 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Relation Extraction via Data Augmentation and Consistency-training
Jun 16, 2023



Due to the semantic complexity of the Relation extraction (RE) task, obtaining high-quality human labelled data is an expensive and noisy process. To improve the sample efficiency of the models, semi-supervised learning (SSL) methods aim to leverage unlabelled data in addition to learning from limited labelled data points. Recently, strong data augmentation combined with consistency-based semi-supervised learning methods have advanced the state of the art in several SSL tasks. However, adapting these methods to the RE task has been challenging due to the difficulty of data augmentation for RE. In this work, we leverage the recent advances in controlled text generation to perform high quality data augmentation for the RE task. We further introduce small but significant changes to model architecture that allows for generation of more training data by interpolating different data points in their latent space. These data augmentations along with consistency training result in very competitive results for semi-supervised relation extraction on four benchmark datasets.
* Previously published at INTERPOLATE @ NeurIPS 2022 workshop
Off-Policy Policy Gradient Algorithms by Constraining the State Distribution Shift
Dec 01, 2019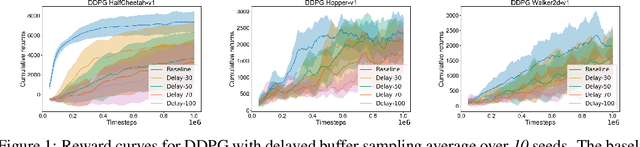
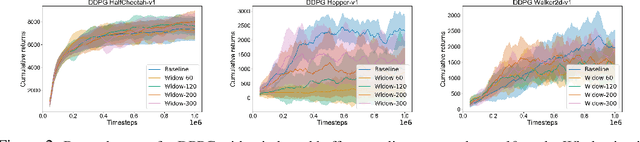
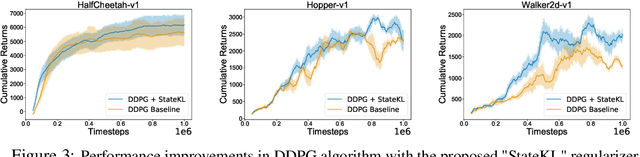
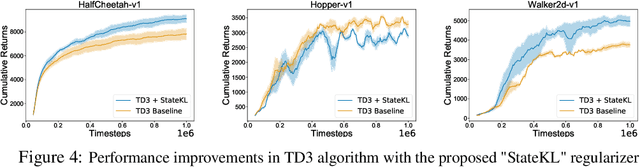
Off-policy deep reinforcement learning (RL) algorithms are incapable of learning solely from batch offline data without online interactions with the environment, due to the phenomenon known as \textit{extrapolation error}. This is often due to past data available in the replay buffer that may be quite different from the data distribution under the current policy. We argue that most off-policy learning methods fundamentally suffer from a \textit{state distribution shift} due to the mismatch between the state visitation distribution of the data collected by the behavior and target policies. This data distribution shift between current and past samples can significantly impact the performance of most modern off-policy based policy optimization algorithms. In this work, we first do a systematic analysis of state distribution mismatch in off-policy learning, and then develop a novel off-policy policy optimization method to constraint the state distribution shift. To do this, we first estimate the state distribution based on features of the state, using a density estimator and then develop a novel constrained off-policy gradient objective that minimizes the state distribution shift. Our experimental results on continuous control tasks show that minimizing this distribution mismatch can significantly improve performance in most popular practical off-policy policy gradient algorithms.
Inductive Relation Prediction on Knowledge Graphs
Nov 16, 2019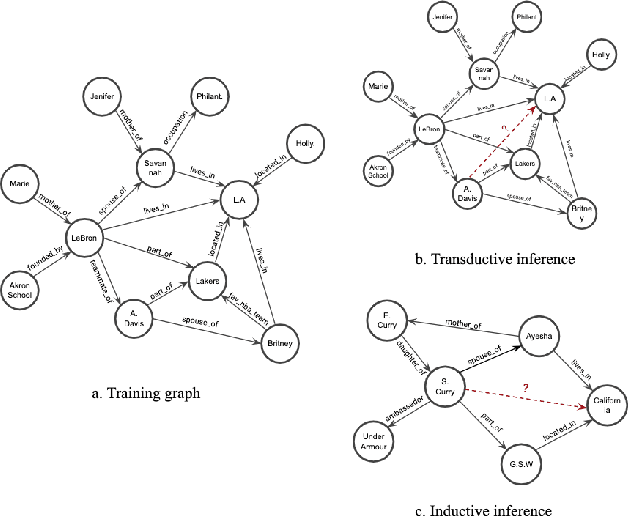

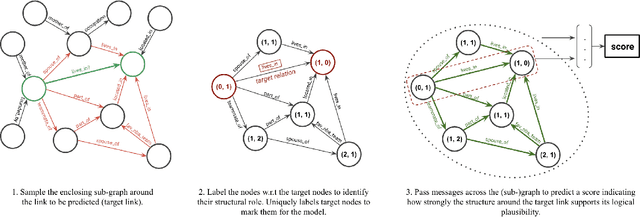

Inferring missing edges in multi-relational knowledge graphs is a fundamental task in statistical relational learning. However, previous work has largely focused on the transductive relation prediction problem, where missing edges must be predicted for a single, fixed graph. In contrast, many real-world situations require relation prediction on dynamic or previously unseen knowledge graphs (e.g., for question answering, dialogue, or e-commerce applications). Here, we develop a novel graph neural network (GNN) architecture to perform inductive relation prediction and provide a systematic comparison between this GNN approach and a strong, rule-based baseline. Our results highlight the significant difficulty of inductive relational learning, compared to the transductive case, and offer a new challenging set of inductive benchmarks for knowledge graph completion.
Towards Reducing Bias in Gender Classification
Nov 16, 2019



Societal bias towards certain communities is a big problem that affects a lot of machine learning systems. This work aims at addressing the racial bias present in many modern gender recognition systems. We learn race invariant representations of human faces with an adversarially trained autoencoder model. We show that such representations help us achieve less biased performance in gender classification. We use variance in classification accuracy across different races as a surrogate for the racial bias of the model and achieve a drop of over 40% in variance with race invariant representations.