 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Scientific Summaries: An Extractive and Abstractive Approach
Jul 29, 2024



The availability of a vast array of research papers in any area of study, necessitates the need of automated summarisation systems that can present the key research conducted and their corresponding findings. Scientific paper summarisation is a challenging task for various reasons including token length limits in modern transformer models and corresponding memory and compute requirements for long text. A significant amount of work has been conducted in this area, with approaches that modify the attention mechanisms of existing transformer models and others that utilise discourse information to capture long range dependencies in research papers. In this paper, we propose a hybrid methodology for research paper summarisation which incorporates an extractive and abstractive approach. We use the extractive approach to capture the key findings of research, and pair it with the introduction of the paper which captures the motivation for research. We use two models based on unsupervised learning for the extraction stage and two transformer language models, resulting in four combinations for our hybrid approach. The performances of the models are evaluated on three metrics and we present our findings in this paper. We find that using certain combinations of hyper parameters, it is possible for automated summarisation systems to exceed the abstractiveness of summaries written by humans. Finally, we state our future scope of research in extending this methodology to summarisation of generalised long documents.
Exploring Answer Information Methods for Question Generation with Transformers
Dec 06, 2023There has been a lot of work in question generation where different methods to provide target answers as input, have been employed. This experimentation has been mostly carried out for RNN based models. We use three different methods and their combinations for incorporating answer information and explore their effect on several automatic evaluation metrics. The methods that are used are answer prompting, using a custom product method using answer embeddings and encoder outputs, choosing sentences from the input paragraph that have answer related information, and using a separate cross-attention attention block in the decoder which attends to the answer. We observe that answer prompting without any additional modes obtains the best scores across rouge, meteor scores. Additionally, we use a custom metric to calculate how many of the generated questions have the same answer, as the answer which is used to generate them.
SPINE: Soft Piecewise Interpretable Neural Equations
Nov 20, 2021
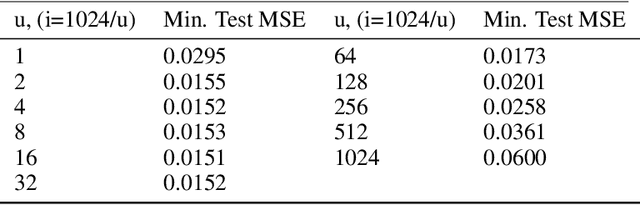
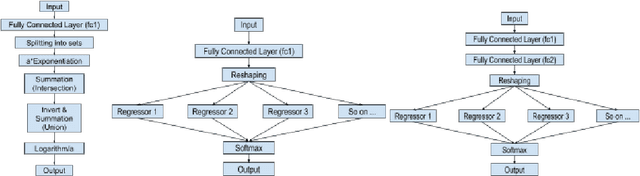

Relu Fully Connected Networks are ubiquitous but uninterpretable because they fit piecewise linear functions emerging from multi-layered structures and complex interactions of model weights. This paper takes a novel approach to piecewise fits by using set operations on individual pieces(parts). This is done by approximating canonical normal forms and using the resultant as a model. This gives special advantages like (a)strong correspondence of parameters to pieces of the fit function(High Interpretability); (b)ability to fit any combination of continuous functions as pieces of the piecewise function(Ease of Design); (c)ability to add new non-linearities in a targeted region of the domain(Targeted Learning); (d)simplicity of an equation which avoids layering. It can also be expressed in the general max-min representation of piecewise linear functions which gives theoretical ease and credibility. This architecture is tested on simulated regression and classification tasks and benchmark datasets including UCI datasets, MNIST, FMNIST, and CIFAR 10. This performance is on par with fully connected architectures. It can find a variety of applications where fully connected layers must be replaced by interpretable layers.
Using Deep learning methods for generation of a personalized list of shuffled songs
Dec 17, 2017
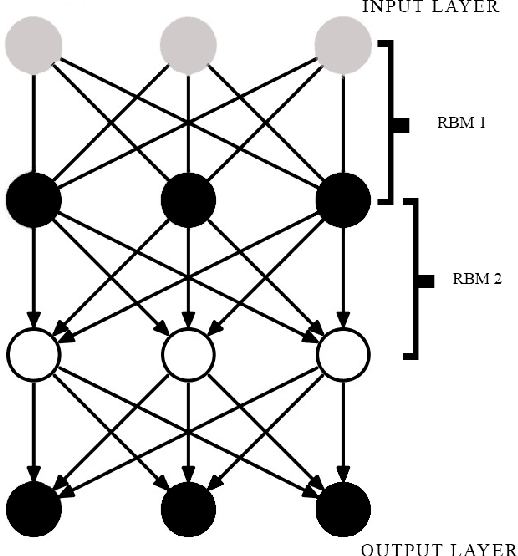
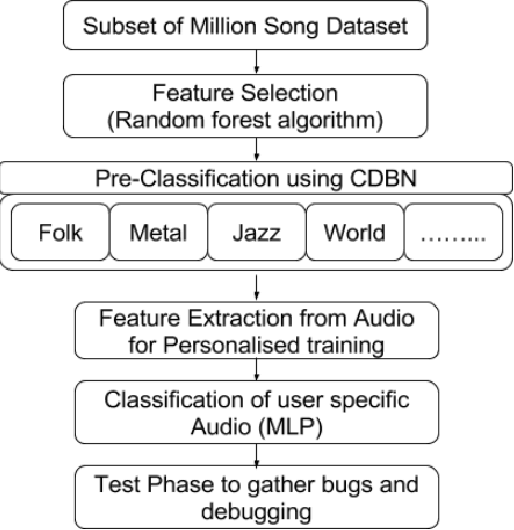
The shuffle mode, where songs are played in a randomized order that is decided upon for all tracks at once, is widely found and known to exist in music player systems. There are only few music enthusiasts who use this mode since it either is too random to suit their mood or it keeps on repeating the same list every time. In this paper, we propose to build a convolutional deep belief network(CDBN) that is trained to perform genre recognition based on audio features retrieved from the records of the Million Song Dataset. The learned parameters shall be used to initialize a multi-layer perceptron which takes extracted features of user's playlist as input alongside the metadata to classify to various categories. These categories will be shuffled retrospectively based on the metadata to autonomously provide with a list that is efficacious in playing songs that are desired by humans in normal conditions.