 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataScribe: An AI-Native, Policy-Aligned Web Platform for Multi-Objective Materials Design and Discovery
Jan 12, 2026The acceleration of materials discovery requires digital platforms that go beyond data repositories to embed learning, optimization, and decision-making directly into research workflows. We introduce DataScribe, an AI-native, cloud-based materials discovery platform that unifies heterogeneous experimental and computational data through ontology-backed ingestion and machine-actionable knowledge graphs. The platform integrates FAIR-compliant metadata capture, schema and unit harmonization, uncertainty-aware surrogate modeling, and native multi-objective multi-fidelity Bayesian optimization, enabling closed-loop propose-measure-learn workflows across experimental and computational pipelines. DataScribe functions as an application-layer intelligence stack, coupling data governance, optimization, and explainability rather than treating them as downstream add-ons. We validate the platform through case studies in electrochemical materials and high-entropy alloys, demonstrating end-to-end data fusion, real-time optimization, and reproducible exploration of multi-objective trade spaces. By embedding optimization engines, machine learning, and unified access to public and private scientific data directly within the data infrastructure, and by supporting open, free use for academic and non-profit researchers, DataScribe functions as a general-purpose application-layer backbone for laboratories of any scale, including self-driving laboratories and geographically distributed materials acceleration platforms, with built-in support for performance, sustainability, and supply-chain-aware objectives.
EZ-VC: Easy Zero-shot Any-to-Any Voice Conversion
May 22, 2025Voice Conversion research in recent times has increasingly focused on improving the zero-shot capabilities of existing methods. Despite remarkable advancements, current architectures still tend to struggle in zero-shot cross-lingual settings. They are also often unable to generalize for speakers of unseen languages and accents. In this paper, we adopt a simple yet effective approach that combines discrete speech representations from self-supervised models with a non-autoregressive Diffusion-Transformer based conditional flow matching speech decoder. We show that this architecture allows us to train a voice-conversion model in a purely textless, self-supervised fashion. Our technique works without requiring multiple encoders to disentangle speech features. Our model also manages to excel in zero-shot cross-lingual settings even for unseen languages.
Automated Classification of Cybercrime Complaints using Transformer-based Language Models for Hinglish Texts
Dec 21, 2024The rise in cybercrime and the complexity of multilingual and code-mixed complaints present significant challenges for law enforcement and cybersecurity agencies. These organizations need automated, scalable methods to identify crime types, enabling efficient processing and prioritization of large complaint volumes. Manual triaging is inefficient, and traditional machine learning methods fail to capture the semantic and contextual nuances of textual cybercrime complaints. Moreover, the lack of publicly available datasets and privacy concerns hinder the research to present robust solutions. To address these challenges, we propose a framework for automated cybercrime complaint classification. The framework leverages Hinglish-adapted transformers, such as HingBERT and HingRoBERTa, to handle code-mixed inputs effectively. We employ the real-world dataset provided by Indian Cybercrime Coordination Centre (I4C) during CyberGuard AI Hackathon 2024. We employ GenAI open source model-based data augmentation method to address class imbalance. We also employ privacy-aware preprocessing to ensure compliance with ethical standards while maintaining data integrity. Our solution achieves significant performance improvements, with HingRoBERTa attaining an accuracy of 74.41% and an F1-score of 71.49%. We also develop ready-to-use tool by integrating Django REST backend with a modern frontend. The developed tool is scalable and ready for real-world deployment in platforms like the National Cyber Crime Reporting Portal. This work bridges critical gaps in cybercrime complaint management, offering a scalable, privacy-conscious, and adaptable solution for modern cybersecurity challenges.
Speaker Recognition using SincNet and X-Vector Fusion
Apr 05, 2020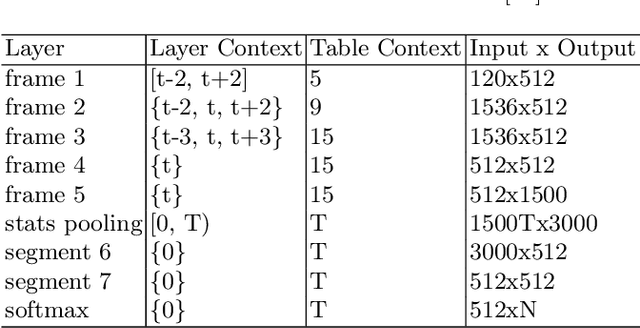
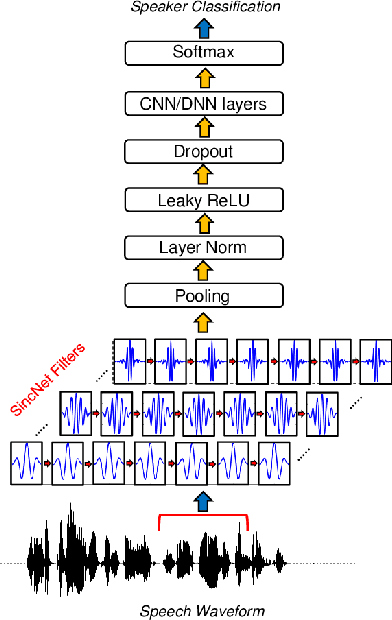
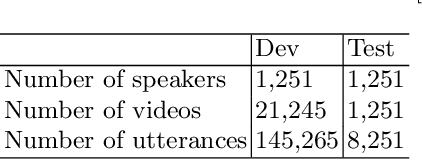
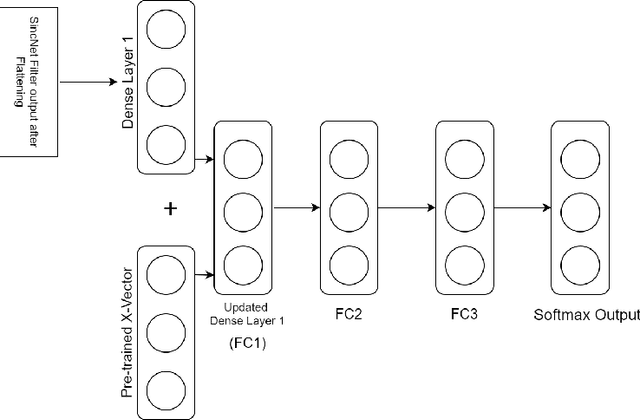
In this paper, we propose an innovative approach to perform speaker recognition by fusing two recently introduced deep neural networks (DNNs) namely - SincNet and X-Vector. The idea behind using SincNet filters on the raw speech waveform is to extract more distinguishing frequency-related features in the initial convolution layers of the CNN architecture. X-Vectors are used to take advantage of the fact that this embedding is an efficient method to churn out fixed dimension features from variable length speech utterances, something which is challenging in plain CNN techniques, making it efficient both in terms of speed and accuracy. Our approach uses the best of both worlds by combining X-vector in the later layers while using SincNet filters in the initial layers of our deep model. This approach allows the network to learn better embedding and converge quicker. Previous works use either X-Vector or SincNet Filters or some modifications, however we introduce a novel fusion architecture wherein we have combined both the techniques to gather more information about the speech signal hence, giving us better results. Our method focuses on the VoxCeleb1 dataset for speaker recognition, and we have used it for both training and testing purposes.