 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpidemic Modeling using Hybrid of Time-varying SIRD, Particle Swarm Optimization, and Deep Learning
Jan 31, 2024



Epidemiological models are best suitable to model an epidemic if the spread pattern is stationary. To deal with non-stationary patterns and multiple waves of an epidemic, we develop a hybrid model encompassing epidemic modeling, particle swarm optimization, and deep learning. The model mainly caters to three objectives for better prediction: 1. Periodic estimation of the model parameters. 2. Incorporating impact of all the aspects using data fitting and parameter optimization 3. Deep learning based prediction of the model parameters. In our model, we use a system of ordinary differential equations (ODEs) for Susceptible-Infected-Recovered-Dead (SIRD) epidemic modeling, Particle Swarm Optimization (PSO) for model parameter optimization, and stacked-LSTM for forecasting the model parameters. Initial or one time estimation of model parameters is not able to model multiple waves of an epidemic. So, we estimate the model parameters periodically (weekly). We use PSO to identify the optimum values of the model parameters. We next train the stacked-LSTM on the optimized parameters, and perform forecasting of the model parameters for upcoming four weeks. Further, we fed the LSTM forecasted parameters into the SIRD model to forecast the number of COVID-19 cases. We evaluate the model for highly affected three countries namely; the USA, India, and the UK. The proposed hybrid model is able to deal with multiple waves, and has outperformed existing methods on all the three datasets.
Adaptation of domain-specific transformer models with text oversampling for sentiment analysis of social media posts on Covid-19 vaccines
Sep 22, 2022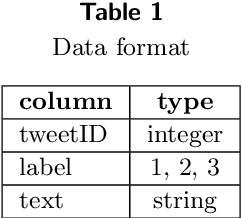
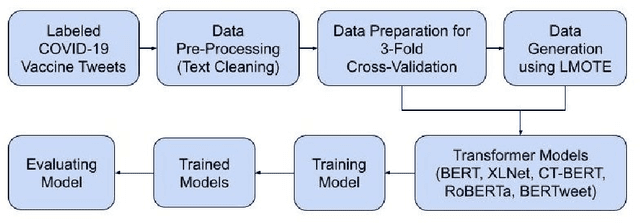


Covid-19 has spread across the world and several vaccines have been developed to counter its surge. To identify the correct sentiments associated with the vaccines from social media posts, we fine-tune various state-of-the-art pre-trained transformer models on tweets associated with Covid-19 vaccines. Specifically, we use the recently introduced state-of-the-art pre-trained transformer models RoBERTa, XLNet and BERT, and the domain-specific transformer models CT-BERT and BERTweet that are pre-trained on Covid-19 tweets. We further explore the option of text augmentation by oversampling using Language Model based Oversampling Technique (LMOTE) to improve the accuracies of these models, specifically, for small sample datasets where there is an imbalanced class distribution among the positive, negative and neutral sentiment classes. Our results summarize our findings on the suitability of text oversampling for imbalanced small sample datasets that are used to fine-tune state-of-the-art pre-trained transformer models, and the utility of domain-specific transformer models for the classification task.
Emotion-Aware Transformer Encoder for Empathetic Dialogue Generation
Apr 24, 2022

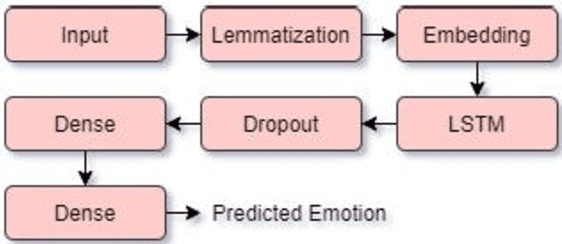

Modern day conversational agents are trained to emulate the manner in which humans communicate. To emotionally bond with the user, these virtual agents need to be aware of the affective state of the user. Transformers are the recent state of the art in sequence-to-sequence learning that involves training an encoder-decoder model with word embeddings from utterance-response pairs. We propose an emotion-aware transformer encoder for capturing the emotional quotient in the user utterance in order to generate human-like empathetic responses. The contributions of our paper are as follows: 1) An emotion detector module trained on the input utterances determines the affective state of the user in the initial phase 2) A novel transformer encoder is proposed that adds and normalizes the word embedding with emotion embedding thereby integrating the semantic and affective aspects of the input utterance 3) The encoder and decoder stacks belong to the Transformer-XL architecture which is the recent state of the art in language modeling. Experimentation on the benchmark Facebook AI empathetic dialogue dataset confirms the efficacy of our model from the higher BLEU-4 scores achieved for the generated responses as compared to existing methods. Emotionally intelligent virtual agents are now a reality and inclusion of affect as a modality in all human-machine interfaces is foreseen in the immediate future.
Improving Word Recognition in Speech Transcriptions by Decision-level Fusion of Stemming and Two-way Phoneme Pruning
Jul 26, 2021
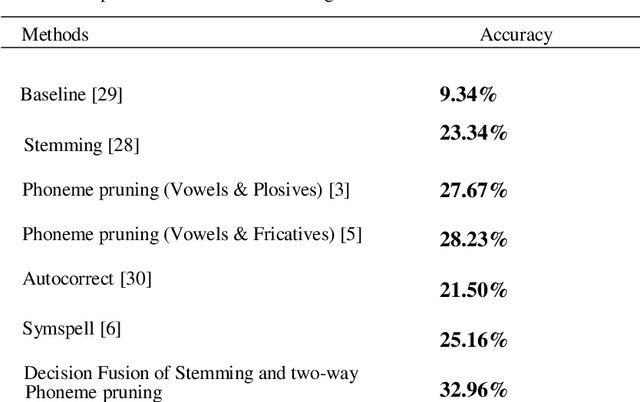


We introduce an unsupervised approach for correcting highly imperfect speech transcriptions based on a decision-level fusion of stemming and two-way phoneme pruning. Transcripts are acquired from videos by extracting audio using Ffmpeg framework and further converting audio to text transcript using Google API. In the benchmark LRW dataset, there are 500 word categories, and 50 videos per class in mp4 format. All videos consist of 29 frames (each 1.16 s long) and the word appears in the middle of the video. In our approach we tried to improve the baseline accuracy from 9.34% by using stemming, phoneme extraction, filtering and pruning. After applying the stemming algorithm to the text transcript and evaluating the results, we achieved 23.34% accuracy in word recognition. To convert words to phonemes we used the Carnegie Mellon University (CMU) pronouncing dictionary that provides a phonetic mapping of English words to their pronunciations. A two-way phoneme pruning is proposed that comprises of the two non-sequential steps: 1) filtering and pruning the phonemes containing vowels and plosives 2) filtering and pruning the phonemes containing vowels and fricatives. After obtaining results of stemming and two-way phoneme pruning, we applied decision-level fusion and that led to an improvement of word recognition rate upto 32.96%.
A Hybrid Model for Combining Neural Image Caption and k-Nearest Neighbor Approach for Image Captioning
May 09, 2021

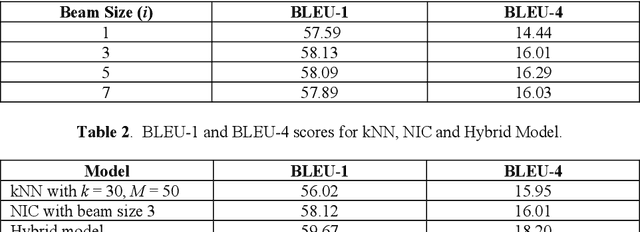

A hybrid model is proposed that integrates two popular image captioning methods to generate a text-based summary describing the contents of the image. The two image captioning models are the Neural Image Caption (NIC) and the k-nearest neighbor approach. These are trained individually on the training set. We extract a set of five features, from the validation set, for evaluating the results of the two models that in turn is used to train a logistic regression classifier. The BLEU-4 scores of the two models are compared for generating the binary-value ground truth for the logistic regression classifier. For the test set, the input images are first passed separately through the two models to generate the individual captions. The five-dimensional feature set extracted from the two models is passed to the logistic regression classifier to take a decision regarding the final caption generated which is the best of two captions generated by the models. Our implementation of the k-nearest neighbor model achieves a BLEU-4 score of 15.95 and the NIC model achieves a BLEU-4 score of 16.01, on the benchmark Flickr8k dataset. The proposed hybrid model is able to achieve a BLEU-4 score of 18.20 proving the validity of our approach.
Evaluating Deep Neural Network Ensembles by Majority Voting cum Meta-Learning scheme
May 09, 2021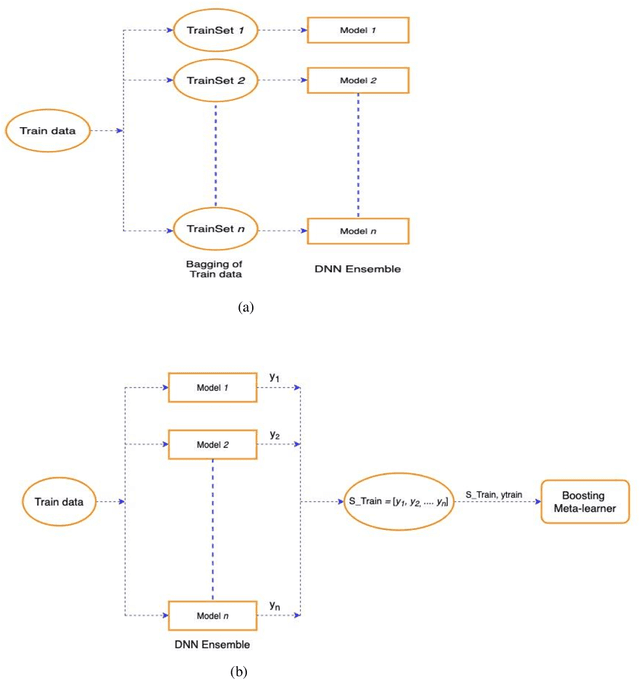



Deep Neural Networks (DNNs) are prone to overfitting and hence have high variance. Overfitted networks do not perform well for a new data instance. So instead of using a single DNN as classifier we propose an ensemble of seven independent DNN learners by varying only the input to these DNNs keeping their architecture and intrinsic properties same. To induce variety in the training input, for each of the seven DNNs, one-seventh of the data is deleted and replenished by bootstrap sampling from the remaining samples. We have proposed a novel technique for combining the prediction of the DNN learners in the ensemble. Our method is called pre-filtering by majority voting coupled with stacked meta-learner which performs a two-step confi-dence check for the predictions before assigning the final class labels. All the algorithms in this paper have been tested on five benchmark datasets name-ly, Human Activity Recognition (HAR), Gas sensor array drift, Isolet, Spam-base and Internet advertisements. Our ensemble approach achieves higher accuracy than a single DNN and the average individual accuracies of DNNs in the ensemble, as well as the baseline approaches of plurality voting and meta-learning.
A Novel Framework for Neural Architecture Search in the Hill Climbing Domain
Feb 22, 2021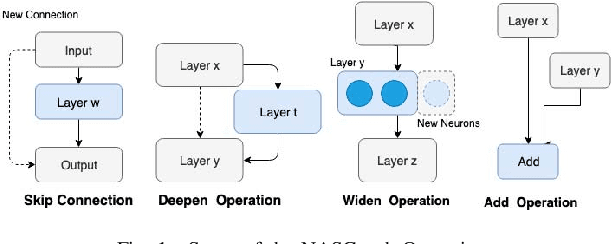
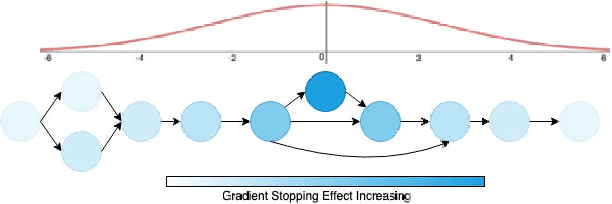
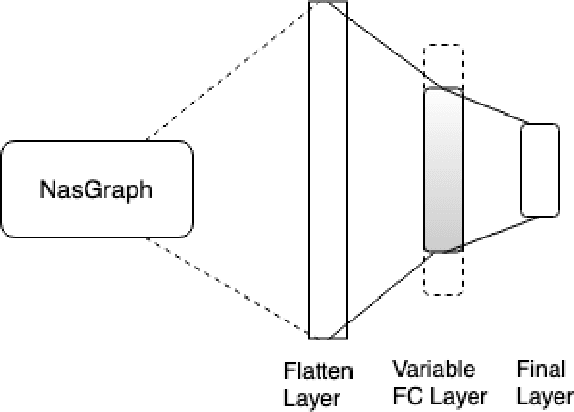
Neural networks have now long been used for solving complex problems of image domain, yet designing the same needs manual expertise. Furthermore, techniques for automatically generating a suitable deep learning architecture for a given dataset have frequently made use of reinforcement learning and evolutionary methods which take extensive computational resources and time. We propose a new framework for neural architecture search based on a hill-climbing procedure using morphism operators that makes use of a novel gradient update scheme. The update is based on the aging of neural network layers and results in the reduction in the overall training time. This technique can search in a broader search space which subsequently yields competitive results. We achieve a 4.96% error rate on the CIFAR-10 dataset in 19.4 hours of a single GPU training.
Context- and Sequence-Aware Convolutional Recurrent Encoder for Neural Machine Translation
Jan 11, 2021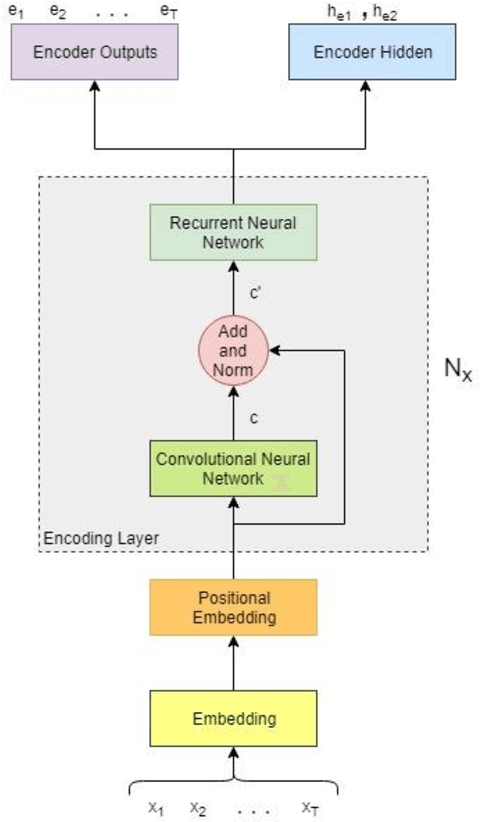
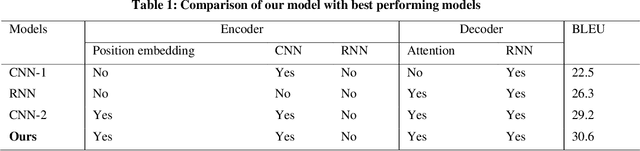
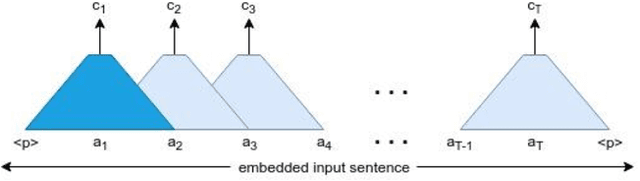
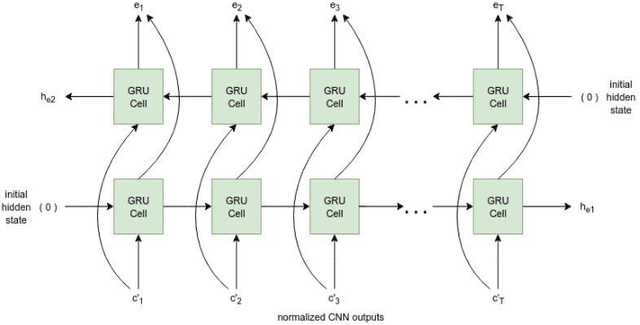
Neural Machine Translation model is a sequence-to-sequence converter based on neural networks. Existing models use recurrent neural networks to construct both the encoder and decoder modules. In alternative research, the recurrent networks were substituted by convolutional neural networks for capturing the syntactic structure in the input sentence and decreasing the processing time. We incorporate the goodness of both approaches by proposing a convolutional-recurrent encoder for capturing the context information as well as the sequential information from the source sentence. Word embedding and position embedding of the source sentence is performed prior to the convolutional encoding layer which is basically a n-gram feature extractor capturing phrase-level context information. The rectified output of the convolutional encoding layer is added to the original embedding vector, and the sum is normalized by layer normalization. The normalized output is given as a sequential input to the recurrent encoding layer that captures the temporal information in the sequence. For the decoder, we use the attention-based recurrent neural network. Translation task on the German-English dataset verifies the efficacy of the proposed approach from the higher BLEU scores achieved as compared to the state of the art.
Speaker Recognition using SincNet and X-Vector Fusion
Apr 05, 2020
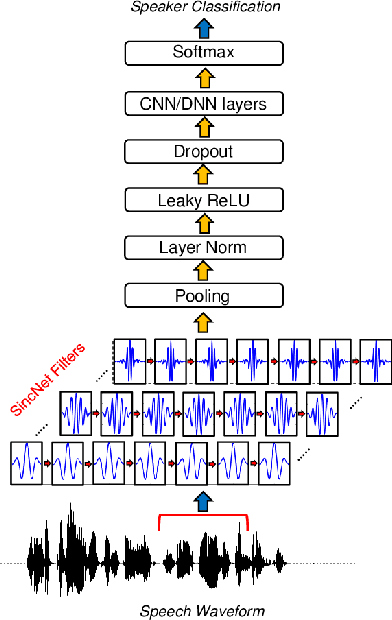
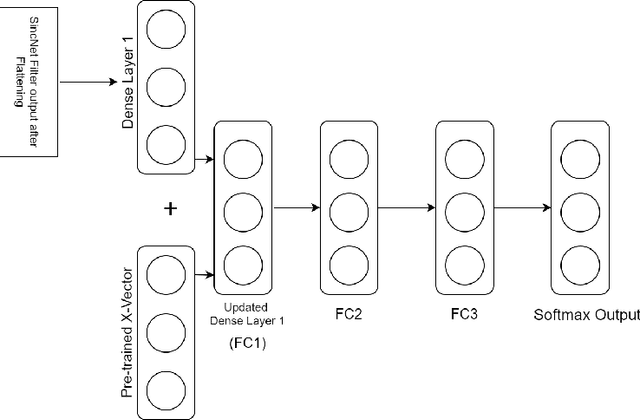
In this paper, we propose an innovative approach to perform speaker recognition by fusing two recently introduced deep neural networks (DNNs) namely - SincNet and X-Vector. The idea behind using SincNet filters on the raw speech waveform is to extract more distinguishing frequency-related features in the initial convolution layers of the CNN architecture. X-Vectors are used to take advantage of the fact that this embedding is an efficient method to churn out fixed dimension features from variable length speech utterances, something which is challenging in plain CNN techniques, making it efficient both in terms of speed and accuracy. Our approach uses the best of both worlds by combining X-vector in the later layers while using SincNet filters in the initial layers of our deep model. This approach allows the network to learn better embedding and converge quicker. Previous works use either X-Vector or SincNet Filters or some modifications, however we introduce a novel fusion architecture wherein we have combined both the techniques to gather more information about the speech signal hence, giving us better results. Our method focuses on the VoxCeleb1 dataset for speaker recognition, and we have used it for both training and testing purposes.
A non-extensive entropy feature and its application to texture classification
Mar 08, 2016



This paper proposes a new probabilistic non-extensive entropy feature for texture characterization, based on a Gaussian information measure. The highlights of the new entropy are that it is bounded by finite limits and that it is non additive in nature. The non additive property of the proposed entropy makes it useful for the representation of information content in the non-extensive systems containing some degree of regularity or correlation. The effectiveness of the proposed entropy in representing the correlated random variables is demonstrated by applying it for the texture classification problem since textures found in nature are random and at the same time contain some degree of correlation or regularity at some scale. The gray level co-occurrence probabilities (GLCP) are used for computing the entropy function. The experimental results indicate high degree of the classification accuracy. The performance of the new entropy function is found superior to other forms of entropy such as Shannon, Renyi, Tsallis and Pal and Pal entropies on comparison. Using the feature based polar interaction maps (FBIM) the proposed entropy is shown to be the best measure among the entropies compared for representing the correlated textures.