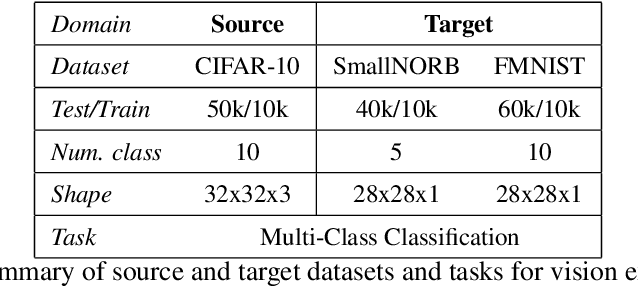
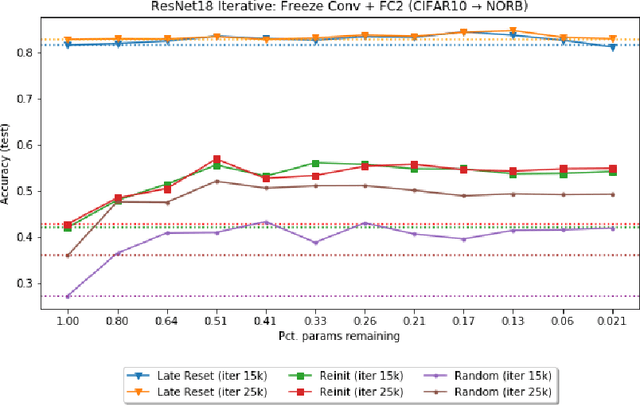
The recently proposed Lottery Ticket Hypothesis of Frankle and Carbin (2019) suggests that the performance of over-parameterized deep networks is due to the random initialization seeding the network with a small fraction of favorable weights. These weights retain their dominant status throughout training -- in a very real sense, this sub-network "won the lottery" during initialization. The authors find sub-networks via unstructured magnitude pruning with 85-95% of parameters removed that train to the same accuracy as the original network at a similar speed, which they call winning tickets. In this paper, we extend the Lottery Ticket Hypothesis to a variety of transfer learning tasks. We show that sparse sub-networks with approximately 90-95% of weights removed achieve (and often exceed) the accuracy of the original dense network in several realistic settings. We experimentally validate this by transferring the sparse representation found via pruning on CIFAR-10 to SmallNORB and FashionMNIST for object recognition tasks.