 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWADER at SemEval-2023 Task 9: A Weak-labelling framework for Data augmentation in tExt Regression Tasks
Mar 05, 2023


Intimacy is an essential element of human relationships and language is a crucial means of conveying it. Textual intimacy analysis can reveal social norms in different contexts and serve as a benchmark for testing computational models' ability to understand social information. In this paper, we propose a novel weak-labeling strategy for data augmentation in text regression tasks called WADER. WADER uses data augmentation to address the problems of data imbalance and data scarcity and provides a method for data augmentation in cross-lingual, zero-shot tasks. We benchmark the performance of State-of-the-Art pre-trained multilingual language models using WADER and analyze the use of sampling techniques to mitigate bias in data and optimally select augmentation candidates. Our results show that WADER outperforms the baseline model and provides a direction for mitigating data imbalance and scarcity in text regression tasks.
Recommending Researchers in Machine Learning based on Author-Topic Model
Sep 05, 2021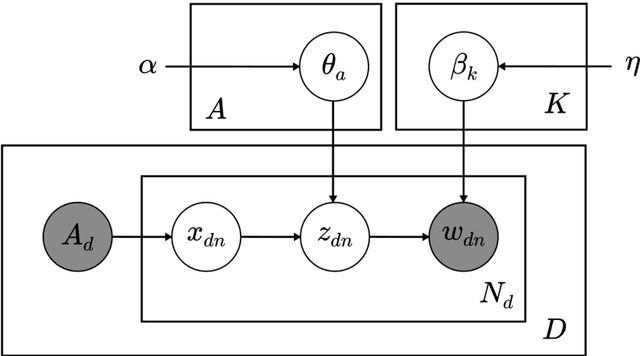
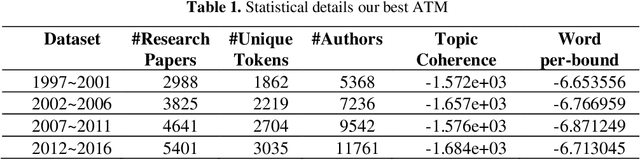
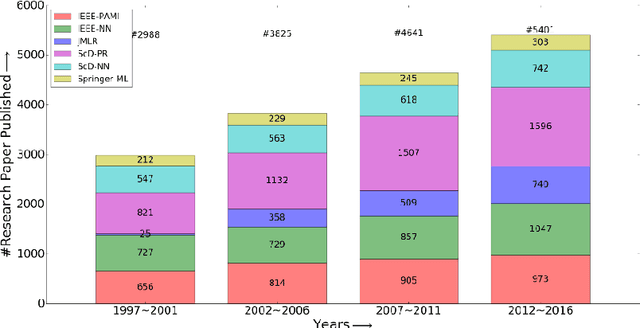
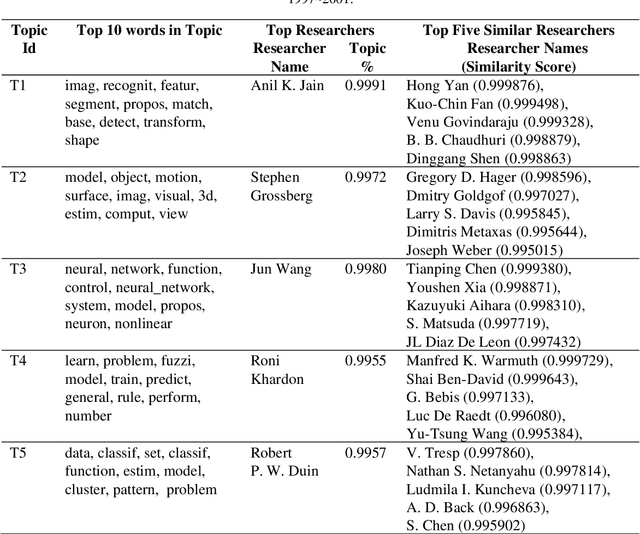
The aim of this paper is to uncover the researchers in machine learning using the author-topic model (ATM). We collect 16,855 scientific papers from six top journals in the field of machine learning published from 1997 to 2016 and analyze them using ATM. The dataset is broken down into 4 intervals to identify the top researchers and find similar researchers using their similarity score. The similarity score is calculated using Hellinger distance. The researchers are plotted using t-SNE, which reduces the dimensionality of the data while keeping the same distance between the points. The analysis of our study helps the upcoming researchers to find the top researchers in their area of interest.