 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of domain-specific transformer models with text oversampling for sentiment analysis of social media posts on Covid-19 vaccines
Sep 22, 2022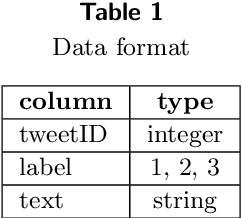
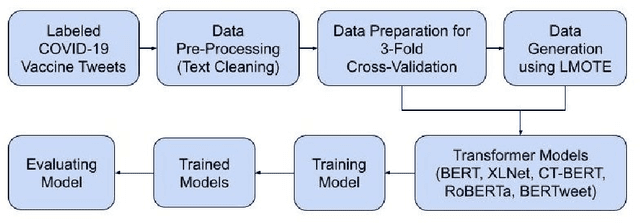


Covid-19 has spread across the world and several vaccines have been developed to counter its surge. To identify the correct sentiments associated with the vaccines from social media posts, we fine-tune various state-of-the-art pre-trained transformer models on tweets associated with Covid-19 vaccines. Specifically, we use the recently introduced state-of-the-art pre-trained transformer models RoBERTa, XLNet and BERT, and the domain-specific transformer models CT-BERT and BERTweet that are pre-trained on Covid-19 tweets. We further explore the option of text augmentation by oversampling using Language Model based Oversampling Technique (LMOTE) to improve the accuracies of these models, specifically, for small sample datasets where there is an imbalanced class distribution among the positive, negative and neutral sentiment classes. Our results summarize our findings on the suitability of text oversampling for imbalanced small sample datasets that are used to fine-tune state-of-the-art pre-trained transformer models, and the utility of domain-specific transformer models for the classification task.