 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWADER at SemEval-2023 Task 9: A Weak-labelling framework for Data augmentation in tExt Regression Tasks
Mar 05, 2023


Intimacy is an essential element of human relationships and language is a crucial means of conveying it. Textual intimacy analysis can reveal social norms in different contexts and serve as a benchmark for testing computational models' ability to understand social information. In this paper, we propose a novel weak-labeling strategy for data augmentation in text regression tasks called WADER. WADER uses data augmentation to address the problems of data imbalance and data scarcity and provides a method for data augmentation in cross-lingual, zero-shot tasks. We benchmark the performance of State-of-the-Art pre-trained multilingual language models using WADER and analyze the use of sampling techniques to mitigate bias in data and optimally select augmentation candidates. Our results show that WADER outperforms the baseline model and provides a direction for mitigating data imbalance and scarcity in text regression tasks.
Engineering an Intelligent Essay Scoring and Feedback System: An Experience Report
Mar 25, 2021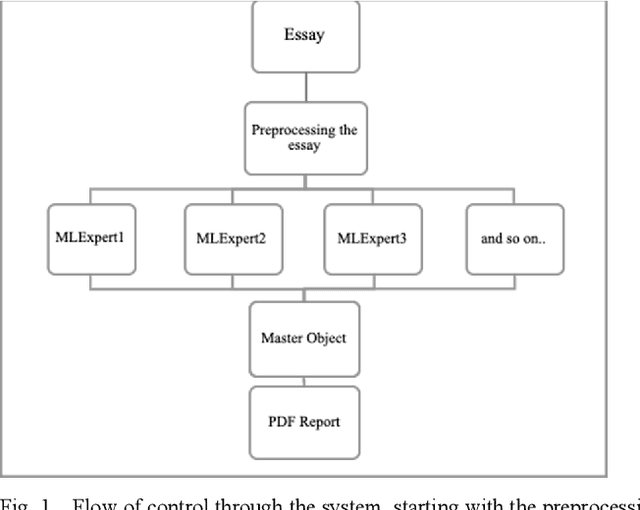
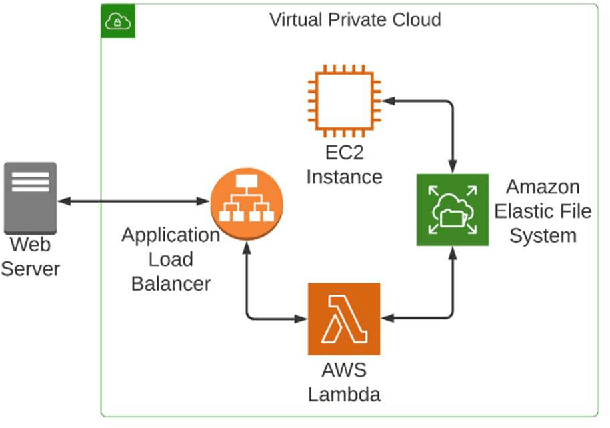
Artificial Intelligence (AI) / Machine Learning (ML)-based systems are widely sought-after commercial solutions that can automate and augment core business services. Intelligent systems can improve the quality of services offered and support scalability through automation. In this paper we describe our experience in engineering an exploratory system for assessing the quality of essays supplied by customers of a specialized recruitment support service. The problem domain is challenging because the open-ended customer-supplied source text has considerable scope for ambiguity and error, making models for analysis hard to build. There is also a need to incorporate specialized business domain knowledge into the intelligent processing systems. To address these challenges, we experimented with and exploited a number of cloud-based machine learning models and composed them into an application-specific processing pipeline. This design allows for modification of the underlying algorithms as more data and improved techniques become available. We describe our design, and the main challenges we faced, namely keeping a check on the quality control of the models, testing the software and deploying the computationally expensive ML models on the cloud.