 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Transfer Learning via Winning Lottery Tickets
Paper and Code
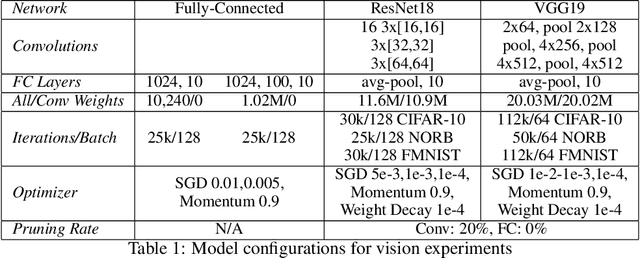
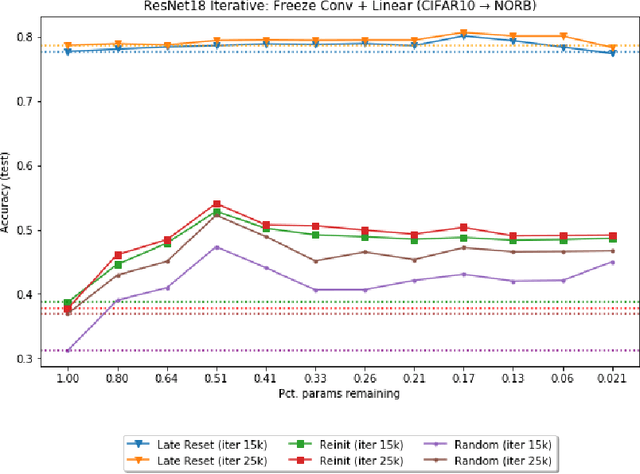
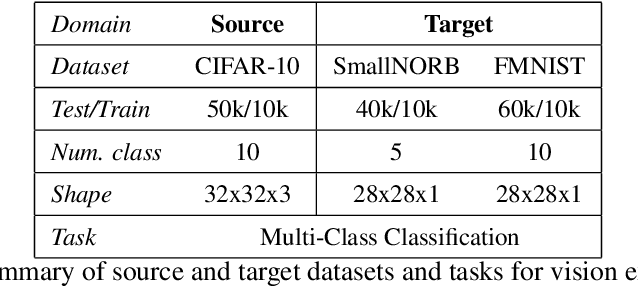
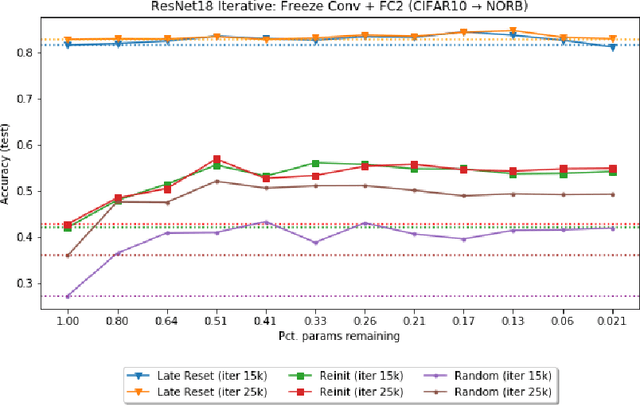
The recently proposed Lottery Ticket Hypothesis of Frankle and Carbin (2019) suggests that the performance of over-parameterized deep networks is due to the random initialization seeding the network with a small fraction of favorable weights. These weights retain their dominant status throughout training -- in a very real sense, this sub-network "won the lottery" during initialization. The authors find sub-networks via unstructured magnitude pruning with 85-95% of parameters removed that train to the same accuracy as the original network at a similar speed, which they call winning tickets. In this paper, we extend the Lottery Ticket Hypothesis to a variety of transfer learning tasks. We show that sparse sub-networks with approximately 90-95% of weights removed achieve (and often exceed) the accuracy of the original dense network in several realistic settings. We experimentally validate this by transferring the sparse representation found via pruning on CIFAR-10 to SmallNORB and FashionMNIST for object recognition tasks.